tun/tap 转发性能优化
虽然我觉得大部分(如果不是所有的话)优化(就是 “优化” 这个词)本身都是没事干了屎上雕花,但毕竟还是朵花,还得讲究好看。
通过 tun/tap 网卡转发数据包的老掉牙逻辑,我接触太多,从 2012 年到现在十多年了,这种常规操作早已形成范式,今天主要谈谈性能优化。
性能优化需要从全局着眼,从技术细节开始深究是大忌,典型的案例:
- 看到链表操作就优化 lock,最后才知道只有一个线程操作这个链表;
- 看到链表遍历就想换成树,最后才知道这个链表最多只有 10 个元素;
- 看到 malloc 就想池化,最后才知道一个逻辑事务的耗时在 10ms 级;
- …
起因是我竟然在生产环境的程序中看到了下面的代码:
RingBuffer *rb = ...;
char buf[MTU + 2];len = read(tun_fd, buf, MTU);pthread_mutex_lock(&rb->tun2socket->mutex);
...
memcpy(rb->tun2socket->buff + rb->tun2socket->write_pos + 2, buf, len + 2);
ptr = rb->tun2socket->buff + rb->tun2socket->write_pos;
*ptr = (unsigned short)len;
...
pthread_mutex_unlock(&rb->tun2socket->mutex);// write_to_socket 类似
好好的 RingBuffer 临界区里做了个 memcpy。
…
着手优化前,要明确一些前置知识,首先就是临界区或锁的可扩展性问题。简单讲就是等锁的时间是否固定,而这涉及到两个因素:
- 临界区指令执行时间是否会增加;
- 争抢临界区的 task 数量是否增加;
我们看到的内核中 soft/hard lockup 大多由上述因素或其之一引发,另一个极端是临界区的指令数非常固定,比如 queue 入队操作,看下面的函数,满打满算多少指令:
void enqueue(List* q, MemoryBlock* block)
{block->next = NULL;//pthread_mutex_lock(&q->g_lock); pthread_mutex_lock(&q->tail_lock);if (q->tail) {q->tail->next = block;} else {pthread_mutex_lock(&q->head_lock);q->head = block;pthread_mutex_unlock(&q->head_lock);}q->tail = block;atomic_fetch_add(&q->counter, 1);pthread_mutex_unlock(&q->tail_lock);//pthread_mutex_unlock(&q->g_lock);
}MemoryBlock* dequeue(List* q)
{//pthread_mutex_lock(&q->g_lock);pthread_mutex_lock(&q->head_lock);MemoryBlock* block = q->head;if (block) {q->head = block->next;if (!q->head) {pthread_mutex_lock(&q->tail_lock);q->tail = NULL;pthread_mutex_unlock(&q->tail_lock);}atomic_fetch_sub(&q->counter, 1);}pthread_mutex_unlock(&q->head_lock);//pthread_mutex_unlock(&q->g_lock);return block;
}
这情况下,用大锁还是头尾双锁就无关紧要了,特别是明知只有 2 个 thread 争抢临界区时,即便用 g_lock 互斥又能怎样,无非多等几个指令的时间,将 g_lock “优化” 成 head_lock + tail_lock 就是牙缝里抠肉。
不过这几个指令到底价值几何,还是需要量化。仍以上述 queue 为例,临界区时间,相比 MemoryBlock 使用时间是个什么比值,需要测量。例如千兆环境,每秒一定小于 10 万次操作,如果 queue 互斥操作小于 10 万次,就没有必要优化锁本身,就不必实现复杂的无锁队列。
务必先测量再评估(使用 bcc 脚本,perf,火焰图等工具),务必测量 __tcp_transmit_skb,tcp_write_xmit,tcp_sendmsg,观测它们与 queue 操作时延的数量级,再做估量。
接下来,memcpy 虽是大忌,但原子无锁 RingBuffer 就到了另一个极端,我在后面说。先用一种 “正常” 的,循序渐进的思路,环形内存池链表是一种可能性,但得先试试直接 malloc/free:
char *buf = malloc(MTU + 2);len = read(tun_fd, buf + 2, MTU);
...
