机器学习 - Kaggle项目实践(4)Toxic Comment Classification Challenge 垃圾评论分类问题
Toxic Comment Classification Challenge | Kaggle
NLP问题 输出每个评论comment 属于六种脏话标签的概率。
法一:用TF-IDF 得到词在句子中的权重,计算条件概率得到每个词对标签的贡献 对数先验比r,
TF-IDF矩阵 按位置乘上r得到总的权重后,再用逻辑回归二分类。
TF-IDF + 贝叶斯 + 逻辑回归 | Kaggle 最终0.97612分。
法二:用Tokenizer实现词->索引 comment->整数序列
GloVe词嵌入实现 索引->词向量 得到embedding_matrix词嵌入矩阵 用于神经网络的词嵌入
嵌入层+GRU 层+卷积层和池化层+Sigmoid 输出每个标签的概率。
Toxic Comment-Tokenizer+GloVe+GRU | Kaggle 最终0.98260分
法一:TF-IDF + 贝叶斯 + 逻辑回归
NB-SVM strong linear baseline | Kaggle (参考)
Toxic Comment Classification Challenge·1 | Kaggle (我的)
先得到一些关于comment的信息 包括comment的长度信息(要检测的评论有多长)
import pandas as pd, numpy as np
train = pd.read_csv('/kaggle/input/toxic-comment/train.csv')
test = pd.read_csv('/kaggle/input/toxic-comment/test.csv')display(train.head()) lens = train.comment_text.str.len()
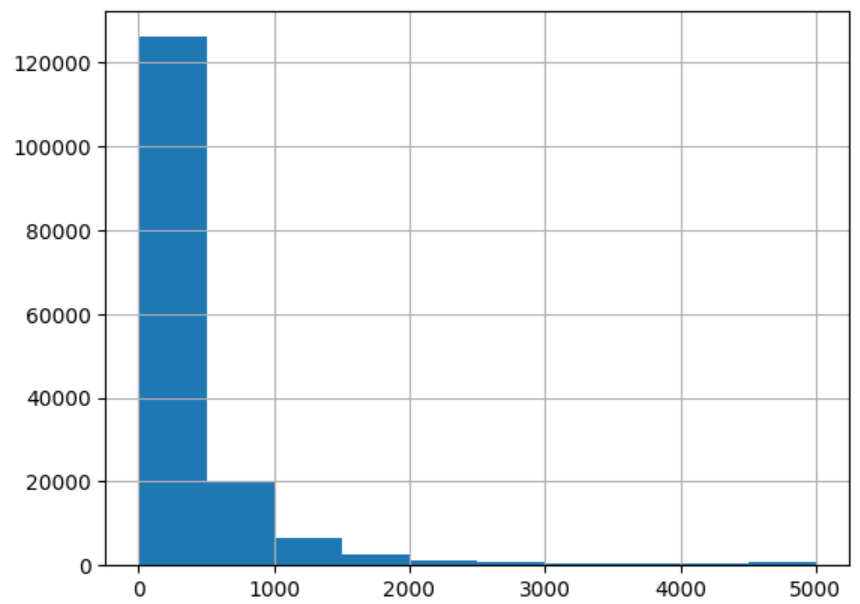
print(lens.mean(), lens.std(), lens.max())
lens.hist();可以看出大多数数据都比较短
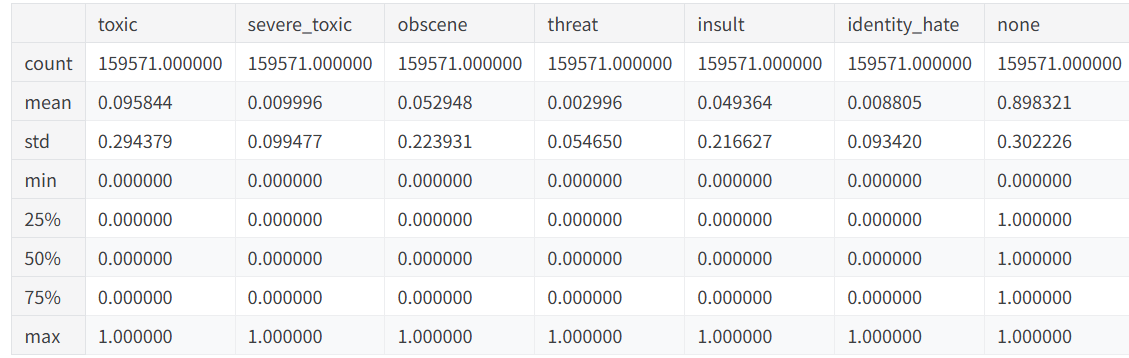
其次对于六种标签(还可以加上 1-max(它们) 即可表示 六个标签都不属于的非脏话)describe一下
并填补一下空缺位置
label_cols = ['toxic', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
train['none'] = 1 - train[label_cols].max(axis=1) # max为0 即取1时没有标签
display(train.describe())# 填补空缺
COMMENT = 'comment_text'
train.fillna({COMMENT: "unknown"}, inplace=True)
test.fillna({COMMENT: "unknown"}, inplace=True)可以发现 90%的样本是非脏话 并且每个标签出现次数是比较不均匀的
