基于RobustVideoMatting(RVM)进行视频人像分割(torch、onnx版本)
发表时间:2021年8月25日
项目地址:https://peterl1n.github.io/RobustVideoMatting/
论文阅读:https://hpg123.blog.csdn.net/article/details/134409222
RVM是字节团队开源的一个实时人像分割模型,基于LSTMConv实现,在效果与性能上取得良好效果。为此,对齐开源代码进行整理利用,实现对视频人像的实时分割。本博客包含,torch版本、onnx版本代码。请注意,RVM算法基于lstmconv实现,故推理时时序越长效果越稳定,屏闪概率越低。同时对比torch与onnx推理,发现torch推理速度比onnx快很多。
1、环境准备
1.1 模型下载
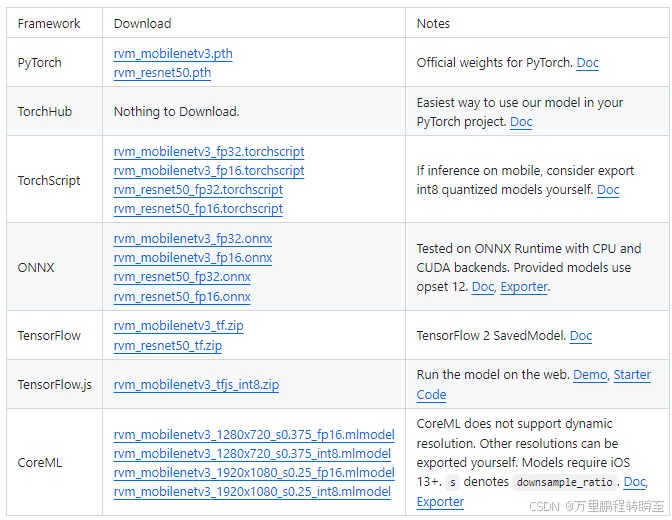
本项目一共开源了两个模型,有torch版本与onnx版本。这里需要下载torch模型与onnx模型
1.2 视频读写代码
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torch.utils.data import Dataset
from torchvision.transforms.functional import to_pil_image
from PIL import Imageimport decord
from torch.utils.data import Dataset
from PIL import Image
import numpy as npclass VideoReader(Dataset):def __init__(self, path, transform=None):# 初始化decord视频读取器,使用GPU加速(如果可用)self.vr = decord.VideoReader(path, ctx= decord.cpu(0)) #decord.gpu(0) # 获取帧率self.rate = self.vr.get_avg_fps()self.transform = transform# 获取视频总帧数self.length = len(self.vr)@propertydef frame_rate(self):return self.ratedef __len__(self):return self.lengthdef __getitem__(self, idx):# 读取指定索引的帧,返回numpy数组 (H, W, C),格式为RGBframe = self.vr[idx].asnumpy()# 转换为PIL图像frame = Image.fromarray(frame)# 应用变换if self.transform is not None:frame = self.transform(frame)return frameimport cv2
import numpy as npclass VideoWriter:def __init__(self, path, frame_rate, bit_rate=1000000):self.path = pathself.frame_rate = frame_rateself.bit_rate = bit_rateself.writer = Noneself.width = 0self.height = 0def write(self, frames):# frames: [T, C, H, W]# 获取视频尺寸self.width = frames.size(3)self.height = frames.size(2)# 如果是灰度图则转换为RGBif frames.size(1) == 1:frames = frames.repeat(1, 3, 1, 1) # convert grayscale to RGB#([1, 3, 1280, 720])# 转换为OpenCV需要的格式 [T, C, H, W] 且范围为0-255的uint8frames = frames.mul(255).cpu().permute(0, 2, 3, 1).numpy().astype(np.uint8)# OpenCV默认使用BGR格式,需要转换# 初始化视频写入器(首次调用write时)if self.writer is None:# 根据文件名后缀自动选择编码器fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 对于mp4格式# 如果是其他格式可以修改,例如'XVID'对应avi格式self.writer = cv2.VideoWriter(self.path,fourcc,self.frame_rate,(self.width, self.height))print(frames.shape,frames.dtype,frames.max(),self.width, self.height)for t in range(frames.shape[0]):frame = frames[t]frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)self.writer.write(frame)def close(self):if self.writer is not None:self.writer.release()1.3 torch模型定义代码
这里需要下载项目源码与模型,注意是引入model目录下的模型定义。
2、视频人像分割(torch版本)
2.1 模型加载代码
import torch
from model import MattingNetworkmodel = MattingNetwork('mobilenetv3').eval().cuda() # or "resnet50"
model.load_state_dict(torch.load('rvm_mobilenetv3.pth'))
2.3 调用代码
import torch
bgr = torch.tensor([.47, 1, .6]).view(3, 1, 1).cuda() # Green background.