len = send(sock_fd, buf, len + 2, ...);
free(buf);
不要看不上 malloc/free 什么都要自己做,多数情况下,malloc 已足够,它本身就考虑了池化和互斥,不会傻到每次都 brk/mmap,此外它还可通过 mallopt 定制行为,除非真遇到了必须解决的性能问题并能证明内存池化真解决了性能问题,否则宁可继续试试 jemalloc,也不要自己实现内存池。
你能考虑到的优化点,如果它正确,过往 50 年来大概率有人想到并早就实现了,找到现成的比自己实现能减少大量的 debug 和维护成本,并且大概率比自己实现得要更优秀。
malloc 不满足,自己实现一个最简单的内存池,先不追求地址连续,否则还是要绕回 RingBuffer,最后陷入回绕,原子变量等细节,先实现一个操作最简单的基于 queue 的内存池,使用时从 queue 池中 dequeue 一个 block,用完后 enqueue 回池中。
先给出 MemoryBlock 定义:
typedef struct MemoryBlock {char data[MTU + 2];struct MemoryBlock* next;
} MemoryBlock;
再看操作:
// v1: non-batch
void* cpu1_task(void* arg)
{while(f) {MemoryBlock* block = dequeue(&pool);if (block) {len = read(tun_fd, block->data + 2, MTU);ptr = (unsigned short *)&block->data[0];*ptr = (unsigned short)len;enqueue(tun2socket, block);}}return NULL;
}void* cpu2_task(void* arg)
{while(1) {MemoryBlock* block = dequeue(tun2socket);if (block) {ptr = (unsigned short *)&block->data[0];len = *ptr;len = send(sock_fd, block->data, len + 2)enqueue(&pool, block);}}return NULL;
}
先不管效率,反正它简单,数据结构分离,可扩展,能运行,这是进一步优化的前提。
为了行文简便,我不引入太复杂的隧道协议,只在 tun 描述符读出的 IP 数据报前拼接一个 2 字节的 len,将 len + 2 字节数据送入 socket。
现在我们知道,每个 block 携带一个 buffer,里面装一个从 tun 描述符读入的 IP 报文长度和 IP 报文本身,最终将其送入 socket send。虽然 tun 描述符每次进出一个 IP 报文,但 socket send/recv 却是字节流,这里就有 batch 优化空间,搜集多个 block 一起 send/recv。
但由于 block 由于 queue 组织,不保证连续,好在 socket 提供 scatter-gather 接口 sendmsg,dequeue 方需将多个 block 搜集起来组成 iov, 那么 enqueue 方最好能将 block 先聚集起来。
再次不考虑效率,先实现效果,在 block 之上加一个层作为容器,容纳批处理的 block:
// v2-batch
void* cpu1_task(void* arg)
{while(1) {// 取出一个可用容器MemoryBlock *sgnode = dequeue(&batch_pool);// 实现类似 TCP push 的效果,参见 tcp_write_xmitwhile (sgnode->sg_head->counter < BATCH_SIZE) {MemoryBlock* block = dequeue(&pool);if (block) {if (READ_from_TUN(block) == EAGAIN) {break;}enqueue(sgnode->sg_head, block);}}enqueue(tun2socket, sgnode);}return NULL;
}int WRITE_to_SOCKET(struct iovec *iov)
{return 0;
}
void* cpu2_task(void* arg)
{struct iovec iov[BATCH_SIZE];while(1) {int i = 0;MemoryBlock *block;// 取出满载的容器MemoryBlock *sgnode = dequeue(tun2socket);block = sgnode->sg_head->head;// 组织 iovwhile(block) {iov[i].iov_base = &block->data[2];iov[i].iov_len = (int)*(unsigned short *)&block->data[0];block = block->next;i ++;}WRITE_to_SOCKET(iov, i); // 调用 sendmsgwhile(sgnode->sg_head->counter) { // block 放回 poolenqueue(&pool, dequeue(sgnode->sg_head));}enqueue(&batch_pool, sgnode); // sgnode 放回容器 pool}return NULL;
}
socket sendmsg 可如上批处理,recvmsg 却不行,因为需要分割 IP 报文,事先并不知道 IP 报文长度,而这需要先 recv 2 字节 len,再 recv recv len 字节 IP 报文,这非常低效。recv batch 处理的唯一方式是一次性读取足够的字节,在外解析成 IP 报文并放入 block:
buf = malloc((MTU + 2) * NUM);
...
len = recv(sock_fd, buf, (MTU + 2) * NUM - MTU);
...
