tensorrt-llm0.20.0:Prometheus3.5.0通过间接采集,进行性能指标分析
在阅读本章之前,建议您先看看我之前的两篇博客,有助于更好地理解后续内容。
大模型性能指标的监控系统(prometheus3.5.0)和可视化工具(grafana12.1.0)基础篇
FastDeploy2.0:Prometheus3.5.0通过直接采集,进行性能指标分析
一、部署json_exporter
1.1下载
下载地址《json_exporter》
#tar xvfz json_exporter-0.7.0.linux-amd64.tar.gz
cd json_exporter-0.7.0.linux-amd64/
1.2编辑config.yml
#vi config.yml
# json_exporter 配置文件:config.yml
modules:
inference_metrics:
metrics:
# --- KV Cache: Missed Blocks ---
- name: trtllm_kv_cache_missed_blocks
type: object
path: "{[-1]}"
condition: "{?(@.kvCacheStats != null && @.kvCacheStats.missedBlocks >= 0)}" # 确保字段存在
help: "缓存未命中导致需重新计算的 block 数"
values:
value: "{.kvCacheStats.missedBlocks}"
- name: trtllm_kv_cache_reused_blocks
type: object
path: "{[-1]}"
condition: "{?(@.kvCacheStats != null && @.kvCacheStats.reusedBlocks >= 0)}" # 确保字段存在
help: "被重复利用的缓存块数"
values:
value: "{.kvCacheStats.reusedBlocks}"
- name: trtllm_kv_cache_cache_hit_rate
type: object
path: "{[-1]}"
condition: "{?(@.kvCacheStats != null && @.kvCacheStats.cacheHitRate >= 0)}" # 确保字段存在
help: "缓存命中率"
values:
value: "{.kvCacheStats.cacheHitRate}"
# --- Inflight Batching: Avg Decoded Tokens ---
- name: trtllm_inflight_batching_avg_decoded_tokens
type: object
path: "{[-1]}"
condition: "{.kvCacheStats.avgNumDecodedTokensPerIter} >= 0" # 确保字段存在
help: "平均每个请求在此迭代中生成的 token 数"
values:
value: "{.inflightBatchingStats.avgNumDecodedTokensPerIter}"
# --- GPU Memory Usage ---
# 采集 GPU 显存使用量(单位:字节)
- name: trtllm_inference_gpu_mem_usage_bytes
type: object
path: "{ [-1] }"
help: "GPU显存使用量(单位:字节)"
values:
value: "{ .gpuMemUsage }"# --- Iter Latency ---
# 采集单次迭代延迟(毫秒)
- name: trtllm_inference_iter_latency_ms
type: object
path: "{ [-1] }"
help: "单次迭代延迟(毫秒)"
values:
value: "{ .iterLatencyMS }"# --- Number of Active Requests ---
# 采集当前活跃请求数
- name: trtllm_inference_num_active_requests
type: object
path: "{ [-1] }"
help: "当前活跃的请求数"
values:
value: "{ .numActiveRequests }"# --- Number of Completed Requests ---
# 采集已完成请求数
- name: trtllm_inference_num_completed_requests
type: object
path: "{ [-1] }"
help: "已完成的请求数"
values:
value: "{ .numCompletedRequests }"# --- Number of Queued Requests ---
# 采集排队中的请求数
- name: trtllm_inference_num_queued_requests
type: object
