MySQL的《Buffer-pool》和《连接池》介绍
目录
1、Buffer Pool(缓冲池)
1.1、主要特点
1.2、位置
1.3、内部结构
1.4、Buffer Pool 工作流程
1.5、配置参数
1.6、性能监控
2、连接池(Connection Pool)
2.1、介绍
2.2、使用原因
2.3、连接池实现:
2.4、主要特点
2.5、重要参数
2.6、注意点
3、对比联系
前言
当日常开发过程中,一个sql的请求从应用程序发送,会经过一个完整的mysql的内部结构,包括权限认证、server端、存储引擎端,磁盘等;
更多详细介绍,可参考:Mysql中select查询语句的执行过程_select语句执行过程-CSDN博客![]() https://dyclt.blog.csdn.net/article/details/148472938?spm=1011.2415.3001.5331
https://dyclt.blog.csdn.net/article/details/148472938?spm=1011.2415.3001.5331
如下所示:
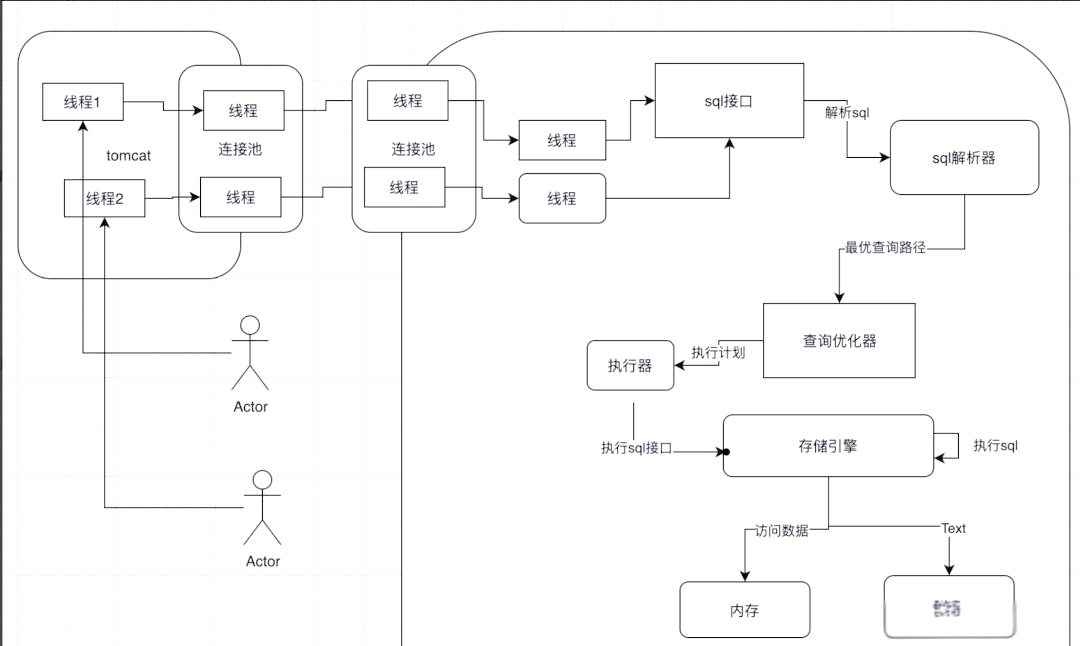
1、Buffer Pool(缓冲池)
buffer-pool的读写机制如下:
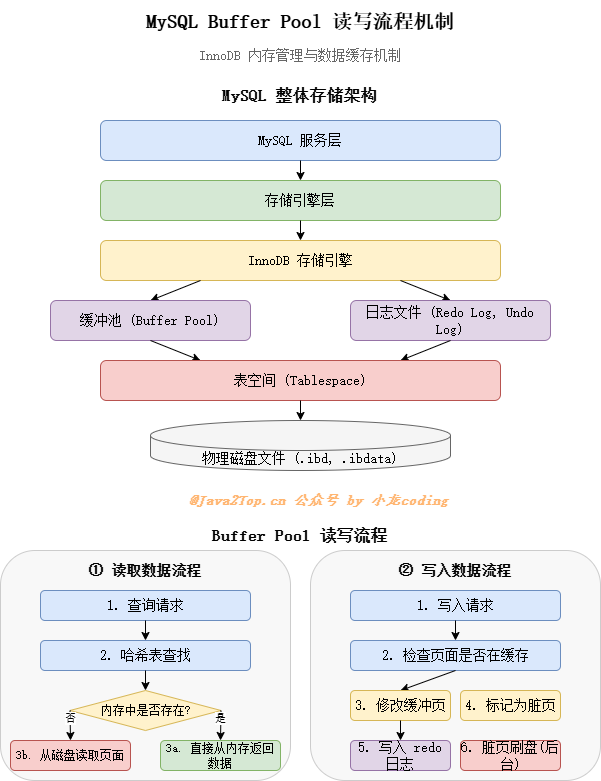
Buffer Pool是InnoDB在内存中开辟的一个区域,主要用于缓存表数据和索引数据。当InnoDB需要访问数据时,首先会检查Buffer Pool中是否已缓存该数据,避免直接磁盘I/O。
如下图所示:
1.1、主要特点
默认大小为128MB,如下所示:
-
内存缓存:将磁盘上的数据页缓存在内存中,减少磁盘I/O
-
LRU算法管理:使用改进的LRU(最近最少使用)算法管理数据页
-
读写优化:
