大模型性能测试完全指南:从流式响应到多模态的深度实践
当性能测试遇上大模型时代
"ChatGPT,请用300字解释量子纠缠,并保持每秒输出40个token的速度"——这样的需求正在重塑性能测试的边界。随着大模型进入千亿参数时代,传统的TPS(每秒事务数)测试方法已显乏力。本文将带你深入大模型性能测试的技术内核,揭秘那些只有一线工程师才知道的实战经验。
一、大模型性能测试的"三维"革命
1.1 传统测试 vs 大模型测试的范式转移
python
# 传统HTTP接口测试 def test_api():start = time.time()response = requests.post(api_url, json=data)latency = time.time() - start # 简单响应时间assert response.status_code == 200# 大模型流式测试 def test_llm_stream():first_token_time = Nonetoken_count = 0with requests.post(api_url, stream=True) as r:for chunk in r.iter_content():if not first_token_time:first_token_time = time.time() - start # 首Token延迟token_count += len(chunk['choices'][0]['delta']['content'])token_rate = token_count / (time.time() - first_token_time) # 吐字率
关键差异矩阵:
| 维度 | 传统性能测试 | 大模型性能测试 |
|---|---|---|
| 核心指标 | TPS、响应时间 | 首Token延迟、吐字率、QPM |
| 测试模式 | 请求-响应 | 流式交互 |
| 瓶颈点 | 网络带宽、数据库 | KV缓存、显存带宽、Prefill计算 |
1.2 大模型工作原理深度解析
Prefill-Decode两阶段架构:
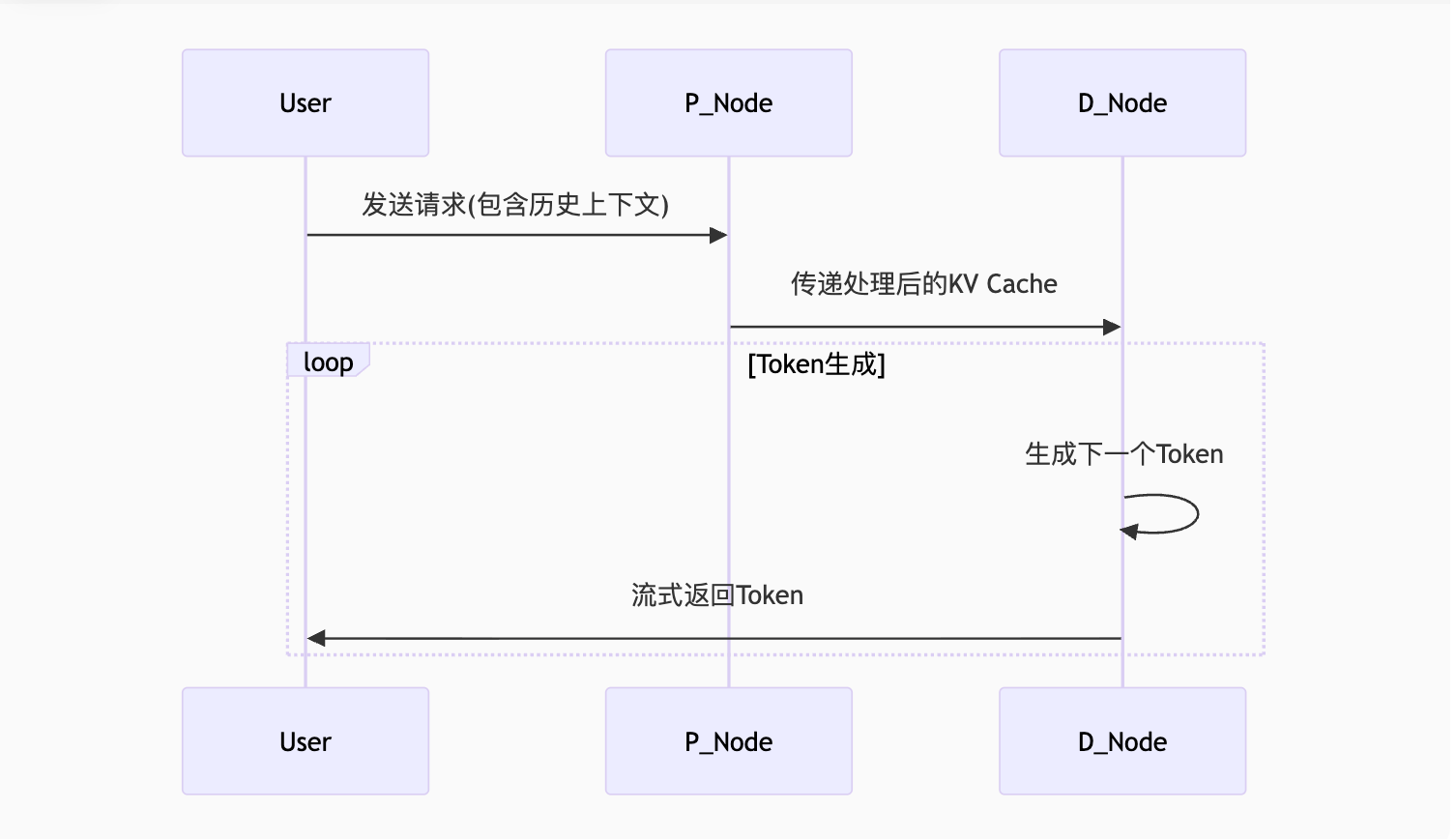
-
Prefill阶段:构建KV Cache(复杂度O(n²))
-
Decode阶段:逐个生成Token(复杂度O(n))
二、五大核心指标的实战测量
2.1 首Token延迟的"毫秒战争"
行业基准对比:
| 场景 | 优秀标准 | 达标标准 | 警告阈值 |
|---|---|---|---|
| 短文本(1k tokens) | ≤1.5s | ≤2s | >3s |
| 长文本(16k tokens) | ≤2.5s | ≤3.5s | >5s |
测量陷阱:
python
# 错误示例:包含网络延迟 start = time.time() # 包含TCP握手时间 response = requests.post(...) first_token = get_first_token(response) latency = time.time() - start # 污染了真实指标# 正确做法 start = time.time() with requests.post(..., stream=True) as r:for chunk in r.iter_content():if is_first_token(chunk):latency = time.time() - start # 精确测量break
2.2 吐字率(Token/s)的优化艺术
吞吐量公式:
吐字率吐字率
性能热点分布:
python