(这个信息很重要 但方法一处理的比较简单 没有利用)
处理1:TF-IDF向量化
把这列comment向量 转化为 列为comment 行为不同token(类似字典)的TF-IDF矩阵
TF 表示一个词在文档中出现的频率, IDF(逆文档频率)用来衡量一个词对整个语料库(所有文档)来说的重要性 / 整个语料库中的稀缺性,综合相当于给了这个词在这个句子中的权重。
此外,标点也是在我们的检测范围内 因为标点也可能和 toxic脏话有关。
我们通过建立标点集合re_tok,在标点前后加空格 使得split() 的时候把标点也当作token。
TfidfVectorizer的参数选取中,仅保留出现次数≥3 并且出现文档数 ≤90%的token,
ngram_range=(1,2) 保留长度为1,2 的词+短词组 token。
import re, string
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
re_tok = re.compile(f'([{string.punctuation}“”¨«»®´·º½¾¿¡§£₤‘’])')
# 上为找标点符号 下为在标点前后加空格 使得split()的时候可以把他们当成一个token
def tokenize(s): return re_tok.sub(r' \1 ', s).split()n = train.shape[0]
vec = TfidfVectorizer(ngram_range=(1,2), # 用 1-gram 和 2-gram(词+短词组)tokenizer=tokenize, # 自定义分词:把标点单独成词token_pattern=None, # 自定义 避免冲突告警min_df=3, # 词至少在 3 个文档中出现才保留(去掉极罕见噪声)max_df=0.9, # 出现于 >90% 文档的词丢弃(如非常常见的停用词)strip_accents='unicode', # 统一去重音/变体(拉丁语系常用)use_idf=True, # 启用 IDFsmooth_idf=True, # IDF 平滑,避免分母为 0sublinear_tf=True # TF 做对数缩放,弱化长文本/重复的影响
)
trn_term_doc = vec.fit_transform(train[COMMENT])
test_term_doc = vec.transform(test[COMMENT])trn_term_doc, test_term_doc转换后的矩阵是sparse稀疏的,虽然有426005个不同的token,但一行comment中只会出现很少。

处理2:朴素贝叶斯(Naive Bayes)-> 对数先验比
标签实际上是有一些相关性的,但这种方法没有考虑,只是对不同标签独立处理。
NB 在文本分类任务中表现良好,特别是当文本特征是稀疏的情况下。
条件概率/权重 通过计算每个词在各类别(如毒性等)中的条件概率,来为每个词分配一个权重。
比如我们在研究标签y 如何衡量这句话这个词对 标签y=y_i 0/1的贡献?
