IO多路复用底层原理
目录
一、基础铺垫:socket通信的阻塞问题
(1)单个socket的阻塞机制
(2)多路复用的需求暴露
二、select模型:最原始的多路复用模型
(1)核心数据结构与接口
(2)底层工作流程与数据结构的变化
阶段 1:注册监控的 socket
阶段 2:轮询检查就绪状态
阶段 3:阻塞等待(核心!)
阶段 4:事件唤醒与结果返回
(3)缺陷分析
三、poll模型:突破FD数量限制、简化用户操作流程
(1)核心数据结构与接口
(2)底层工作流程与数据结构变化
四、epoll模型:高并发场景的终极解决方案
(1)核心接口与事件结构
(2)底层数据结构:eventpoll
(3)底层工作流程与数据结构的变化
阶段1:创建epoll模型编辑
阶段 2:注册监控的 socket(epoll_ctl)
阶段 3:阻塞等待事件(epoll_wait)
阶段 4:事件唤醒与处理(回调机制)
(4)高效的核心原因
在Linux通信中,当需要同时处理多个socket连接时,传统的“一连接、一线程”模式会带来极大的资源开销,比如每一个线程栈就要8M,大量连接内存会不够用;线程调度会有开销,当线程数量过多的时候,可能调度开销占比过高,挤占了业务处理的cpu时间片。
而IO多路复用旨在让一个线程监测多个IO(socket通信)时间,极大程度上的减少了上述方式的开销。IO多路复用则分为select、poll、epoll三种,本文从内核数据结构与阻塞队列机制出发,详细讲解这三种多路复用模型的底层原理,帮助理解“如何用一个线程管理多个连接”。
一、基础铺垫:socket通信的阻塞问题
(1)单个socket的阻塞机制
当程序通过recv、read从socket读取数据时:
1.若socket中的接收缓冲区队列中有skb,则recv直接返回到用户缓冲区。
2.若无skb,内核会把当前线程放到该socket的阻塞等待队列中,线程释放CPU资源,进入休眠。
3.数据到达socket后,内核会同时唤醒这个socket的阻塞等待队列,将该队列中的线程插入到调度器中,然后继续执行read,从socket中读取数据。
注意:因为linux遵循一切皆文件的思想,socket是一个文件,网卡设备也是一个文件。那么文件中必然会有线程的阻塞队列struct wait_queue_head_t 。虽然在不同类型的文件中,这个等待队列表头可能嵌入到不同的层级位置,但是一定会有。
比如在socket文件中,他就直接存在于struct sock中:
struct sock { wait_queue_head_t sk_sleep; // socket 的阻塞等待队列 // 其他字段:接收队列、发送队列、状态等
}; // 等待队列头结构
