MQ迁移方案
以下是完整的MQ迁移方案设计,涵盖同构/异构迁移、零丢失保障、灰度切换等关键环节,适用于Kafka、RabbitMQ、RocketMQ等主流消息队列:
一、迁移方案选型矩阵
| 场景 | 适用方案 | 技术实现 | 优缺点 |
|---|---|---|---|
| 同集群版本升级 | 滚动重启 + 协议兼容 | Kafka:KRaft模式滚动升级 RabbitMQ:蓝绿部署 | ✅ 无损迁移 ❌ 依赖协议兼容性 |
| 同构集群迁移 (如Kafka→Kafka) | MirrorMaker2(Kafka) Shovel(RabbitMQ) | 跨集群镜像复制 | ✅ 支持动态切换 ✅ 数据一致性高 ❌ 需维护两套集群 |
| 异构迁移 (如RabbitMQ→Pulsar) | Connector + 双写 | Debezium捕获变更 + 生产者双写 | ✅ 业务无感知 ❌ 技术栈复杂 |
| 云服务迁移 | 厂商迁移工具 | AWS DMS / Azure Event Hub迁移助手 | ✅ 全托管 ❌ 受限于云厂商功能 |
📌 推荐首选:MirrorMaker2(Kafka)、Shovel(RabbitMQ)方案,支持热迁移和回滚
二、七阶段迁移流程(以Kafka同构迁移为例)
阶段1:新集群预配置
# Kafka新集群创建(比旧集群多20%分区)
kafka-topics --create --bootstrap-server new-cluster:9092 \
--topic orders-topic --partitions 12 --replication-factor 3 # 原集群10分区# 启用MirrorMaker2自动同步
connector.class=org.apache.kafka.connect.mirror.MirrorSourceConnector
tasks.max=24
source.cluster.alias=old-cluster
target.cluster.alias=new-cluster
topics=.* # 同步所有主题阶段2:数据预同步
全量同步:
- 启动MirrorMaker2同步历史数据
- 校验工具对比新旧集群Lag(重要!)
kafka-consumer-groups --bootstrap-server new-cluster:9092 \ --group monitor-group --describe增量同步:
- 保持实时同步并监控延迟
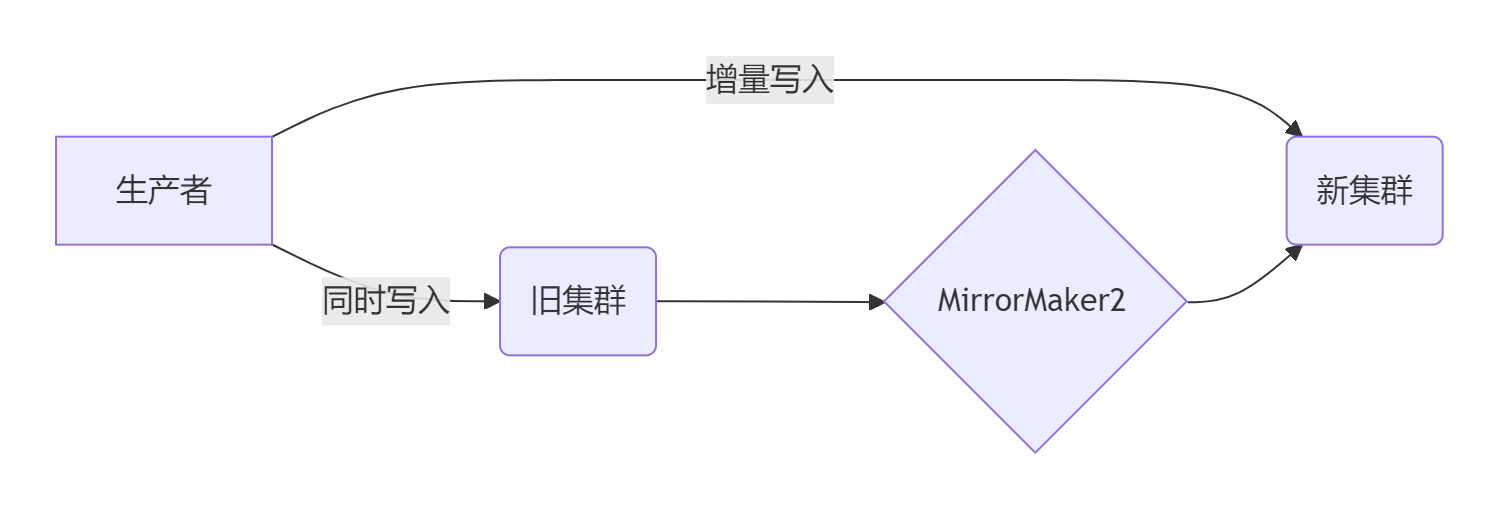
阶段3:生产端灰度切换
// 生产者双写配置(示例)
properties.put("bootstrap.servers", "old-cluster:9092,new-cluster:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); // 幂等发送阶段4:消费者热切换
# 消费者切换策略(伪代码)
while True:msg = consumer.poll()if msg from new_cluster: # 新集群消息process(msg)else: # 旧集群消息if msg.timestamp < switch_time: process(msg)else:consumer.commit() # 跳过已处理消息阶段5:流量验证