for_each_len_pkt(...) {MemoryBlock* block = dequeue(&pool);????WRITE_to_TUN(block)}
注意 ??? 处,block 自己有个 buffer,难道又要将从 recv 的连续 buffer 解析出的对应内容 memcpy 到 block 的 buuffer?这不就回到了老路。
其实不必,为 block 增加一个用法即可:
typedef struct MemoryBlock {union {char data[MTU + 2]; // read from tun 的用法char *pdata; // recv 解析的用法unsigned short data_len;} A;struct MemoryBlock *next;int flag; // 1-data, 0-指针
} MemoryBlock;
如此就可直接将 block 的 pdata 指向连续 buffer 的对应位置了,写 tun 时直接写入,整个过程在一个 thread 串行,也就无需任何互斥。
如果我正在基于 tun 做一个大得惊人的项目而不是在擦屁股,我或许会怂恿别人提两个派池:
- 让标准 read/write/send/recv 支持 buffer 回绕,毕竟 RingBuffer 不是真正的 Ring;
- 让 tun/tap 的 read/write 接口支持 batch 操作,一次获取多个 IP 报文 or Ether 帧;
涉及到服务端的客户端分发问题不细说,它无非就是将 tun 读出的 IP 报文发给某个客户端的 socket,为此需要多个从 IP 报文 hash 客户端 queue 的步骤。
整幅图景有了,非常容易实现,它的结构如下:
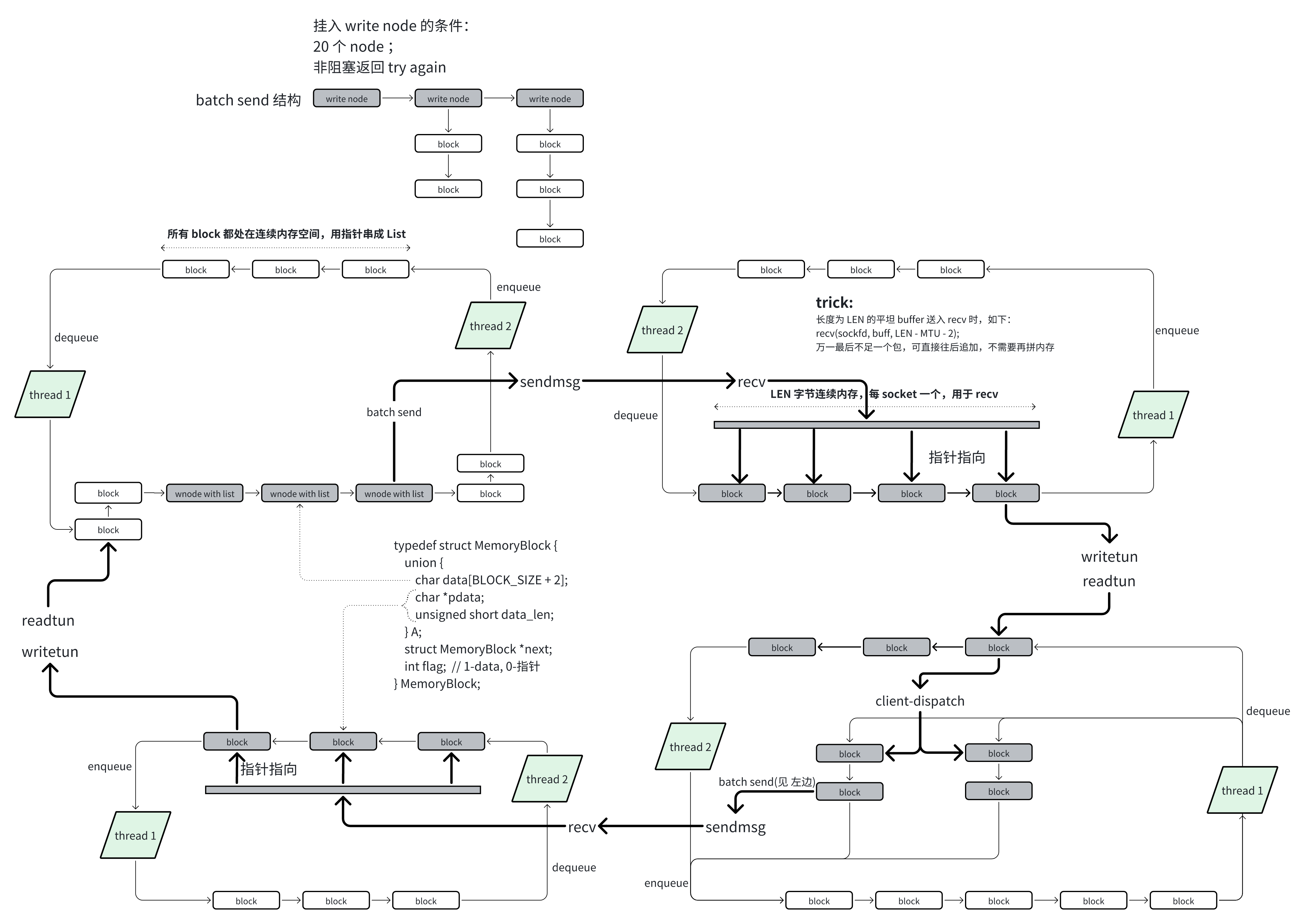
剩下的全是细节优化,有时它们看似极致却反而坏了事:
- pool 中节点的分配不使用 malloc 分配,整个 pool 位于连续内存空间,用指针组织成 queue,类似 malloc 实现的做法;
- 取消 batch pool,代之以 write socket 线程遍历最多 BATCH_SIZE 节点的方式,代价是需要锁定,或采用双队列;
- 客户端 pool 采用无锁 RingBuffer,直接支持 batch 读写,这个事最后做,因为它在服务端的 tun2socket 方向不能做;
相对于组织成 queue 的离散 MemoryBlock,平坦的无锁 RingBuffer 似乎效率更高,也容易被编程者想到,我也非常认可 BufferRing 的灵活性,可在任意处断界,只需要维护两个 pos 指针即可。
它不难实现,只是麻烦,因为要处理读写回绕问题,而大部分 read/write 调用均不支持回绕读写,所以需要特殊处理:
// v3-RingBuffer
size_t ring_buffer_write(RingBuffer *rb, const char *data, size_t len)
