【论文笔记】Multi-Agent Based Character Simulation for Story Writing
论文信息
论文标题: Multi-Agent Based Character Simulation for Story Writing - In2Writing 2025
论文作者: Tian Yu, Ken Shi, Zixin Zhao, Gerald Penn
论文链接: https://aclanthology.org/2025.in2writing-1.9/
论文领域: 故事生成,多智能体系统,角色模拟
研究背景
近年来,大型语言模型(LLMs)在文本连贯性和流畅性方面取得了显著进展,研究者们开始将LLMs应用于自动故事生成和人机协作写作任务。传统的故事生成方法通常包含两个阶段:规划阶段(sequencing events)和生成阶段(elaborating events into scenes)。然而,现有的LLM生成故事仍存在诸多问题,如缺乏趣味性(由于线性叙事结构)、角色不一致、逻辑矛盾等问题,论文通过分析 Dramatron 和 Agents Room 两篇经典论文总结问题为以下三点:
- 如何在保持叙事连贯性的同时,生成更具趣味性和非线性结构的故事?
- 如何有效模拟故事中角色的行为,使其更加真实可信?
- 如何将故事生成过程模块化,以便更好地与人类作家协作?
创新点
论文提出的解决方案可总结为以下四点创新:
- 角色模拟策略:首次将fabula和syuzhet概念整合到一个统一的故事生成过程中
- 两阶段生成框架:将故事生成分解为角色扮演(role-play)和重写(rewrite)两个步骤
- 多智能体协作机制:引入导演智能体和角色智能体,实现更真实的角色模拟
- 人机协作设计:系统设计考虑了人类作家可以作为独立智能体参与角色扮演过程
核心思想与方法论
该系统借鉴了叙事理论中的“故事时间”(syuzhet)和“事件时间”(fabula)概念 。
- 事件时间 (Fabula): 指事件发生的原始、按时间顺序排列的序列,是故事世界的底层叙事 。在论文的框架中,角色扮演步骤负责构建这个“事件时间” 。
- 故事时间 (Syuzhet): 指故事最终呈现给读者的顺序,可以是非线性的,以增强戏剧效果和观众参与度 。重写步骤则将角色扮演的中间结果重塑为最终的“故事时间”形式 。
该方法包含以下两个主要步骤:
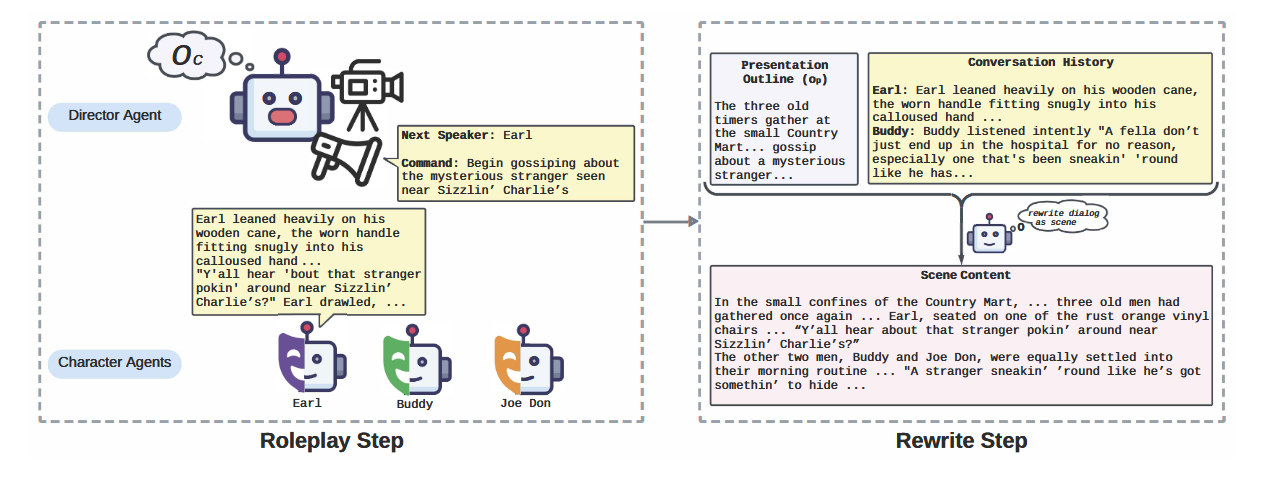
角色扮演步骤 (Role-playing Step)
-
目的: 模拟故事的“事件时间”(fabula),即事件的严格时间顺序 。
-
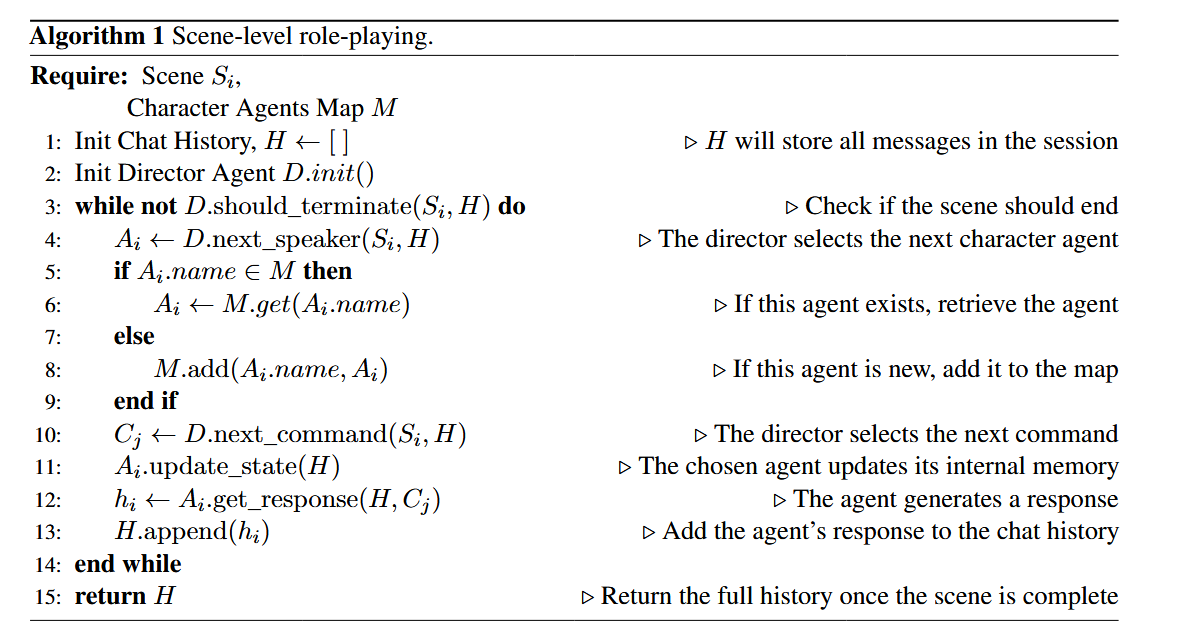
工作流程:
- 系统首先接收一个包含场景列表的输入计划 PpP_pPp,该计划指定了故事的呈现顺序(故事时间,syuzhet)。
- 利用一个基于 LLM 的排序算法,将 PpP_pPp 中的场景重新排列成严格按时间顺序排列的角色扮演计划 PcP_cPc。类似地,场景内部的事件大纲 opo_pop 也会被重新排序成时间大纲 oco_coc
- 系统定义了两种智能体:
- 导演智能体 (Director Agent):负责控制场景的发展,选择下一个发言的角色智能体,并向其发出行动指令 (command) 。
- 角色智能体 (Character Agent):根据其目标、身体状态和记忆,对导演的指令做出回应,并以第三人称视角描述对话和行动
- 角色扮演过程类似于一个“群聊”管理,导演智能体根据时间大纲 oco_coc 引导角色智能体进行模拟,直到场景结束。
- 角色智能体拥有一个基于文本的记忆和身体状态系统,可以根据新的聊天历史进行更新,以保持一致性 。
重写步骤 (Rewrite Step)
- 目的: 将角色扮演的输出(事件时间)精炼成符合原始计划呈现顺序(故事时间)的最终故事文本 。
- 工作流程:
- 重写算法依次处理原始输入计划 PpP_pPp 中指定的每个场景,并按照其呈现顺序生成内容 。
- 系统提示 LLM,根据原始的呈现大纲 opo_pop 撰写场景内容,并参考角色扮演步骤中生成的对话和行动模拟结果 。
- 这种模块化的方法允许作者在生成下一个场景之前对当前场景的内容进行修改 。
实验与评估
数据集与设置
- 数据集: 使用了名为“Tell Me A Story”的数据集,该数据集包含复杂的写作提示和人工撰写的故事 。作者通过 UMAP 和 k-means 聚类方法对数据集进行了分析,并选择了 28 个代表性提示进行实验 。
- 对比方法:
- 单一智能体方法:Dramatron 。
- 多智能体方法:Agents’ Room 。
- 实验流程:
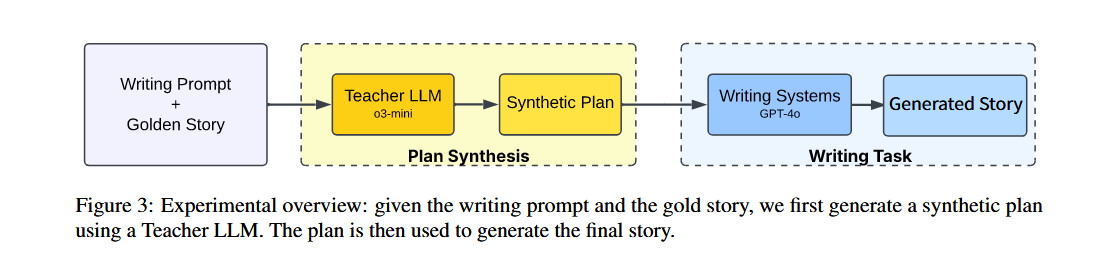