path: "{ [-1] }"
help: "排队中的请求数"
values:
value: "{ .numQueuedRequests }"
# 新激活的请求数
- name: trtllm_inference_num_new_active_requests
type: object
path: "{ [-1] }"
help: "新激活的请求数"
values:
value: "{ .numNewActiveRequests }"
# --- CPU Memory Usage ---
# 采集 CPU 内存使用量(字节)
- name: trtllm_inference_cpu_mem_usage_bytes
type: object
path: "{ [-1] }" # 取整个数组的最后一个元素
help: "CPU内存使用量(单位:字节)"
values:
value: "{ .cpuMemUsage }"# --- Pinned Memory Usage ---
# 采集 pinned 内存使用量(字节)
- name: trtllm_inference_pinned_mem_usage_bytes
type: object
path: "{ [-1] }" # 取整个数组的最后一个元素
help: "Pinned内存使用量(单位:字节)"
values:
value: "{ .pinnedMemUsage }"# --- Max Batch Size Runtime ---
# 采集运行时最大 batch size
- name: trtllm_inference_max_batch_size_runtime
type: object
path: "{ [-1] }"
help: "运行时最大 batch size"
values:
value: "{ .maxBatchSizeRuntime }"# --- Max Num Active Requests ---
# 采集最大活跃请求数
- name: trtllm_inference_max_num_active_requests
type: object
path: "{ [-1] }"
help: "最大活跃请求数"
values:
value: "{ .maxNumActiveRequests }"
# --- Max Num Tokens Runtime ---
# 采集运行时最大 token 数
- name: trtllm_inference_max_num_tokens_runtime
type: object
path: "{ [-1] }"
help: "运行时最大 token 数"
values:
value: "{ .maxNumTokensRuntime }"
1.3启动json_exporter
nohup ./json_exporter --config.file=conf.yml --log.level=debug --web.listen-address=:7979 > json_exporter.log 2>&1 &
1.4测试验证
curl "http://192.168.1.204:7979/probe?target=http://192.168.1.154:9401/metrics&module=inference_metrics"
二、修改prometheus.yml
2.1进入容器里面
docker exec -it prometheus /bin/sh
2.2增加数据来源
- job_name: 'trtllm_metrics_via_json_exporter'
metrics_path: /probe
params:
module: [inference_metrics]
static_configs:
- targets: ['192.168.1.204:7979']
labels:
__param_target: http://192.168.1.154:9401/metrics
relabel_configs:
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.1.204:7979
2.3 手动启动
方法一:使用 promtool 工具
promtool check config /etc/prometheus/prometheus.yml
方法二:使用 Prometheus 的 Web 接口发送一个 HTTP POST 请求到 /targets/-/reload 来重新加载配置,(需要启用-web.enable-lifecycle标志)
curl -X POST http://192.168.1.204:9090/-/reload
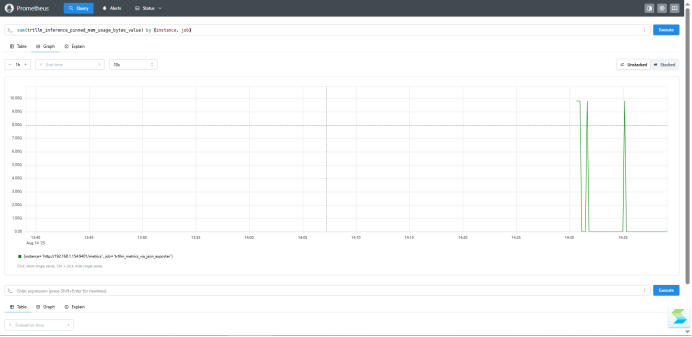
2.4呈现效果
sum(trtllm_inference_pinned_mem_usage_bytes_value) by (instance, job)
三、性能指标说明
3.1推理请求状态与统计
"numActiveRequests":1
中文:当前活跃的请求数