{size_t write_pos = atomic_load_explicit(&rb->write_pos, memory_order_relaxed);size_t read_pos = atomic_load_explicit(&rb->read_pos, memory_order_acquire);size_t free_space;if (write_pos >= read_pos) {free_space = rb->capacity - write_pos;if (read_pos > 0) {free_space += read_pos;}} else free_space = read_pos - write_pos;if (free_space < len)return 0;size_t first_chunk = rb->capacity - write_pos;if (first_chunk >= len) {// TODO tun readmemcpy(rb->buffer + write_pos, data, len);} else {// TODO tun edge read// 在边缘位置需要回绕时,仍需要通过 stack buffer 中转,再统一 memcpy 到 rbmemcpy(rb->buffer + write_pos, data, first_chunk);memcpy(rb->buffer, data + first_chunk, len - first_chunk);}size_t new_write_pos = (write_pos + len) % rb->capacity;atomic_store_explicit(&rb->write_pos, new_write_pos, memory_order_release);return len;
}size_t ring_buffer_read(RingBuffer *rb, char *out, size_t len)
{size_t read_pos = atomic_load_explicit(&rb->read_pos, memory_order_relaxed);size_t write_pos = atomic_load_explicit(&rb->write_pos, memory_order_acquire);size_t used_space;if (write_pos > read_pos)used_space = write_pos - read_pos;else if (write_pos < read_pos)used_space = rb->capacity - read_pos + write_pos;else return 0;if (used_space < len)len = used_space;size_t first_chunk = rb->capacity - read_pos;if (first_chunk >= len) {// TODO socket writememcpy(out, rb->buffer + read_pos, len);} else {// TODO socket edge write// 在边缘位置需要回绕时,仍需要通过 stack buffer 