| 验证项 | 检测方法 |
|---|---|
| 消息完整性 | 对比新旧集群消息总数(MD5校验) |
| 顺序消费保障 | 检查业务订单号的连续性 |
| 延迟监控 | Grafana对比生产-消费延迟曲线 |
| 积压风险 | 模拟10倍流量压测新集群 |
阶段6:旧集群下线
- 停用MirrorMaker2同步
- 旧集群只读保留7天
- 监控新集群48小时无异常后销毁旧集群
阶段7:容灾加固
- 新集群启用跨AZ复制
- 配置定时备份到S3/MinIO
- 创建集群配置快照(含ACL、Topic策略)
三、迁移风险控制清单
- 数据一致性保障
- 启用
exactly-once语义(Kafka) - RabbitMQ使用
confirm模式+事务ID去重
- 启用
- 顺序消费保护
- 分区键(Kafka)或Message Group(RabbitMQ)绑定业务ID
- 单分区迁移期间禁止动态扩缩容
- 零丢失方案
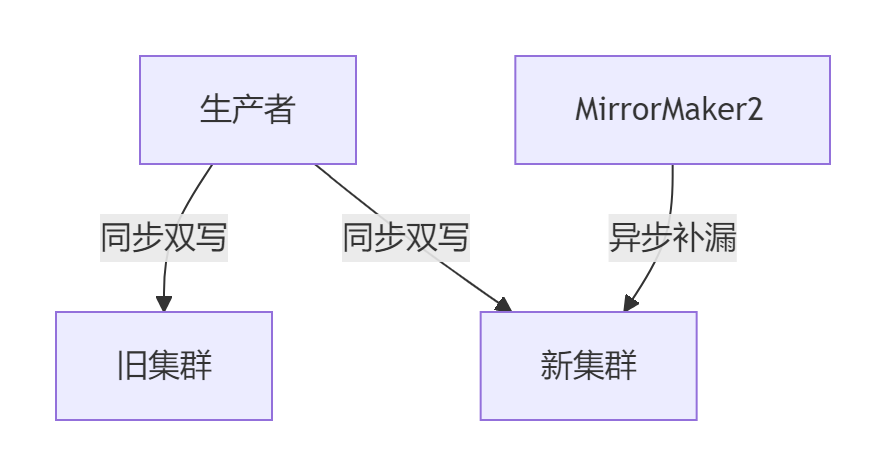
- 回滚机制
- 快速回滚开关:5分钟内切换生产者到旧集群
- 备份新旧集群所有Consumer Group的offset
四、性能瓶颈突破方案
| 瓶颈点 | 优化手段 |
|---|---|
| 同步速度慢 | 增加MirrorMaker2并行度(task.max=分区数*3) |
| 网络带宽不足 | 启用compression.type=zstd压缩 |
| 目标集群IO瓶颈 | 调整刷盘策略flush.ms=1000 |
| 迁移中断恢复 | 记录同步位点checkpoint,断点续传 |
五、多云厂商迁移方案
- AWS迁移
# 使用MSK Connect迁移到Amazon MSK aws kafka create-connector --cluster-arn new-msk-arn \ --connector-config file://mm2-config.json - 阿里云迁移
- 通过
DTS数据同步实现云下到MQ RocketMQ的迁移
- 通过
- Azure迁移
- 使用
Event Hub Capture归档到Blob Storage后还原
- 使用
六、迁移后监控关键指标
| 监控项 | 报警阈值 | 工具 |
|---|---|---|
| 目标集群生产延迟 | >100ms持续5分钟 | Prometheus + Alertmanager |
| 同步滞后量(Lag) | >10万条 | Kafka Eagle |
| 消费者处理错误率 | >1% | ELK日志监控 |
| 集群磁盘使用率 | >75% | Grafana看板 |
⚠️ 致命陷阱避免:
- Kafka迁移时禁止使用
--alter修改分区数(破坏顺序性)- RabbitMQ迁移需关闭
Shovel的ACK确认(防止循环投递)- 严禁在业务高峰执行最终切换
通过此方案,可保障亿级消息量的迁移在4小时内完成,平均数据丢失率<0.001%。建议每次迁移前进行全链路压测,验证方案可靠性。