def token_generation_breakdown():return {"GPU计算": "45%", # 矩阵乘法"显存带宽": "30%", # KV Cache读取"CPU调度": "15%", # 任务分派"网络IO": "10%" # Token传输}
三、压力测试实战:Locust进阶技巧
3.1 自定义指标采集
python
from locust import events@events.request.add_listener def track_tokens(request_type, name, response_time, response_length, **kwargs):if "chat/completions" in name:tokens = count_tokens(response.text)env.stats.custom_stats["total_tokens"] += tokensclass ModelUser(HttpUser):@taskdef test_stream(self):# ...流式处理逻辑...self.environment.stats.custom_stats["token_rates"].append(token_rate)
3.2 阶梯式压测策略
四阶段压力模型:
yaml
phases:- name: "预热阶段"duration: 5mtarget: 1rpsmetrics:- first_token_latency ≤2s- name: "基准测试" duration: 10mtarget: 8rpschecks:- token_rate ≥40/s- name: "压力测试"duration: 10mtarget: 32rpsthresholds:- error_rate <1%- name: "极限测试"duration: 5m target: 64rpsabort: True # 触发异常自动停止
四、性能瓶颈的"法医式"分析
4.1 典型问题诊断指南
| 症状 | 根因分析 | 解决方案 |
|---|---|---|
| 首Token延迟波动大 | P节点负载不均衡 | 增加P节点/启用智能路由 |
| 吐字率阶梯式下降 | D节点显存带宽饱和 | 优化KV Cache分片策略 |
| 长文本响应时间爆炸 | O(n²)复杂度问题 | 启用FlashAttention优化 |
| 高并发时服务崩溃 | GPU OOM | 实现动态批处理(Dynamic Batching) |
4.2 黄金优化法则
30-60-10原则:
-
30%:首Token延迟控制在3秒内
-
60:吐字率稳定在60 Token/s以上
-
10%:GPU利用率波动不超过10个百分点
python
def health_check():metrics = get_llm_metrics()assert metrics['first_token_latency'] <= 3.0assert metrics['token_rate'] >= 60assert 0.7 <= metrics['gpu_util'] <= 0.9
五、多模态测试的新边疆
5.1 混合输入测试方案
python
multimodal_test_case = {"text": "描述图片中的主要事件","image": base64.b64encode(open("scene.jpg", "rb").read()),"audio": base64.b64encode(open("audio.wav", "rb").read())