解释:当前正在处理中的推理请求数量。这里是 1 个。
"numCompletedRequests":1
中文:已完成的请求数
解释:从服务启动或统计重置以来,已成功完成的推理请求数量。
"numNewActiveRequests":1
中文:新激活的请求数
解释:在当前迭代(iter)中新增并开始处理的请求数量。
"numQueuedRequests":0
中文:排队中的请求数
解释:尚未被调度处理、正在等待资源的请求数量。0 表示当前无排队。
"newActiveRequestsQueueLatencyMS":0.480024
中文:新请求进入活跃状态的排队延迟(毫秒)
解释:新请求从提交到被调度执行所经历的平均等待时间,约为 0.48 毫秒,说明响应非常及时。
3.2迭代与延迟
"iter":18345
中文:迭代次数
解释:推理引擎已完成的处理迭代总数(通常每个迭代处理一批 token)。
"iterLatencyMS":31.874071
中文:单次迭代延迟(毫秒)
解释:最近一次迭代的执行耗时为约 31.87 毫秒,反映模型生成一个 token 的速度。
3.3批处理与调度统计
"inflightBatchingStats":{...}
中文:飞行中批处理统计(动态批处理信息)
解释:实时批处理调度的关键指标。
"numContextRequests":1
上下文阶段请求数:正在进行预填充(context encoding)的请求数(通常是新请求的第一步)。
"numGenRequests":0
生成阶段请求数:正在进行自回归生成(token 生成)的请求数。
"numScheduledRequests":1
本次调度的请求数:当前迭代中被调度执行的总请求数。
"numCtxTokens":1
上下文 token 数:本次处理的上下文 token 数量(可能是 prompt 的第一个 token)。
"numPausedRequests":0
暂停中的请求数:因资源不足或批处理策略而暂时挂起的请求数。
"avgNumDecodedTokensPerIter":0.0
每迭代平均解码 token 数:平均每个请求在此迭代中生成的 token 数,0.0 表示当前主要是上下文处理。
"microBatchId":0
微批次 ID:用于标识当前处理的小批次编号。
3.4KV Cache(键值缓存)使用情况(影响 LLM 推理效率的核心)
"kvCacheStats":{...}
中文:KV 缓存状态统计
解释:Transformer 模型在生成文本时缓存历史 key/value 以避免重复计算。
"usedNumBlocks":4
已使用的缓存块数量。
"freeNumBlocks":3619
空闲的缓存块数量。
"maxNumBlocks":3623
总缓存块数量上限。
"allocTotalBlocks":2371
累计分配过的缓存块总数。
"allocNewBlocks":2371
新分配的缓存块数(与 allocTotalBlocks 相同,说明尚未复用旧块)。
"reusedBlocks":2489
被重复利用的缓存块数(可能跨请求复用)。
"missedBlocks":1133
缓存未命中导致需重新计算的 block 数。
"cacheHitRate":0.6871894001960754
缓存命中率 ≈ 68.7%:越高越好,说明大部分历史计算被有效复用,减少重复计算开销。
"tokensPerBlock":32
每个缓存块可存储的 token 数。
3.5批大小与最大容量配置
"maxBatchSizeStatic":2048
中文:静态配置的最大批大小
解释:在模型配置文件中设定的理论最大批处理请求数。
"maxBatchSizeRuntime":128
中文:运行时实际支持的最大批大小
解释:由于显存或其他资源限制,实际能处理的最大请求数,远小于静态值,说明资源受限。
"maxBatchSizeTunerRecommended":128
中文:自动调优器推荐的最大批大小
解释:性能调优工具建议使用的批大小,与运行时一致,说明当前设置较优。
"maxNumTokensStatic":8192
静态配置的最大 token 总数(批内所有请求 token 数之和)。
"maxNumTokensRuntime":8192
实际运行时允许的最大总 token 数。
"maxNumTokensTunerRecommended":0
调优器未推荐 token 限制(可能未启用或无需调整)。
3.6资源使用情况
"cpuMemUsage":93324
中文:CPU 内存使用量(单位:KB)
解释:约 93.3 MB 的 CPU 内存被使用。
"gpuMemUsage":24485677219
中文:GPU 显存使用量(单位:字节)
解释:约 24.49 GB 的 GPU 显存被使用(≈ 24.5 GB),接近高端 GPU(如 A100 40GB 或 H100)容量。
"pinnedMemUsage":9828616192
中文:锁定内存(Pinned Memory)使用量(字节)
解释:约 9.15 GB 的主机内存被设为“锁定”,用于高速 CPU-GPU 数据传输,提升吞吐。