C++面试——内存
一、简述堆和栈的区别
| 维度 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 生命周期 | 随函数调用自动创建/销毁 | 由程序员或垃圾回收器控制 |
| 分配速度 | 极快(仅移动指针) | 慢(需查找空闲块、维护元数据) |
| 空间大小 | 较小(通常 MB 级) | 较大(受系统内存限制) |
| 连续性 | 连续内存,自上而下生长 | 非连续,易产生碎片 |
| 典型用途 | 局部变量、函数参数 | 动态数组、对象、大内存 |
| 线程安全 | 每个线程独立栈 | 多线程共享,需同步 |
| 示例 | int a = 10; | int *p = new int(10); |
一句话:栈像自动售货机,随拿随走;堆像仓库,按需申请、手动归还。
二、简述C++的内存管理
C++ 的内存管理可简化为 “三区域、两手段、一原则”:
-
三区域
- 栈:函数帧自动创建/销毁,速度最快。
- 堆:
new/delete或malloc/free手动申请/释放,空间大。 - 静态/全局区:编译期确定,程序运行期间一直存在。
-
两手段
- 手动管理:裸指针 +
new/delete,高效但易漏/悬垂。 - RAII + 智能指针:
std::unique_ptr、std::shared_ptr/weak_ptr把资源生命周期绑定到对象生命周期,自动释放。
- 手动管理:裸指针 +
-
一原则
资源即对象(RAII):获得资源即构造对象,离开作用域即释放资源——让编译器替你做 delete。
一句话:
用智能指针和 RAII 包装资源,告别手动 delete,把内存管理交给作用域。
三、malloc和局部变量分配在堆还是栈?
| 分配方式 | 所在区域 | 生命周期 | 示例 |
|---|---|---|---|
malloc / new | 堆(Heap) | 程序员手动 free/delete 或程序结束 | int* p = (int*)malloc(4); |
| 局部变量 | 栈(Stack) | 离开作用域自动销毁 | int x = 10; |
一句话:malloc 永远落在堆;局部变量永远落在栈。
四、程序有哪些section,分别的作用?程序启动的过程?怎么判断数据分配在栈上还是堆上?
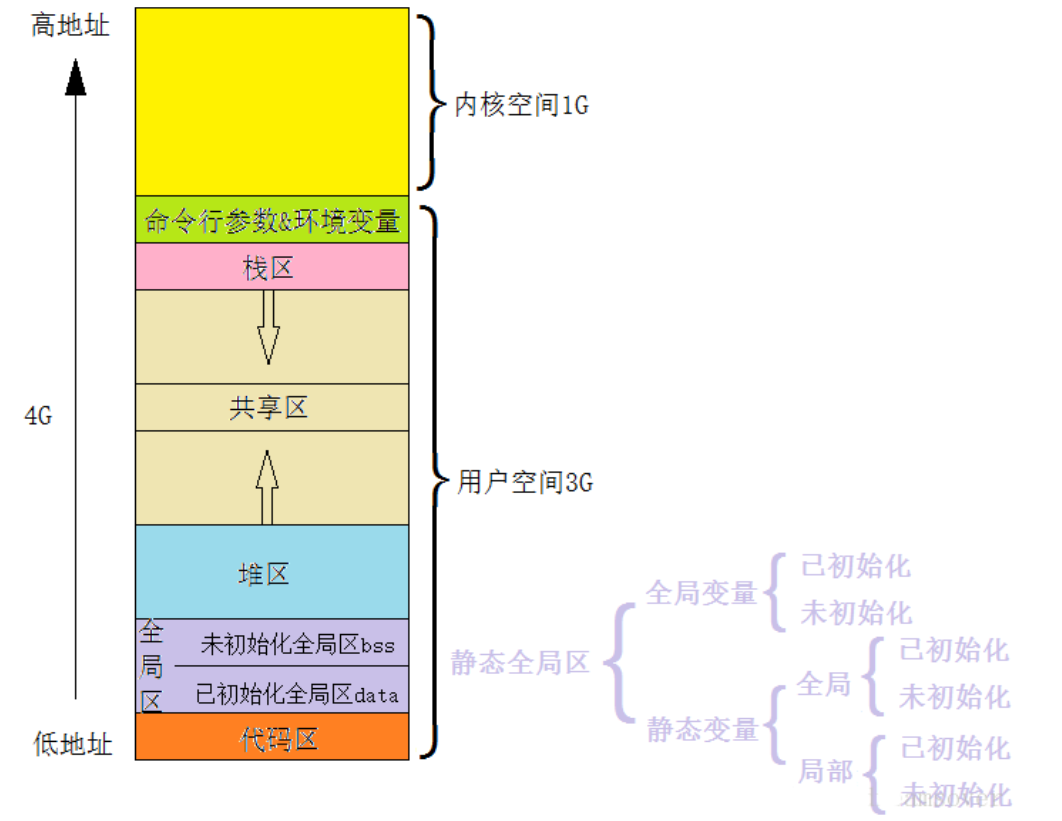
(1)、典型可执行文件(ELF)里的 section(段)
(按低→高地址排列,括号内为常见段名)
| Section | 作用 | 生命周期 |
|---|---|---|
| .text | 机器指令(代码) | 只读,整个进程 |
| .rodata | 只读常量(字符串、const 全局) | 同上 |
| .data | 已初始化的全局/静态变量 | 整个进程 |
| .bss | 未初始化的全局/静态变量(默认 0) | 整个进程 |
| heap | 运行时动态分配(malloc/new) | 程序员控制 |
| 共享库映射区 | mmap 的 .so 文件、匿名映射 | 按需加载 |
| stack | 函数帧、局部变量、返回地址 | 随函数进出 |
| 命令行参数 & 环境变量 | argc, argv, envp | 进程启动时由内核放进来 |
| 内核空间 | 内核代码/数据(用户不可见) | 整个系统 |
(2)、程序启动的 9 步流程(Linux 为例)
- Shell
fork→ 创建子进程 - 内核
