超分——对比学习(Contrastive Learning)
一、对比学习基本知识
传统上,机器学习(ML)可以广泛分为两种类型:有监督学习和无监督学习。为了利用我们周围可用的大量数据,有一种先进的学习策略,称为自我-监督学习。在自我监督学习中,我们使用未标记的数据并“模拟”有监督学习。
在自我监督学习中,我们将数据分为正样本和负样本,类似于二元(有监督)分类,将考虑的对象视为正样本,将所有其他样本视为负样本。
自我监督学习方法学习联合嵌入,可以广泛分为两类:
- 对比方法
- 非对比方法
1.对比学习的目标
对比学习的目标是通过构造正样本对(相似样本)和负样本对(不相似样本),让模型学习到对相似样本的特征表示更接近,而对不相似样本的特征表示更远
2. 正样本和负样本的定义
- 正样本:来自同一 LR 图像的不同块,这些块具有相同的退化模式。
- 负样本:来自不同 LR 图像的块,这些图像具有不同的退化模式。
3. 对比学习的流程
- 数据增强:从每个 LR 图像中随机裁剪多个小块,这些小块作为正样本,而来自其他图像的小块作为负样本。
- 编码器网络:使用退化编码器将裁剪的小块编码为特征表示。
- 投影网络:将编码器输出的特征进一步投影到一个低维空间,以增强特征的判别能力
- 对比学习目标:通过损失函数,拉近正样本之间的距离,推远负样本之间的距离
4. 损失函数
在 LightBSR[202506超分模型] 中,使用 InfoNCE 损失来实现对比学习。InfoNCE 损失函数的形式如下:
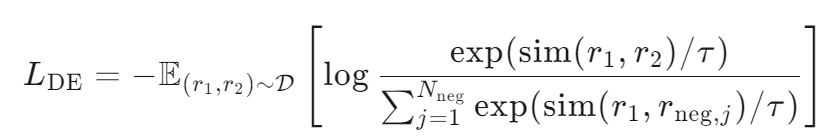
其中:
- r1和 r2是来自同一 LR 图像的两个小块的特征表示(正样本)。
是来自不同 LR 图像的小块的特征表示(负样本)。
- sim(⋅) 是相似度函数,通常使用点积或余弦相似度。
- τ 是温度超参数,用于控制相似度的缩放。
是负样本的数量.
5. 退化先验约束
在 LightBSR 中,对比学习结合了退化先验信息,即利用已知的退化参数(如模糊核宽度和噪声水平)来指导对比学习。具体来说,根据查询图像与其负对应物之间的退化差异程度,为负样本分配权重。这种方法被称为弱监督对比学习,因为它利用了退化参数作为隐式标签。
6. 动态队列
为了提高对比学习的效果,LightBSR 维护一个动态队列,存储来自不同 LR 图像的小块的特征表示。这个队列作为负样本字典,用于在训练过程中提供多样化的负样本.
7. 训练过程
在训练过程中,模型通过对比学习优化退化编码器,使其能够区分不同退化类型的 LR 图像。然后,将优化后的退化编码器与上采样器结合,进一步优化整个模型。
通过这种方式,对比学习在 LightBSR 中起到了关键作用,增强了模型对退化类型的区分能力,从而提高了盲超分辨率的性能。
二、入门对比学习
1.SimCLR(最经典入门)