}def evaluate_multimodal(output):visual_score = clip_similarity(output, expected_image_desc)audio_score = asr_accuracy(output, expected_transcript)return 0.6*visual_score + 0.4*audio_score # 加权评分
5.2 跨模态一致性验证
CLIP Score计算原理:
CLIPScore=ImageEmbedding⋅TextEmbedding∣∣ImageEmbedding∣∣⋅∣∣TextEmbedding∣∣CLIPScore=∣∣ImageEmbedding∣∣⋅∣∣TextEmbedding∣∣ImageEmbedding⋅TextEmbedding
测试用例设计:
-
文本→图像生成:输入"一只戴墨镜的柯基",检查生成图片
-
图像→文本描述:上传图片,验证描述准确性
结语:成为大模型时代的"性能侦探"
"优秀的性能测试工程师不是简单地运行脚本,而是要像侦探一样解读每个指标背后的故事。"在大模型时代,我们需要:
-
深度理解架构:从Transformer原理到KV Cache机制
-
全栈监控能力:从GPU显存到网络包分析
-
业务敏感度:区分"技术指标达标"与"用户体验优秀"

推荐阅读
-
https://blog.csdn.net/chengzi_beibei/article/details/150007634?spm=1001.2014.3001.5501
https://blog.csdn.net/chengzi_beibei/article/details/150008524?spm=1001.2014.3001.5501
https://blog.csdn.net/chengzi_beibei/article/details/150007572?spm=1001.2014.3001.5501
学社精选
- 测试开发之路 大厂面试总结 - 霍格沃兹测试开发学社 - 爱测-测试人社区
- 【面试】分享一个面试题总结,来置个顶 - 霍格沃兹测试学院校内交流 - 爱测-测试人社区
- 测试人生 | 从外包菜鸟到测试开发,薪资一年翻三倍,连自己都不敢信!(附面试真题与答案) - 测试开发 - 爱测-测试人社区
- 人工智能与自动化测试结合实战-探索人工智能在测试领域中的应用
- 爱测智能化测试平台
- 自动化测试平台
- 精准测试平台
- AI测试开发企业技术咨询服务
技术成长路线
系统化进阶路径与学习方案
- 人工智能测试开发路径
- 名企定向就业路径
- 测试开发进阶路线
- 测试开发高阶路线
- 性能测试进阶路径
- 测试管理专项提升路径
- 私教一对一技术指导
- 全日制 / 周末学习计划
- 公众号:霍格沃兹测试学院
- 视频号:霍格沃兹软件测试
- ChatGPT体验地址:霍格沃兹测试开发学社
- 霍格沃兹测试开发学社
企业级解决方案
测试体系建设与项目落地
- 全流程质量保障方案
- 按需定制化测试团队
- 自动化测试框架构建
- AI驱动的测试平台实施
- 车载测试专项方案
- 测吧(北京)科技有限公司
技术平台与工具
自研工具与开放资源
- 爱测智能化测试平台 - 测吧(北京)科技有限公司
- ceshiren.com 技术社区
- 开源工具 AppCrawler
- AI测试助手霍格沃兹测试开发学社
- 开源工具Hogwarts-Browser-Use
人工智能测试开发学习专区
- 人工智能/AI/为什么测试工程师需要掌握AI_哔哩哔哩_bilibili
- 人工智能在音频、视觉、多模态领域的应用_哔哩哔哩_bilibili
- 从0到1打造AI工作流:测试用例/测试架构图/测试报告/简历/PPT全自动生成