execve装载 ELF - 读 ELF header → 解析各个 section 偏移和长度
- 建立虚拟地址空间:
- 把
.text/.rodata/.data/.bss映射进来 - 为 heap 预留一段匿名映射(
brk起点) - 预留 stack 区域并设置 RSP
- 把
- 装载动态链接器 (
ld-linux.so) → 映射到共享区 - 重定位 & 符号解析 → 把
.so的.text/.data填进共享区 - 初始化 .bss 为 0
- 运行
.init/__libc_start_main→ 调全局对象构造函数 - 跳转到
main→ 用户代码开始
(3)、如何判断数据在 栈 还是 堆?
| 场景 | 所在区域 | 判断技巧 |
|---|---|---|
int x = 5; | 栈 | 作用域结束即销毁 |
int *p = new int(5); | 堆 | 离开作用域后 *p 仍有效,需要 delete |
static int x; | 全局区(.data/.bss) | 整个进程生命周期 |
| `const char *s = “hello”; | ` 只读段(.rodata) | 地址位于低地址只读区域 |
malloc(…) 返回值 | 堆 | gdb / pmap / cat /proc/$$/maps 可见匿名映射 |
最实用的运行时判断
pmap -x <pid>
- 区间名
[stack]→ 栈 - 区间名
[heap]→ 堆 - 区间名
/lib/ld-linux.so→ 共享区
一句话总结
代码在 .text,常量在 .rodata,全局/静态在 .data/.bss,动态在 heap,局部在 stack;启动时内核按 ELF 把段映射进虚拟地址空间,运行时看作用域和分配 API 即可区分栈与堆。
五、初始化为0的全局变量在bss还是data
初始化为 0(或全零)的全局变量 放在 .bss,而不是 .data。
(.data 只收“非零初始值”的全局/静态变量。)
int g1 = 0; // .bss
int g2 = 42; // .data
static int s1 = 0; // .bss
static int s2 = 1; // .data
一句话:
零初始化的全局/静态变量进
.bss,非零才进.data。
六、简述C++中内存对齐的使用场景
一句话:
“让数据在内存里按照 CPU 最喜欢的地址倍数排排坐,从而少一次访存、多一次 SIMD。”
1️⃣ 典型场景
| 场景 | 原因 | 关键词 |
|---|---|---|
| 结构体/类成员布局 | 避免空洞、保证原子变量对齐 | #pragma pack, alignas |
| SSE/AVX 指令 | 128/256/512 bit 必须 16/32/64 字节对齐 | alignas(16) |
| malloc/new 无法满足 | 自定义对齐内存 | std::aligned_alloc, std::aligned_storage |
| 共享内存/网络协议 | 跨平台二进制兼容 | alignas(uint32_t) |
| 原子操作 | std::atomic<T> 要求 T 自然对齐 | alignof(std::max_align_t) |
2️⃣ 一行代码示例
struct alignas(32) Vec4 {float x, y, z, w;
}; // 起始地址一定是 32 的倍数,可直接 `_mm256_load_ps`
3️⃣ 口诀
“原子对齐保并发,SIMD 对齐保速度,协议对齐保兼容。”