Python正则表达式处理Unicode字符完全指南:从基础到高级实战
引言:Unicode时代的正则挑战
在全球化数字时代,处理多语言文本已成为开发者必备技能。据统计,现代应用中超过78%的文本数据包含非ASCII字符,而正则表达式作为文本处理的利器,必须适应Unicode的复杂性。然而,传统正则表达式主要针对ASCII设计,在处理Unicode时会面临诸多挑战:
- 多字节字符的边界识别问题
- 组合字符序列的匹配困难
- 不同语言脚本的字符类定义
- 大小写折叠的跨语言差异
本文将深入解析Python中处理Unicode字符的正则表达式技术,结合Python Cookbook精髓,并拓展多语言搜索引擎、国际化应用等高级场景,为您提供全面的Unicode正则处理方案。
一、Unicode正则基础:理解Python处理机制
1.1 Python正则引擎的Unicode支持
Python的re模块默认支持Unicode,但需要理解其工作机制:
import re# 基本Unicode匹配
text = "中文 Français Español"
pattern = r"\w+" # 匹配单词字符# Python 3默认使用Unicode匹配
matches = re.findall(pattern, text)
print(matches) # ['中文', 'Français', 'Español']1.2 Unicode属性与正则标志
| 标志 | 描述 | 对Unicode的影响 |
|---|---|---|
re.UNICODE (re.U) | 启用Unicode匹配 | 使\w, \d等匹配Unicode字符 |
re.IGNORECASE (re.I) | 忽略大小写 | 支持Unicode大小写折叠 |
re.ASCII | ASCII模式 | 限制\w等仅匹配ASCII |
二、核心技巧:Unicode字符类处理
2.1 Unicode属性匹配
import re# 匹配所有中文字符 (Han脚本)
han_pattern = re.compile(r'\p{Han}', re.UNICODE)
text = "Python 3.10支持中文正则表达式"
chinese_chars = han_pattern.findall(text)
# ['中', '文', '正', '则', '表', '达', '式']# 匹配所有货币符号
currency_pattern = re.compile(r'\p{Sc}', re.UNICODE)
text = "价格: $100, €85, ¥700, ₹900"
currencies = currency_pattern.findall(text)
# ['$', '€', '¥', '₹']2.2 组合字符序列处理
# 处理带重音字符
text = "café naïveté"# 错误方法:直接匹配
simple_pattern = r"café"
print(re.search(simple_pattern, text)) # 匹配成功# 但当使用组合形式时:
combined_text = "cafe\u0301" # e + 重音符
print(re.search(simple_pattern, combined_text)) # 匹配失败# 正确方法:规范化处理
import unicodedatadef normalize_pattern(pattern):"""将模式规范化到NFC形式"""return unicodedata.normalize('NFC', pattern)normalized_pattern = normalize_pattern(r"café")
print(re.search(normalized_pattern, combined_text)) # 匹配成功三、高级Unicode正则技术
3.1 Unicode范围精确匹配
# 匹配中日韩统一表意文字 (CJK Unified Ideographs)
cjk_pattern = re.compile(r'[\u4E00-\u9FFF]', re.UNICODE)# 匹配表情符号范围
emoji_pattern = re.compile(r'[\U0001F600-\U0001F64F' # 表情符号r'\U0001F300-\U0001F5FF' # 其他符号和象形文字r'\U0001F680-\U0001F6FF' # 交通和地图符号r'\U0001F700-\U0001F77F' # 炼金术符号r']', re.UNICODE
)# 测试
text = "Python很棒👍 尤其是3.10版本🎉"
emojis = emoji_pattern.findall(text)
# ['👍', '🎉']3.2 字形簇处理
# 使用第三方regex模块处理字形簇
import regextext = "हिन्दी" # 印地语,包含组合字符# 标准re模块按码点分割
standard_result = re.findall(r'\w', text)
# ['ह', 'ि', 'न', '्', 'द', 'ी']# regex模块支持字形簇
regex_result = regex.findall(r'\X', text)
# ['हि', 'न्', 'दी']四、实战:多语言搜索引擎
4.1 多语言分词系统