rec = [None] * 4 # Initial recurrent states.
downsample_ratio = 0.25 # Adjust based on your video.writer = VideoWriter('output.mp4', frame_rate=30)
batch=60
with torch.no_grad():for src in DataLoader(reader,batch_size=batch): # RGB tensor normalized to 0 ~ 1.while src.shape[0]<batch:src=torch.cat([src,src[-1:]])fgr, pha, *rec = model(src.cuda(), *rec, downsample_ratio) # Cycle the recurrent states.fgr=fgr[:batch]pha=pha[:batch]com = fgr * pha + bgr * (1 - pha) # Composite to green background. writer.write(com) # Write frame.
writer.close()
2.3 处理效果
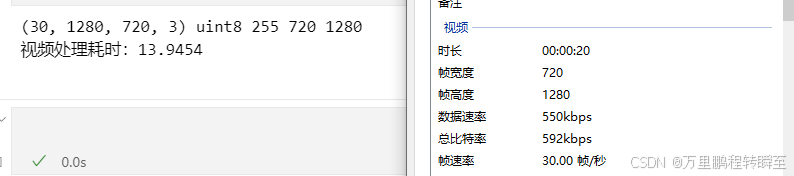
3060显卡,cuda12,torch 2.4,处理20s的720p,fps30 视频,耗时14s。


3、视频人像分割(onnx版本)
3.1 onnx模型加载代码
先将从github中下载的 模型在 https://netron.app/ 打开,确认是支持动态size的。
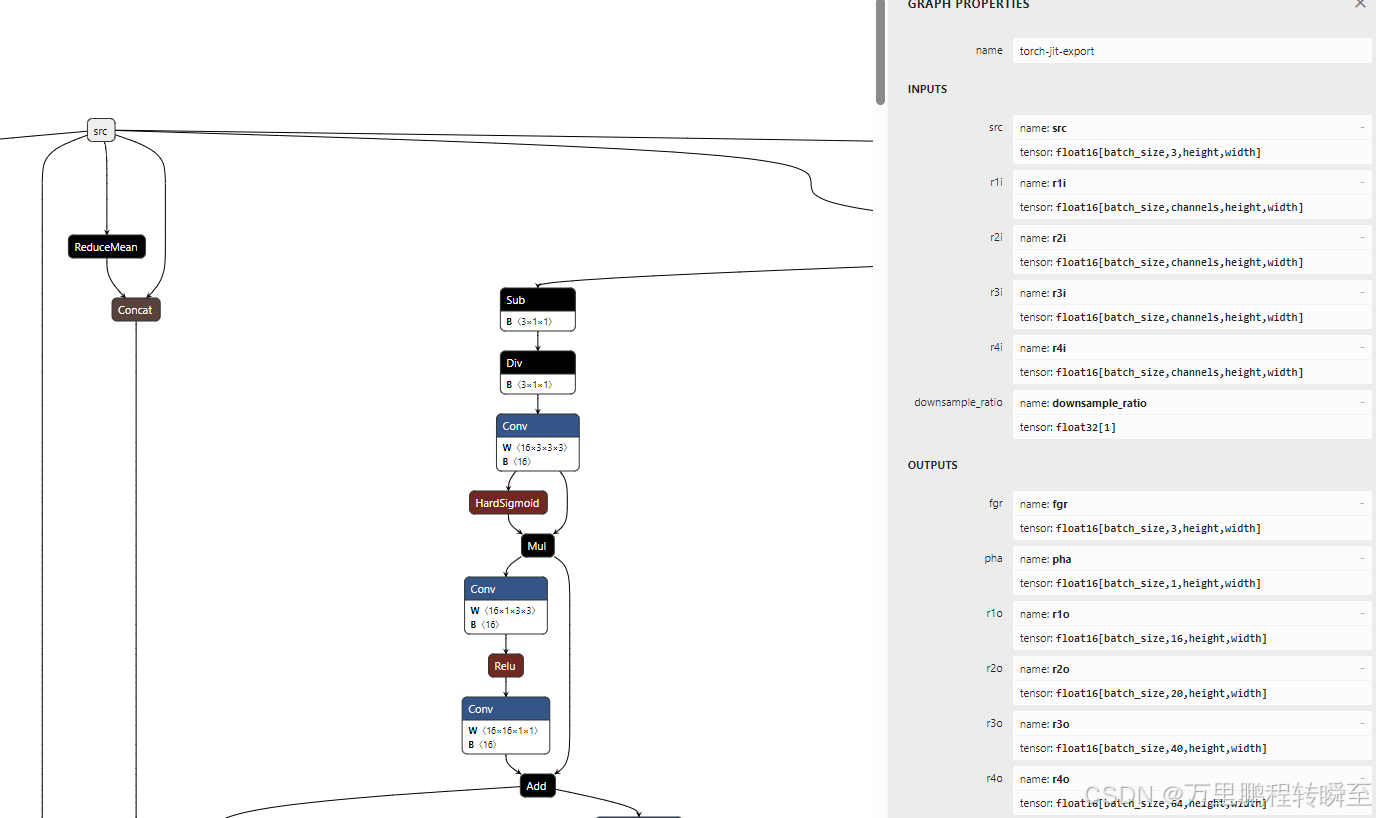
这里的代码为通用onnx模型推理代码
import onnxruntime as ort
import numpy as np
from typing import Dict, List, Union, Tupleclass ONNXModel:"""简化版ONNX Runtime封装,模拟PyTorch模型调用风格仅实现forward方法,输入输出均为numpy数组"""def __init__(self, onnx_path: str, device: str = 'cpu'):self.onnx_path = onnx_path# 根据设备选择执行提供程序providers = ['CPUExecutionProvider']if device.lower() == 'cuda' and 'CUDAExecutionProvider' in ort.get_available_providers():providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']# 初始化ONNX Runtime会话self.session = ort.InferenceSession(onnx_path, providers=providers)# 获取输入和输出节点信息self.input_names = [input.name for input in self.session.get_inputs()]self.output_names = [output.name for output in self.session.get_outputs()]def forward(self, *args, **kwargs) -> Union[np.ndarray, Tuple[np.ndarray]]:"""前向传播方法,模拟PyTorch的forward输入: numpy数组,可以是位置参数(按输入顺序)或关键字参数(按输入名称)输出: numpy数组或numpy数组元组"""# 准备输入字典inputs = {}# 处理位置参数if args:if len(args) != len(self.input_names):raise