struct wait_queue_head_t { spinlock_t lock; struct list_head task_list; // 等待的线程链表
}; 当线程因recv阻塞时,会由内核把该线程的调度实体包装成 wait_queue_t 节点加入该设备(文件)的阻塞队列 sk_sleep->task_list,直到被唤醒。
(2)多路复用的需求暴露
若同时处理10w个socket连接,传统方式会创建10w个线程,每个线程阻塞在自己的socket上,会导致:

IO 多路复用核心目标:让单个线程监控多个 socket,仅在有 socket 就绪时处理,其余时间休眠。
二、select模型:最原始的多路复用模型
select是古老的多路复用接口,通过 “轮询 + 多队列等待” 实现多路监控,虽效率不高,但奠定多路复用基础。
(1)核心数据结构与接口
select 通过 fd_set 位图管理需监控的 socket(文件描述符 FD):
// 监控读、写、异常事件的 FD 集合
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); // FD 集合操作宏
FD_ZERO(fd_set *set); // 清空集合
FD_SET(int fd, fd_set *set); // 添加 FD 到集合
FD_ISSET(int fd, fd_set *set); // 检查 FD 是否就绪 fd_set 本质是位图数组,默认最大支持 1024 个 FD(由 __FD_SETSIZE 定义):
#define __FD_SETSIZE 1024
#define __NFDBITS (8 * sizeof(unsigned long))
typedef struct { unsigned long fds_bits[__FD_SETSIZE / __NFDBITS];
} fd_set; 可以看到他在Linux中直接写死了1024个的上限,而且这个上限不仅仅是个数,也是文件描述符的最大值。如果想要使用select并扩大其容量,则需要重新编译,不能在运行的时候切换。
(2)底层工作流程与数据结构的变化
阶段 1:注册监控的 socket
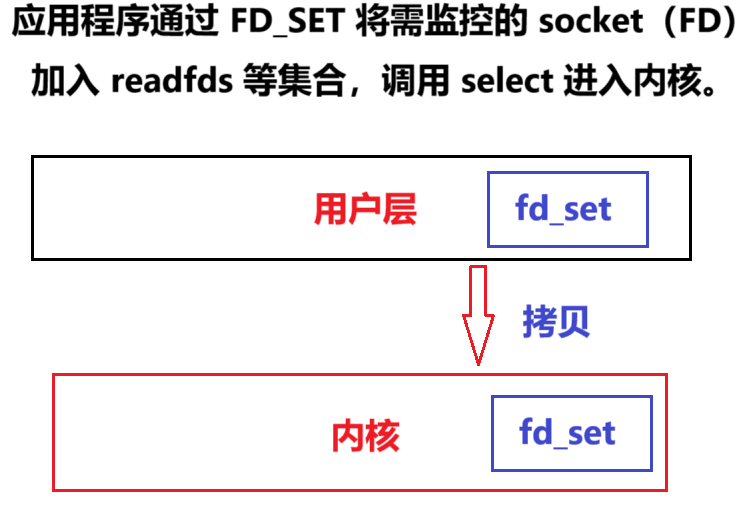
阶段 2:轮询检查就绪状态

阶段 3:阻塞等待(核心!)
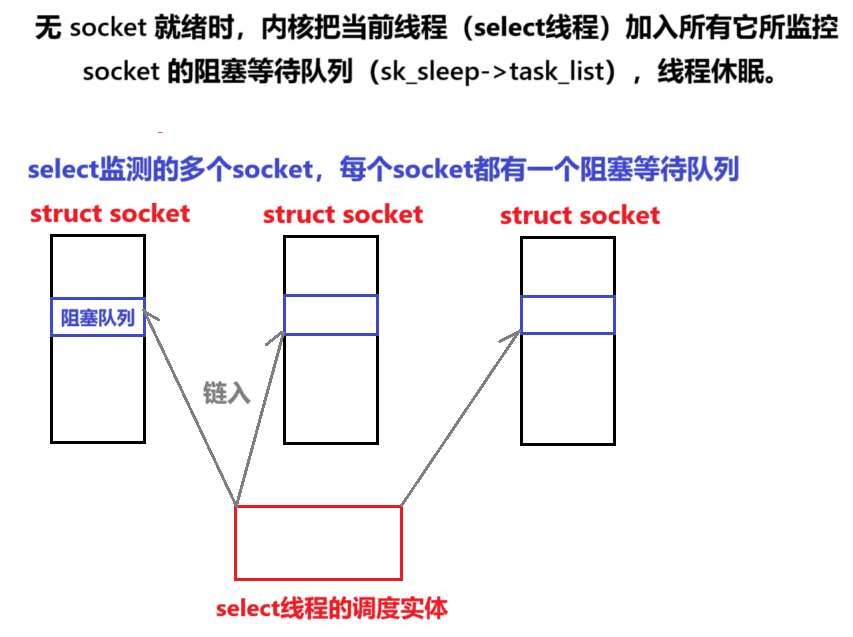
阶段 4:事件唤醒与结果返回
当数据包到达网卡后,网卡触发硬件中断,由CPU将这个数据包交给内核协议栈,一层层的解包,最后获得skb,由于数据包本身记录了socket的信息,所以skb可以正确被插入到对应socket的缓冲区队列中。