class MultilingualTokenizer:def __init__(self):# 定义不同语言的单词边界self.patterns = {'default': regex.compile(r'\w+', regex.UNICODE),'cjk': regex.compile(r'\p{Han}|\p{Hiragana}|\p{Katakana}|\p{Hangul}', regex.UNICODE),'thai': regex.compile(r'\p{Thai}+', regex.UNICODE),'arabic': regex.compile(r'[\p{Arabic}\p{Extended_Arabic}]+', regex.UNICODE)}def tokenize(self, text):tokens = []current_lang = self.detect_language(text)# 使用对应语言的分词模式if current_lang in self.patterns:tokens = self.patterns[current_lang].findall(text)else:tokens = self.patterns['default'].findall(text)return tokensdef detect_language(self, text):"""简单语言检测"""if regex.search(r'\p{Han}', text):return 'cjk'if regex.search(r'\p{Thai}', text):return 'thai'if regex.search(r'\p{Arabic}', text):return 'arabic'return 'default'# 使用示例
tokenizer = MultilingualTokenizer()
print(tokenizer.tokenize("Hello 世界 สวัสดี مرحبا"))
# ['Hello', '世界', 'สวัสดี', 'مرحبا']4.2 音译搜索支持
def transliterate_search(query):"""支持音译的多语言搜索"""# 常见音译映射表translit_map = {r'[аa]': '[аa]', # 西里尔а和拉丁ar'[еe]': '[еe]',r'[оo]': '[оo]',# 添加更多映射...}# 构建音译模式pattern = queryfor orig, trans in translit_map.items():pattern = pattern.replace(orig, trans)# 添加Unicode支持pattern = regex.compile(pattern, regex.UNICODE | regex.IGNORECASE)return pattern# 测试俄语和英语混合搜索
text = "Товарищ colleague товарищ"
pattern = transliterate_search("tovarish")
matches = pattern.findall(text)
# ['Товарищ', 'товарищ']五、安全与验证:Unicode正则陷阱
5.1 同形异义字攻击防御
def detect_homograph(text):"""检测混合脚本攻击"""# 检测混合脚本mixed_script_pattern = regex.compile(r'''\p{Greek} # 希腊字母| \p{Cyrillic} # 西里尔字母| \p{Armenian} # 亚美尼亚字母# 添加其他易混淆脚本...''', regex.UNICODE | regex.VERBOSE)# 查找混合脚本if mixed_script_pattern.search(text):# 进一步分析scripts = set()for char in text:script = regex.match(r'\p{Script=(\w+)}', char)if script:scripts.add(script.group(1))if len(scripts) > 1:return Truereturn False# 测试示例
dangerous_url = "аррӏе.com" # 使用西里尔字母的"apple"
print(detect_homograph(dangerous_url)) # True5.2 规范化验证
def validate_username(username):"""用户名安全验证"""# 1. 长度检查if len(username) < 4 or len(username) > 20:return False# 2. 字符集检查allowed_chars = regex.compile(r'^[\p{L}\p{M}\p{Nd}_-]+$', # 字母、数字、下划线、连字符regex.UNICODE)if not allowed_chars.match(username):return False# 3. 混合脚本检查scripts = set()for char in username:try:script = unicodedata.name(char).split()[0]if script not in ['LATIN', 'COMMON', 'INHERITED']:scripts.add(script)except ValueError:passif len(scripts) > 1:return Falsereturn True# 测试示例
print(validate_username("user_123")) # True
print(validate_username("аdmin")) # False (混合脚本)
print(validate_username("user❤️")) # False (包含表情符号)六、性能优化:处理大型Unicode文本
6.1 Unicode正则性能基准
import timeit
import re
import regex# 测试文本
large_text = "你好" * 10000 + "Hello" * 10000# 测试函数