整个大矩阵是 n行(comment)前若干列为词列,后若干列为标签列。
研究一个标签与一个词 就把这两列拿出来,标签=1 则词对应位置的TF-IDF相当于有贡献。
用标签=1的 TF-IDF(权重)总和 / 标签=1的总格子数 = pr(1,y) 即词对 y=1 的贡献。
同样的还可以算出来 pr(0,y) 即词对 y=0 的贡献。
用 r = np.log(pr(1,y) / pr(0,y)) 每个词对标签的权重向量(对数先验比)。
越大说明出现这个词 越可能y=1,越小说明出现这个词 越可能y=0。
使用原TF-IDF矩阵 每行每个词 乘以r的权重;最终加权的结果进行逻辑回归
from sklearn.linear_model import LogisticRegression
def pr(y_i, y):p = trn_term_doc[y==y_i].sum(0) # 每个词 在标签y那列 对应值为 y_i的TF-IDF总和return (p+1) / ((y==y_i).sum()+1) # 条件概率 或者说词对 y=y_i的平均贡献def get_mdl(y):y = y.valuesr = np.log(pr(1,y) / pr(0,y)) # 每个词对标签的权重向量m = LogisticRegression(C=4, solver='liblinear', dual=True) # 正则化系数; 对偶训练x_nb = trn_term_doc.multiply(r) # 原训练集 乘上 每个词对标签的权重向量m.fit(x_nb, y)accuracy = m.score(x_nb, y) # 计算训练集上的准确率print(f"Training accuracy for label: {accuracy:.4f}") # 打印准确率return m, rfit toxic Training accuracy for label: 0.9918
fit severe_toxic Training accuracy for label: 0.9995
fit obscene Training accuracy for label: 0.9975
fit threat Training accuracy for label: 0.9999
fit insult Training accuracy for label: 0.9970
fit identity_hate Training accuracy for label: 0.9997
处理3:逻辑回归
LogisticRegression 加上正则化项C 稀疏矩阵dual 对偶训练更好
分标签预测时 先对train训练出m(逻辑回归模型)和 r(权重)
对test先乘上r 再在m中二分类 返回分类为1的概率
preds = np.zeros((len(test), len(label_cols))) # 初始化预测答案for i, j in enumerate(label_cols):print('fit', j)m,r = get_mdl(train[j]) # 对 j 那个标签 计算模型preds[:,i] = m.predict_proba(test_term_doc.multiply(r))[:,1] # 二分类结果为1的概率最后输出结果
subm = pd.read_csv('/kaggle/input/toxic-comment2/sample_submission.csv')
submid = pd.DataFrame({'id': subm["id"]})
submission = pd.concat([submid, pd.DataFrame(preds, columns = label_cols)], axis=1)
submission.to_csv('submission.csv', index=False)法二:Tokenizer+GloVe 词->索引->词向量 Bidirectional GRU
Bidirectional LSTM with Convolution | Kaggle
Toxic Comment-Tokenizer+GloVe+GRU | Kaggle
数据导入
import numpy as np
import pandas as pd
from tensorflow.keras.preprocessing import text, sequencetrain = pd.read_csv('/kaggle/input/toxic-comment/train.csv')
test = pd.read_csv('/kaggle/input/toxic-comment/test.csv')X_train = train["comment_text"].str.lower()
y_train = train[["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]].values
X_test = test["comment_text"].str.lower()# 检查数据形状
X_train.shape, y_train.shape,X_test.shape # X_train y_train 和 X_test 的形状处理1:Tokenizer 文本->整数
初始化 Tokenizer:创建 Tokenizer 对象并设置其参数。
拟合 Tokenizer:通过 fit_on_texts() 方法将文本数据传递给 Tokenizer,构建词汇表。
文本转换:通过 texts_to_sequences() 方法将文本数据转换为数字序列。
文本填充:使用 pad_sequences() 方法将序列填充至相同长度。
max_features=100000 # 字典大小 多少不同的token
maxlen=150 # 序列长度tok=text.Tokenizer(num_words=max_features,lower=True)
tok.fit_on_texts(list(X_train)+list(X_test)) # tok词汇表 token->整数索引
X_train=tok.texts_to_sequences(X_train) # 转换成整数序列 词汇表索引(不在就是0)
X_test=tok.texts_to_sequences(X_test)
x_train=sequence.pad_sequences(X_train,maxlen=maxlen) # 统一comment的长度 多的截断 少的补0
x_test=sequence.pad_sequences(X_test,maxlen=maxlen)处理2:GloVe 词嵌入(为神经网络第一层准备矩阵)
加载 GloVe 词嵌入(帮助模型理解文本中每个单词的语义信息)
原先 tok 中 word:idx每个词-> 整数索引
GloVe embeddings_index 中 每个词-> 一个向量
embedding_matrix 中 每个整数索引-> 一个向量,把之前的sequence序列 每个数对应一个词向量
embed_size=300
EMBEDDING_FILE = '/kaggle/input/glove840b300dtxt/glove.840B.300d.txt'
embeddings_index = {}
with open(EMBEDDING_FILE,encoding='utf8') as f:for line in f:values = line.rstrip().rsplit(' ') # 读取文件 第一个值是词 后面的值是向量word = values[0]coefs = np.asarray(values[1:], dtype='float32')embeddings_index[word] = coefs # 每个word 对应向量word_index = tok.word_index
num_words = min(max_features, len(word_index) + 1)