同时,内核会唤醒该socket的等待队列,将其中的所有线程插入到调度器中。当各自线程被调度的时候,会重新继续执行select,进行轮询操作,如果发现轮询时候并没有skb,称为伪唤醒(可能已经被别的线程读取了),则继续回到该socket的阻塞队列中。如果轮询时候发现有数据,则立马select返回,提醒用户读取。
(3)缺陷分析
- 轮询效率低:无论就绪 socket 数量,每次需遍历所有监控 FD(O (n) 复杂度);
- FD 数量限制:默认最大 1024 个 FD,修改需重新编译内核;
- 用户态 - 内核态拷贝:每次调用需拷贝整个
fd_set,就绪后再拷贝回用户态;开销大。- 集合需重置:
select返回后,未就绪 FD 被清空,下次调用需重新添加。操作复杂。- 唤醒浪费(虚假唤醒):线程被加入所有监控的socket 等待队列,一个 socket 就绪唤醒线程,但唤醒后select线程会遍历等待队列所有的socket,没有就绪的socket又会被重新插入队列中,看起来是“虚假唤醒”。
三、poll模型:突破FD数量限制、简化用户操作流程
poll 优化 select 的 FD 数量限制问题,用数组替代位图,但核心 “轮询 + 多队列等待” 机制未变。
(1)核心数据结构与接口
struct pollfd { int fd; // 要监控的 socket FD(-1 表示忽略) short events; // 关注的事件(如 POLLIN 表示可读) short revents; // 实际发生的事件(输出)
}; int poll(struct pollfd *fds, nfds_t nfds, int timeout); 事件类型包括:

(2)底层工作流程与数据结构变化
poll 工作流程与 select 几乎一致,核心区别:
- 用
pollfd数组替代fd_set:解除 1024 个 FD 限制,支持更多 socket 监控;- 输入输出分离:
events(关注事件)与revents(实际事件)分离,无需每次重置监控事件。
阻塞队列机制:与 select 完全相同,线程仍被加入所有监控 socket 的阻塞等待队列(sk_sleep->task_list),唤醒后需遍历所有 pollfd 查找就绪 socket。
四、epoll模型:高并发场景的终极解决方案
epoll是Linux 专为高并发设计的多路复用机制,通过 “事件驱动 + 单一队列等待”,彻底解决select/poll的效率问题。
(1)核心接口与事件结构
核心接口:
// 创建 epoll 实例,返回 epoll FD