-
读取数据时先检查Buffer Pool
-
修改数据时先在Buffer Pool中完成,再异步刷回磁盘
-
-
多实例:MySQL 5.7+支持多个Buffer Pool实例,减少争用
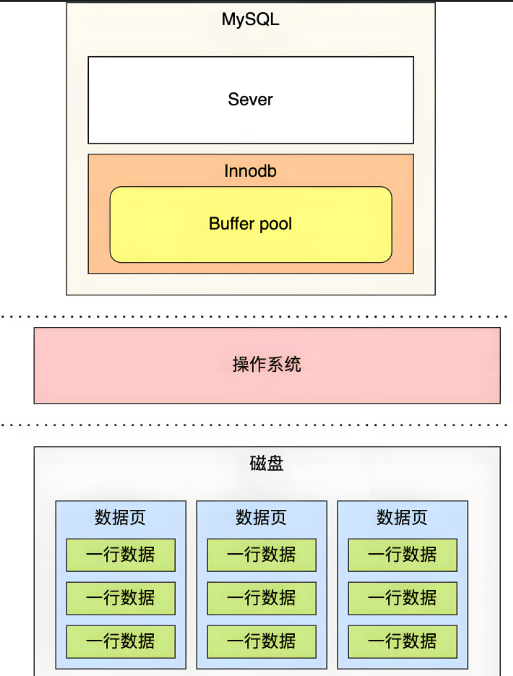
1.2、位置
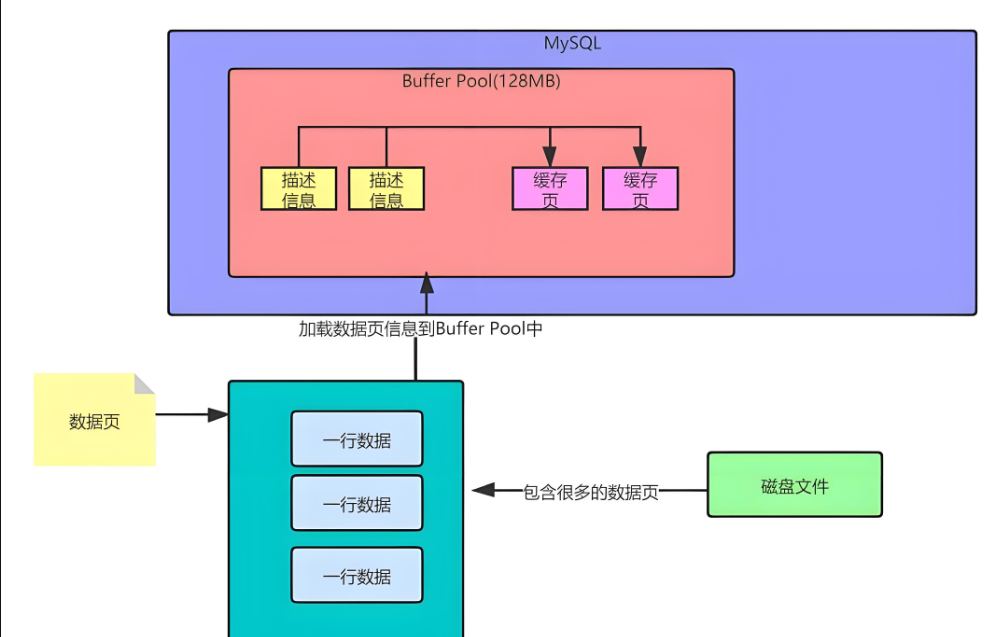
Buffer-pool位于innodb存储引擎,和操作系统和磁盘区进行交互。
当mysql的server服务端发送请求的时候,会先进行Buffer-pool的读取,如果buffer-pool没有,再去磁盘文件里面查询。
如下所示:
-
减少磁盘I/O:将频繁访问的数据保留在内存中
-
写缓冲:先将修改操作在内存中完成,再异步刷盘
-
加速查询:热数据可以直接从内存读取
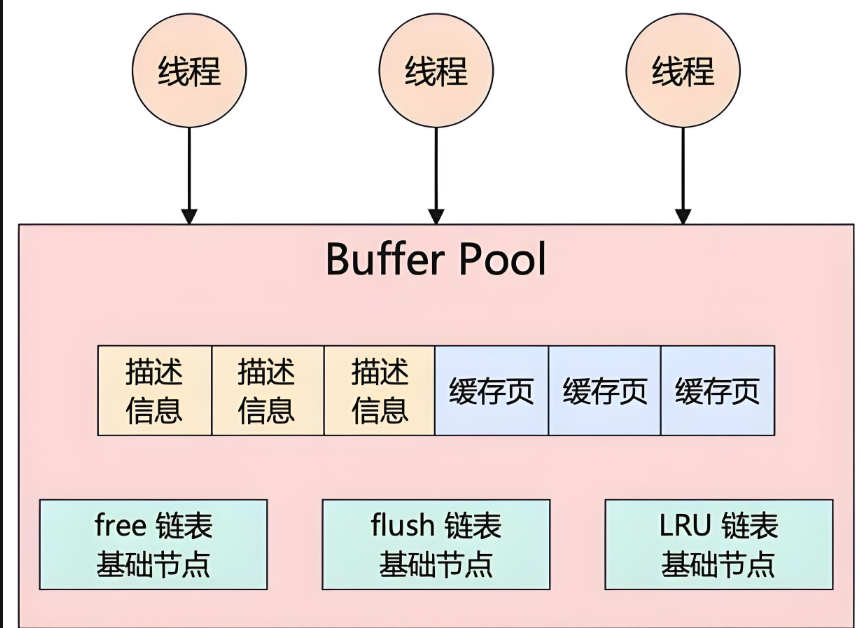
1.3、内部结构
如下所示:
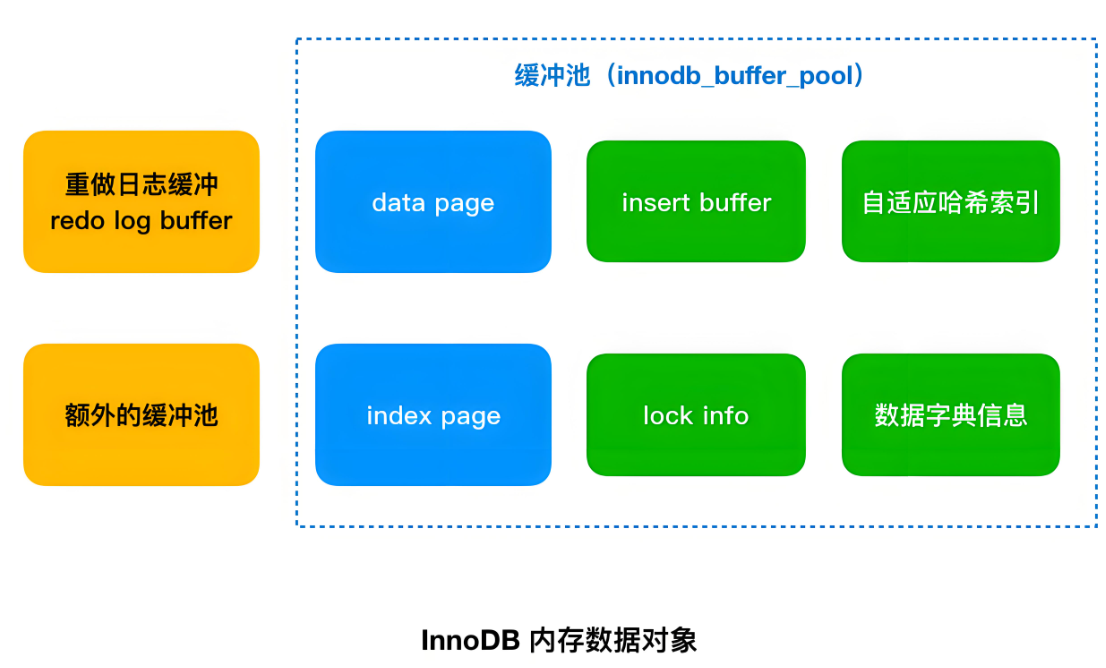
1. 数据页组织
Buffer Pool由多个页(frame)组成,每个页默认16KB(与磁盘数据页大小一致)。
包含:
1、表数据页;
2、索引页;
3、插入缓冲(Change Buffer);
特殊的数据结构,缓存对非唯一二级索引的修改:
-
当相关页不在Buffer Pool时,先记录到Change Buffer
-
当页被加载到Buffer Pool时合并修改
-
显著提升写性能,特别是随机插入场景
4、自适应哈希索引;
自动为频繁访问的页构建哈希索引:
-
完全自动管理,无需配置
-
加速等值查询(如WHERE primary_key = xxx)
5、锁信息等。
2. 页管理机制
采用改进的LRU(最近最少使用)算法管理。
分为两个子列表:
New Sublist(新/年轻区块):存放最近访问的页
Old Sublist(老区块):存放较久未被访问的页
LRU链表示意图:
[New Sublist] -> [最近访问的页1]->[页2]->...->[midpoint]->...->[页N]->[Old Sublist]1.4、Buffer Pool 工作流程
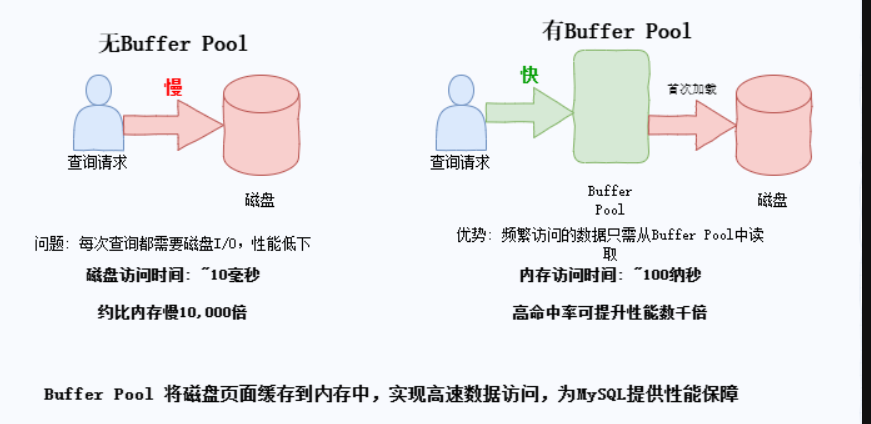
1. 数据读取流程
查询发生时,先检查Buffer Pool;
命中则直接返回数据(逻辑读);
未命中则从磁盘加载数据页到Buffer Pool(物理读);
新页插入到LRU列表的midpoint位置(老区块头部);
2. 数据修改流程
修改Buffer Pool中的页(变为脏页);
后台线程定期将脏页刷盘(checkpoint机制);
刷盘后该页变为干净页;
3. 预读机制
-
线性预读:检测顺序访问模式,提前加载后续页;
-
随机预读:检测同一extent中的页是否被连续访问(5.7+默认禁用);
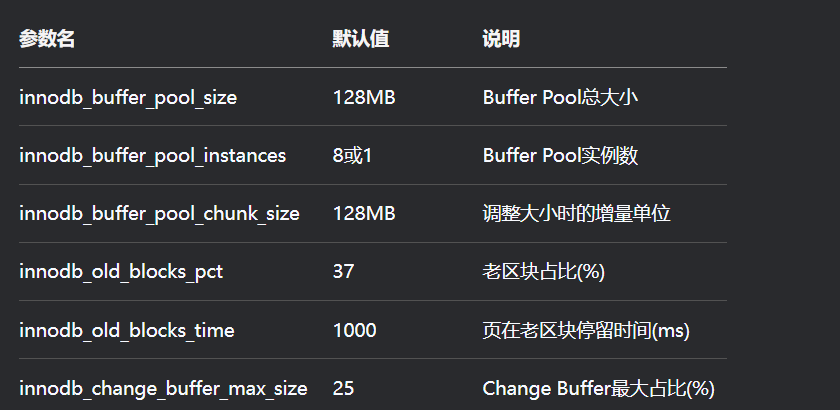
1.5、配置参数
如下所示:
1.6、性能监控
1. 重要状态变量
SHOW STATUS LIKE 'Innodb_buffer_pool%';关键指标:
-
Innodb_buffer_pool_read_requests:逻辑读请求数。
-
Innodb_buffer_pool_reads:物理读次数(未命中数)。
-
Innodb_buffer_pool_wait_free:等待空闲页的次数。
2. 命中率计算
命中率 = 1 - (Innodb_buffer_pool_reads / Innodb_buffer_pool_read_requests)建议保持在98%以上。
小结:
Buffer Pool的优化需要结合具体业务特点和服务器资源进行权衡,过大可能导致OOM,过小则影响性能。
2、连接池(Connection Pool)
2.1、介绍
连接池是管理和复用数据库连接的技术,应用程序需要连接时从池中获取,使用完毕后归还而非直接关闭,减少频繁创建和关闭连接的开销。
如下所示:
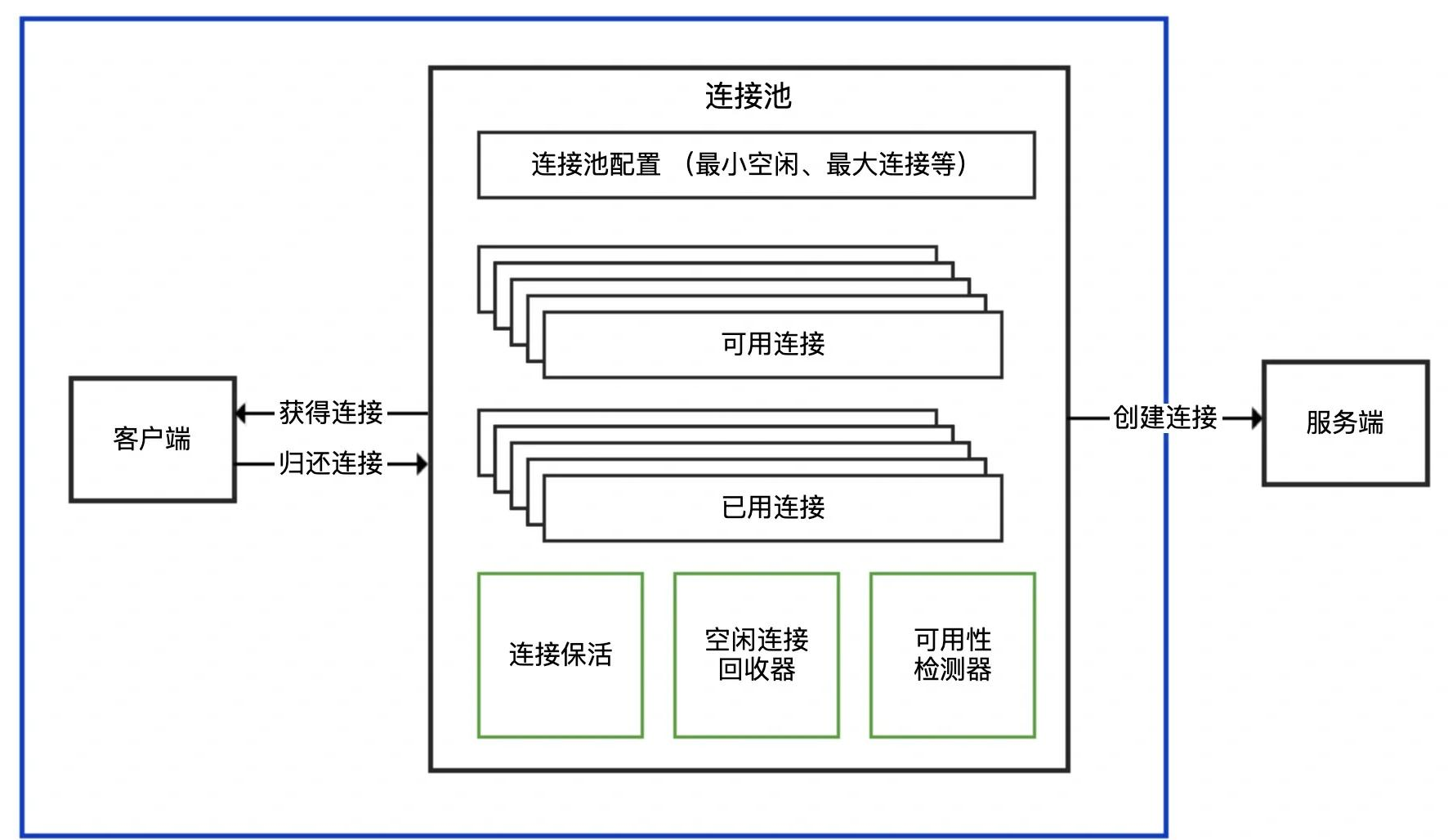
2.2、使用原因
-
创建连接开销大:每次新建连接需要TCP三次握手、MySQL权限验证等(约100-300ms);
-
资源消耗高:每个连接占用约3-25MB内存(取决于配置);
-
并发控制:防止连接数暴增导致数据库过载;
2.3、连接池实现:
1、MySQL服务端连接配置
1. 关键系统变量
SHOW VARIABLES LIKE '%connection%';
SHOW VARIABLES LIKE '%timeout%';重要参数:
-
max_connections:最大连接数(默认151) -
wait_timeout:非交互连接空闲超时(默认28800秒) -
interactive_timeout:交互连接空闲超时(默认28800秒) -
max_user_connections:单用户最大连接数
2. 连接状态监控
SHOW STATUS LIKE 'Threads%';关键指标:
-
Threads_connected:当前连接数 -
Threads_running:活跃连接数 -
Threads_created:历史创建总数
代码示例如下:
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");
config.setUsername("user");
config.setPassword("password");
config.setMaximumPoolSize(20);