embedding_matrix = np.zeros((num_words, embed_size))for word, i in word_index.items(): # token词汇表每个词:索引if i >= max_features:continueembedding_vector = embeddings_index.get(word)if embedding_vector is not None: # 如果记录了词向量就填充embedding_matrix[i] = embedding_vector处理3:模型建构
嵌入层:将文本数据转换为词向量。
GRU 层:用于捕捉序列的上下文信息。
卷积层和池化层:用于提取局部特征,并通过池化降低维度。
全局平均池化层:将序列的特征压缩为一个固定大小的向量,进行进一步处理。
输出层:通过 Sigmoid 激活函数 输出每个标签的概率,适合于多标签分类任务。
最终,通过 Adam 优化器 和 二元交叉熵损失函数 进行训练,适用于多标签文本分类问题。
from keras.models import Sequential
from keras.layers import Dense,Input,LSTM,Bidirectional,Activation,Conv1D,GRU
from keras.callbacks import Callback
from keras.layers import Dropout,Embedding,GlobalMaxPooling1D, MaxPooling1D, Add, Flatten
from keras.layers import GlobalAveragePooling1D, GlobalMaxPooling1D, concatenate, SpatialDropout1D
from keras import initializers, regularizers, constraints, optimizers, layers, callbacks
from keras.callbacks import EarlyStopping,ModelCheckpoint
from keras.models import Model
from keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_scoremodel = Sequential()# 卷积块 1:嵌入层 + 空间丢弃层
model.add(Embedding(input_dim=max_features, output_dim=embed_size, weights=[embedding_matrix], trainable=False, input_length=maxlen))
model.add(SpatialDropout1D(0.2)) # 空间丢弃层,用于防止过拟合# 卷积块 2:双向 GRU 层
model.add(Bidirectional(GRU(128, return_sequences=True, dropout=0.1, recurrent_dropout=0.1)))# 卷积块 3:1D 卷积层
model.add(Conv1D(64, kernel_size=3, padding="valid", kernel_initializer="glorot_uniform"))
model.add(MaxPooling1D(pool_size=2))
model.add(GlobalAveragePooling1D())# 6个输出通道 分别sigmoid
model.add(Dense(6, activation="sigmoid"))# 编译模型
model.compile(loss='binary_crossentropy', optimizer=Adam(learning_rate=1e-3), metrics=['accuracy'])处理4:回调函数+训练
使用 ModelCheckpoint 回调函数来保存验证集上最好的模型权重
使用 EarlyStopping 回调函数,当验证集准确率没有提升时提前停止训练
题目要求的评估函数是ROC-AUC 每个epoch结束后计算并输出 ROC-AUC 分数。
# 定义自定义回调函数 RocAucEvaluation,用于计算和输出 ROC-AUC 分数
class RocAucEvaluation(Callback):def __init__(self, validation_data=()):super(Callback, self).__init__()self.X_val, self.y_val = validation_datadef on_epoch_end(self, epoch, logs={}):y_pred = self.model.predict(self.X_val, verbose=0)score = roc_auc_score(self.y_val, y_pred)print("\n ROC-AUC - epoch: {:d} - score: {:.6f}".format(epoch+1, score))# 设置模型权重保存的路径
filepath = "weights_base.best.keras"# 使用 ModelCheckpoint 回调函数来保存验证集上最好的模型权重
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
# 使用 EarlyStopping 回调函数,当验证集准确率没有提升时提前停止训练
early = EarlyStopping(monitor="val_acc", mode="max", patience=5)
# 使用自定义的 RocAucEvaluation 回调函数,计算并输出 ROC-AUC 分数
ra_val = RocAucEvaluation(validation_data=(X_val, y_val))# 将所有回调函数组成一个列表
callbacks_list = [ra_val, checkpoint, early]# 训练模型,使用训练集和验证集,并应用回调函数
X_tra, X_val, y_tra, y_val = train_test_split(x_train, y_train, train_size=0.9, random_state=233)
model.fit(X_tra, y_tra, batch_size=128, epochs=4, validation_data=(X_val, y_val), callbacks=callbacks_list, verbose=1)# 加载验证集上表现最好的模型权重
model.load_weights(filepath)# 使用训练好的模型对测试集进行预测
print('Predicting....')
y_pred = model.predict(x_test, batch_size=1024, verbose=1)预测并输出
# 加载验证集上表现最好的模型权重
model.load_weights(filepath)# 使用训练好的模型对测试集进行预测
print('Predicting....')
y_pred = model.predict(x_test, batch_size=1024, verbose=1)submission = pd.read_csv('/kaggle/input/jigsaw-toxic-comment-classification-challenge/sample_submission.csv')
submission[["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]] = y_pred
submission.to_csv('submission.csv', index=False)