int epoll_create(int size); // 注册/修改/删除监控的 socket 及事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 等待事件就绪
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); 事件结构:
struct epoll_event { uint32_t events; // 关注的事件(EPOLLIN/EPOLLOUT 等) epoll_data_t data; // 关联数据(通常存 socket FD)
}; (2)底层数据结构:eventpoll
epoll 的高效依赖内核中 eventpoll 结构体,它是连接用户线程和监控 socket 的 “中间枢纽”:
struct eventpoll { // 1. 红黑树:存储所有监控的 socket 及事件(快速增删改查) struct rb_root rbr; // 2. 就绪链表:存放已就绪的事件(无需轮询) struct list_head rdllist; // 3. 等待队列:epoll 自身的阻塞等待队列(线程仅需加入这里) wait_queue_head_t wq; // 4. 锁:保护红黑树和就绪链表的并发访问 spinlock_t lock;
};
- 红黑树(
rbr):键为 socket FD,值为epitem(包含 socket 指针、事件类型、回调函数等),实现 O (log n) 的增删改查;- 就绪链表(
rdllist):socket 就绪时,对应的epitem加入该链表,epoll_wait直接从链表取就绪事件;- 等待队列(
wq):用户线程阻塞时,仅需加入这个队列,无需加入每个 socket 的队列。
(3)底层工作流程与数据结构的变化
epoll 工作流程分 “注册监控”“阻塞等待”“事件唤醒” 三阶段,核心是 “事件驱动” 而非轮询。
阶段1:创建epoll模型
阶段 2:注册监控的 socket(epoll_ctl)
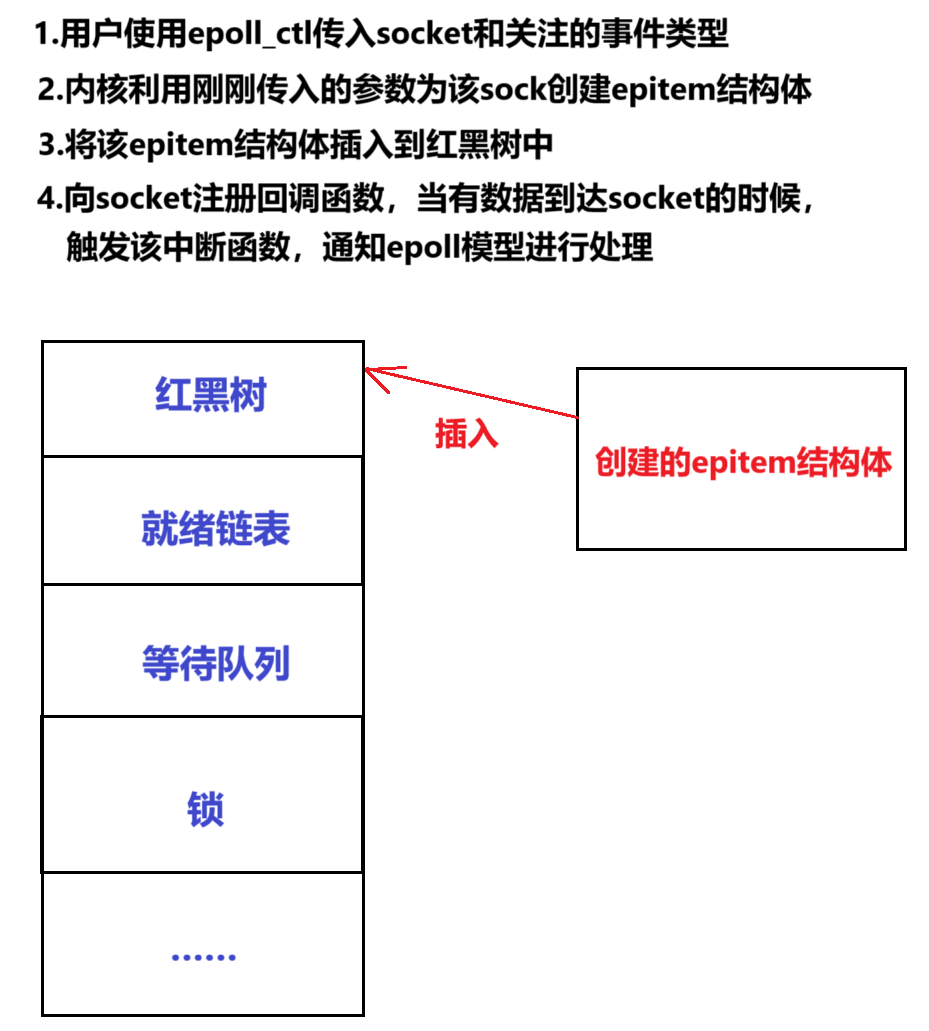
阶段 3:阻塞等待事件(epoll_wait)

阶段 4:事件唤醒与处理(回调机制)

(4)高效的核心原因
单一等待队列:
用户线程仅需加入eventpoll->wq,无需加入每个 socket 的队列,避免 “多队列唤醒” 的惊群效应,节省内核资源。事件驱动而非轮询:
通过ep_poll_callback回调,socket 就绪时主动加入epoll的就绪链表,epoll_wait无需遍历所有 socket(O (k) 复杂度,k 为就绪数量),效率大幅提升。红黑树管理 socket:
支持高效增删改查(O (log n)),轻松应对十万级甚至百万级连接。