config.setMinimumIdle(5);
config.setConnectionTimeout(3000);
config.setIdleTimeout(600000);
config.setMaxLifetime(1800000);
config.setConnectionTestQuery("SELECT 1");
HikariDataSource ds = new HikariDataSource(config);2.4、主要特点
-
连接复用:避免频繁创建和销毁连接
-
连接管理:限制最大连接数,防止资源耗尽
-
健康检查:定期验证连接有效性
-
超时控制:设置获取连接和空闲连接的超时时间
2.5、重要参数
如下所示:
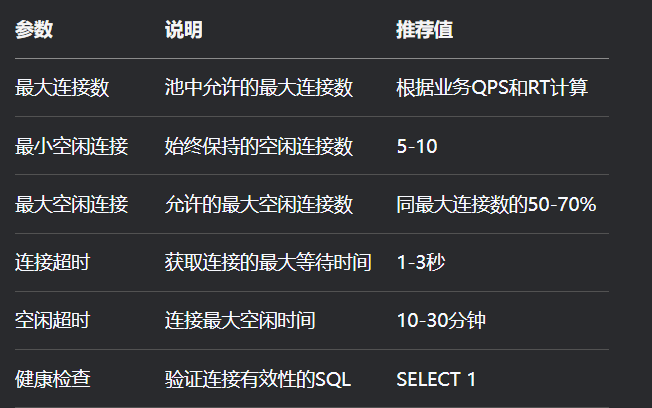
-
max_connections:MySQL允许的最大连接数 -
wait_timeout:非交互连接的空闲超时时间 -
interactive_timeout:交互连接的空闲超时时间
2.6、注意点
-
避免连接泄漏:确保finally块中归还连接
-
合理超时设置:防止雪崩效应
-
连接预热:启动时预先建立最小连接数
-
分库分表:不同业务使用独立连接池
-
监控告警:关注活跃连接数和等待线程数
3、对比联系

总结
两者都是MySQL性能优化的重要组成部分,分别针对数据访问和连接管理进行优化。两者协同工作:良好的连接池配置可以稳定并发请求量,帮助Buffer Pool保持合理的热数据集合;而高效的Buffer Pool能缩短查询时间,加速连接释放。
通过合理配置连接池和Buffer Pool,可以显著提升MySQL数据库的整体性能表现。
参考文章:
1、MySQL缓冲池(buffer pool),这次终于懂了!!!-CSDN博客![]() https://blog.csdn.net/jcc4261/article/details/148074010?ops_request_misc=%257B%2522request%255Fid%2522%253A%252207b03ecc5c346230eacbbe8a1e285ae0%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=07b03ecc5c346230eacbbe8a1e285ae0&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-148074010-null-null.142^v102^pc_search_result_base1&utm_term=bufferpool%E5%92%8C%E8%BF%9E%E6%8E%A5%E6%B1%A0&spm=1018.2226.3001.4187
https://blog.csdn.net/jcc4261/article/details/148074010?ops_request_misc=%257B%2522request%255Fid%2522%253A%252207b03ecc5c346230eacbbe8a1e285ae0%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=07b03ecc5c346230eacbbe8a1e285ae0&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-148074010-null-null.142^v102^pc_search_result_base1&utm_term=bufferpool%E5%92%8C%E8%BF%9E%E6%8E%A5%E6%B1%A0&spm=1018.2226.3001.4187