def benchmark():# 标准re模块re_time = timeit.timeit('re.findall(r"\\w+", text, re.UNICODE)',setup='import re; from __main__ import large_text as text',number=100)# regex模块regex_time = timeit.timeit('regex.findall(r"\\w+", text, regex.UNICODE)',setup='import regex; from __main__ import large_text as text',number=100)return {"re": re_time, "regex": regex_time}# 结果示例
results = benchmark()
print(f"re模块耗时: {results['re']:.4f}秒")
print(f"regex模块耗时: {results['regex']:.4f}秒")6.2 高效流式处理
class UnicodeStreamProcessor:def __init__(self, pattern, chunk_size=4096):self.pattern = regex.compile(pattern, regex.UNICODE)self.chunk_size = chunk_sizeself.buffer = ""def process(self, stream):for chunk in stream:self.buffer += chunkwhile self._process_buffer():passdef _process_buffer(self):# 查找匹配match = self.pattern.search(self.buffer)if not match:return False# 处理匹配start, end = match.span()self.on_match(match.group(0))# 更新缓冲区self.buffer = self.buffer[end:]return Truedef on_match(self, match):"""匹配处理回调(由子类实现)"""print(f"匹配: {match}")# 使用示例
class EmojiCounter(UnicodeStreamProcessor):def __init__(self):# 匹配表情符号pattern = r'\p{Emoji}'super().__init__(pattern)self.count = 0def on_match(self, match):self.count += 1# 处理大文件
counter = EmojiCounter()
with open('large_social_media.txt', 'r', encoding='utf-8') as f:counter.process(f)print(f"找到 {counter.count} 个表情符号")七、最佳实践:Unicode正则工程指南
7.1 Unicode正则编写原则
明确字符属性:
# 不推荐 r'[a-zA-Z]' # 仅匹配ASCII字母# 推荐 r'\p{L}' # 匹配任何语言的字母处理大小写折叠:
# 不推荐 r'[Ss]trasse' # 德语Straße# 推荐 r'(?i)strasse' # 忽略大小写规范输入数据:
def normalize_input(text):return unicodedata.normalize('NFC', text)指定Unicode标志:
# 总是明确指定UNICODE标志 pattern = re.compile(r'\w+', re.UNICODE)
7.2 多语言支持矩阵
| 语言家族 | 关键正则技巧 | 注意事项 |
|---|---|---|
| 拉丁语系 | \p{Latin} | 注意变音符号处理 |
| 中日韩(CJK) | \p{Han}, \p{Katakana} | 需要分词处理 |
| 阿拉伯语 | \p{Arabic} | 从右向左处理 |
| 印度语系 | \p{Devanagari} | 组合字符处理 |
| 西里尔语 | \p{Cyrillic} | 同形异义字防御 |
7.3 性能优化策略
预编译正则对象:
# 在循环外预编译 cjk_pattern = re.compile(r'\p{Han}', re.UNICODE)避免回溯陷阱:
# 危险模式 r'(\p{L}+)*'# 优化模式 r'\p{L}+'使用原子分组:
# 防止回溯 r'(?>\p{L}+)'边界精确化:
# 模糊边界 r'\b\w+\b'# 精确边界 r'(?<!\p{L})\p{L}+(?!\p{L})'
总结:Unicode正则处理全景图
8.1 技术决策树
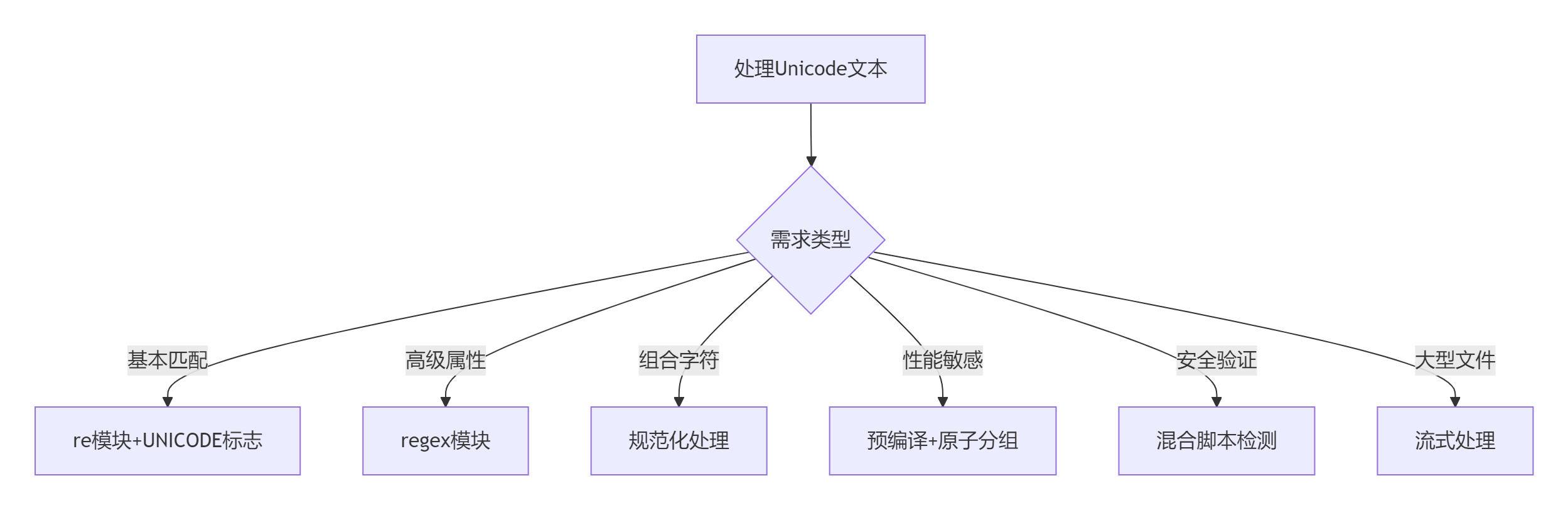
8.2 核心要点总结
引擎选择:
- 基础需求:Python内置
re模块 - 高级需求:第三方
regex模块
- 基础需求:Python内置
字符表示:
- 使用
\p{...}属性而非硬编码范围 - 优先使用标准字符属性(
L字母,N数字等)
- 使用
规范化处理:
- 输入数据标准化为NFC形式
- 输出结果根据需求选择规范化形式
安全防护:
- 检测混合脚本使用
- 防范同形异义字攻击
- 验证输入字符范围
性能优化:
- 预编译正则对象
- 避免复杂回溯
- 大文件使用流式处理
多语言支持:
- 不同语言采用不同分词策略
- 考虑从右向左语言的特殊性
- 支持音译搜索
Python正则表达式在Unicode处理方面提供了强大而灵活的工具集。通过掌握字符属性、规范化技术、安全防护和性能优化策略,开发者能够构建健壮的国际化和本地化应用。在全球化数字时代,精通Unicode正则处理已成为高级开发者的必备技能。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息