- 通过一个“教师 LLM”(03-mini)从“黄金故事”中合成一个“合成计划”,然后将该计划作为输入,让三种写作系统(Dramatron、Agents’ Room 和本论文提出的系统)生成故事 。
- 所有系统均使用 GPT-4o 模型,并采用零样本(zero-shot)提示策略,以确保公平比较 。
评估方法
- 自动评估: 采用基于 LLM 的评估器,灵感来自 Agents’ Room 的评估方法 。采用两篇文章选择其中一篇的方式,实现通过设定 prompt 让 LLM 进行选择,如下图所示。
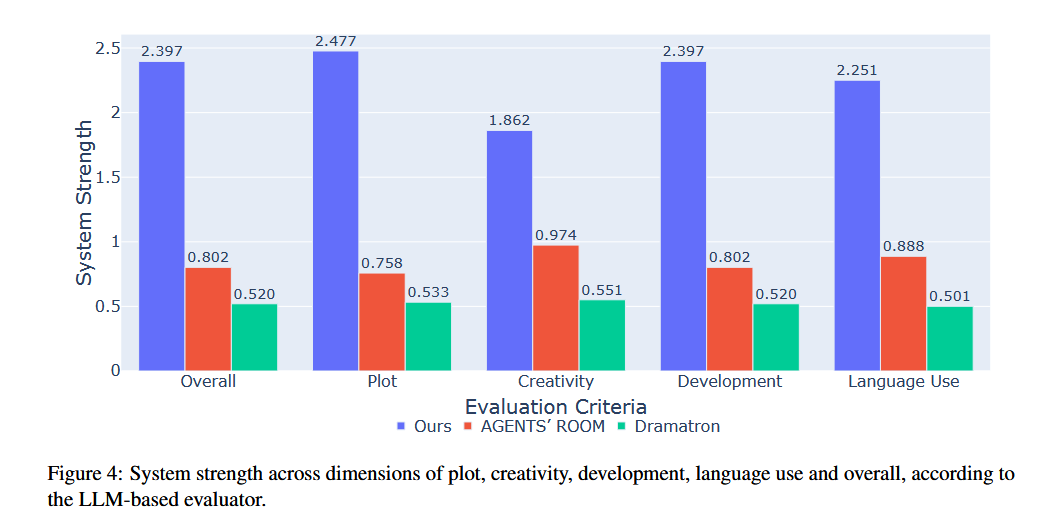
- 评估标准: 评估器根据四个标准对故事进行两两比较:情节(Plot)、创意(Creativity)、发展(Development)和语言使用(Language Use)。同时还包括一个单独的“总体”(Overall)标准 。
- 评估模型: 使用 Gemini 1.5 Pro 作为评估模型 。
- 结果分析: 使用 Bradley-Terry 模型将两两比较结果线性化,得到各系统的潜在能力参数(strength)。

实验结果
- LLM 评估结果: 在所有评估标准(总体、情节、创意、发展和语言使用)上,作者提出的系统都显著优于 Agents’ Room 和 Dramatron 。
- 定性分析:
- 作者的系统在角色一致性和叙事连贯性方面表现更好 。
- 通过一个具体的例子(train 026),论文解释了其优势:由于采用了时间顺序的角色扮演,角色智能体(Aerie)在扮演第一个场景(与 Kissen 会面)之前已经有了第二个场景(回顾早期旅程)的记忆,从而避免了其他系统可能出现的幻觉或过早剧透问题 。
- 其他方法存在问题,例如 Agents’ Room 可能会出现重复或无关的词语,这可能是因为其生成过程约束较弱 。
结论
- 结论: 该论文首次将“事件时间”和“故事时间”的概念整合到一个统一的故事生成流程中 。通过角色扮演步骤生成“事件时间”,再通过重写步骤将其修改为“故事时间”,实现了作者意图和角色驱动对话之间的自然平衡 。这种方法利用角色模拟结果,大大降低了实际故事内容创作的难度 。
- 未来工作:
- 改进排序算法,以更好地处理包含闪回等复杂时间结构的场景 。
- 在角色扮演过程中实施明确的隐私控制,以防止智能体访问其不应获取的信息 。
- 探索将人类参与者更有效地整合到创作流程中的方法 。