| 项目 | 说明 |
|---|---|
| 名称 | SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) |
| 特点 | ✔️ 无需负标签 ✔️ 图像增强后构建正负样本 ✔️ 简单好跑 |
| 优点 | 用两张相似图学会“相似”表示,纯对比损失,适合初学者 |
| 地址 | github.com/google-research/simclr |
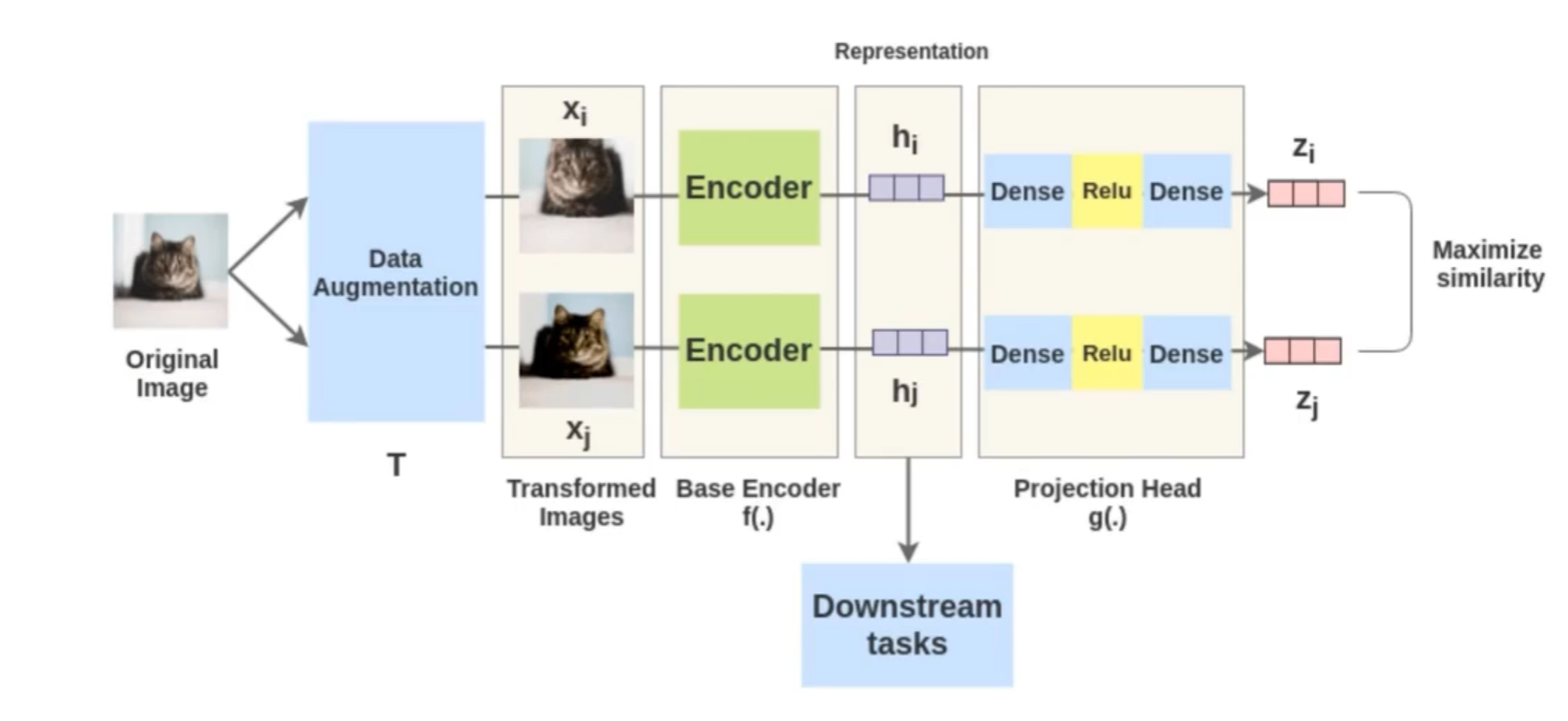
SimCLR 流程
- 数据增强:对每张图像应用两次不同的数据增强操作,生成两个增强视图(如裁剪、翻转、色彩失真、高斯模糊等)。这两个增强视图被视为正样本对。
- 特征提取:将增强后的图像输入到主干编码器(如 ResNet-50)中,提取高维特征向量 h。编码器的输出通常是经过平均池化后的特征。
- MLP 投影:使用一个小型的 MLP(多层感知器)将特征 h 投影到一个低维空间,生成新的特征向量 z。这个过程不仅引入了非线性特性,还减少了特征的维度,使得特征更适合进行对比学习。
- 计算损失:使用对比损失函数来优化模型。这个损失函数的目标是拉近正样本对之间的距离,推远负样本(即来自不同图像的增强视图)之间的距离。
具体流程
假设输入了100张图像,每张图像通过数据增强生成两个增强视图,那么总共有200个增强视图。这些增强视图的特征向量之间的相似度计算和损失计算如下:
- 数据增强:对每张图像进行两次不同的数据增强操作,生成两个增强视图。例如,图像
生成增强视图
和
,图像
生成增强视图
和
,依此类推。
- 特征提取和投影:将所有增强视图输入到编码器(如 ResNet-50)中,提取特征向量 h。通过 MLP 将特征向量 h 投影到低维空间,生成新的特征向量 z。
- 相似度计算:计算所有特征向量之间的相似度。对于每个特征向量
,计算其与所有其他特征向量
的相似度。相似度通常使用点积或余弦相似度来计算。
- 损失计算:使用对比损失函数(如 InfoNCE 损失)来优化模型。InfoNCE 损失的目标是拉近正样本对之间的距离,推远负样本之间的距离。具体来说,对于每个特征向量
,负样本是来自其他图像的所有增强视图
示例
假设输入了100张图像,每张图像生成两个增强视图,总共有200个特征向量。对于每个特征向量:
- 正样本对是
- 负样本是其他198个特征向量(来自其他图像的增强视图)。
模型会计算 与
的相似度,并将其与
与其他198个负样本的相似度进行对比,通过 InfoNCE 损失函数进行优化。
总结
在 SimCLR 中,每张图像的两个增强视图之间的相似度会被拉近,而不同图像的增强视图之间的相似度会被推远。这种对比学习方式使得模型能够学习到对不同增强视图具有区分性的特征表示,从而提升模型的性能。