ValueError(f"位置参数数量不匹配,预期{len(self.input_names)}个,得到{len(args)}个")for name, arg in zip(self.input_names, args):inputs[name] = arg# 处理关键字参数if kwargs:for name, value in kwargs.items():if name not in self.input_names:raise ValueError(f"未知的输入名称: {name},有效名称为: {self.input_names}")inputs[name] = value# 检查输入完整性if len(inputs) != len(self.input_names):missing = set(self.input_names) - set(inputs.keys())raise ValueError(f"缺少输入: {missing}")# for k in inputs.keys():# print(k,inputs[k].shape,inputs[k].dtype)# 执行推理outputs = self.session.run(self.output_names,inputs)# 处理输出格式if len(outputs) == 1:return outputs[0]return tuple(outputs)def __call__(self, *args, **kwargs) -> Union[np.ndarray, Tuple[np.ndarray]]:"""重载调用方法,使实例可以像PyTorch模型一样被调用"""return self.forward(*args, **kwargs)
model = ONNXModel('rvm_mobilenetv3_fp16.onnx','cuda')
3.2 调用代码
这里推理代码与torch推理代码高度一致,注意数据类型。
import torch
import time
bgr = torch.tensor([.47, 1, .6]).view(3, 1, 1).numpy().astype(np.float16) # Green background.
rec = None # Initial recurrent states.
downsample_ratio = np.array([0.25]).astype(np.float32) # Adjust based on your video.writer = VideoWriter('output.mp4', frame_rate=30)
batch=32
t0=time.time()
with torch.no_grad():for src in DataLoader(reader,batch_size=batch): # RGB tensor normalized to 0 ~ 1.while src.shape[0]<batch:src=torch.cat([src,src[-1:]])src=src.numpy().astype(np.float16)if rec is None:rec=[np.zeros((1,1,1,1),dtype=np.float16)]*4fgr, pha, *rec = model(src, *rec, downsample_ratio) # Cycle the recurrent states.fgr=fgr[:batch]pha=pha[:batch]com = fgr * pha + bgr * (1 - pha) # Composite to green background. com=torch.tensor(com)writer.write(com) # Write frame.
writer.close()
rt=time.time()-t0
print(f"视频处理耗时:{rt:.4f}")
此时代码耗时为46s,相比于torch慢了很多。
(32, 1280, 720, 3) uint8 255 720 1280
视频处理耗时:45.9930