中转,再统一 memcpy 到 socketmemcpy(out, rb->buffer + read_pos, first_chunk);memcpy(out + first_chunk, rb->buffer, len - first_chunk);}size_t new_read_pos = (read_pos + len) % rb->capacity;atomic_store_explicit(&rb->read_pos, new_read_pos, memory_order_release);return len;
}
但特殊处理回绕读写并不是重点,重点在灵活性的相对意义。
相比平坦的内存 RingBuffer,采用稍微低效的 MemoryBlock queue 反而收益更大,别忘了 TCP 的教训?TCP 直接传输 byte stream,针对传输的优化就很难展开,因为 byte stream 太灵活了,没有 packetization,意味着需要适应所有 packetization。1990 年代的一个反例,ATM 以固定长度信元做传输单位,反而在当时以高效率著称。
再看我的 MemoryBlock,组织成 queue,是不是有点 ATM 信元的意思。对比离散 MemoryBlock 和连续 RingBuffer,你会看到 ATM 和 TCP 对数据组织方式抽象的差异,信元还是 byte stream:
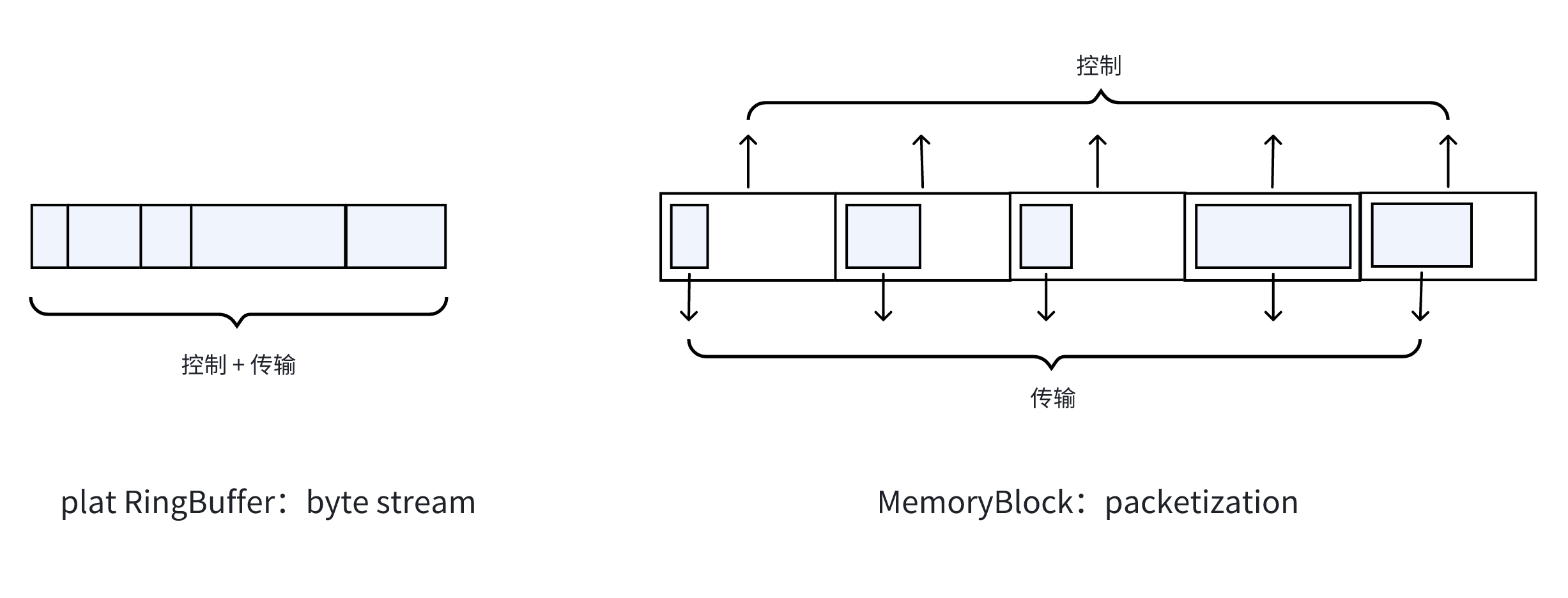
看起来存在内碎片和外碎片的问题,不打住的话,talk 总是没完没了,但却没意义。最后万变不离其宗地还是回到 packetization or no。
规范大小的控制块无论怎样都易于高效处理,比如映射和乱序重组。我恨不得将数据连同固定大小的 block 箱子一起用 UDP 序列化出去,但这就是一个新协议了。
事已至此,为什么不用 splice/tee,为什么不用 nginx stream proxy,总会有 100 个理由说 tun 不好,似乎切换的理由就为了摆脱 tun。也正因诸如此类的想法,出现了 Kernel OpenVPN,用户态 Wireguard,rust 版 Wireguard,总之就是为了摆脱某个被诟病的点,在内核,用户态,各种编程语言,服务器之间搬来搬去,最终效果就是摁下葫芦起了瓢的打地鼠游戏,得到些微不足道的性能,增加了功能实现的复杂性,丧失了功能的灵活性和稳定性,最近的一例,请看:
- QUIC for the kernel
- QUIC in Linux Kernel
大部分情况下是不需要优化性能的,即使要做,也要最后考虑。在设计之初,良好的设计只要性能足够,并且可扩展,如果性能不再满足需求,首要的不是优化它,而是替代它,因为这不是一个良好的设计,没有扩展性,任何需要后期投入大幅精力优化的设计都不是好的设计。
在做任何优化之前务必先进行必要性分析和性能分析。
如今风靡的是普遍优化,为优化而优化,部分原因在于云网络圈子的优化风气溢出了数据中心的围栏,以至于总有人想用 DPDK/XDP 优化家用路由器时抱怨网卡不支持,用他们并不关心的代价换取根本用不到的性能。
看一个 “应该做” 的优化,针对上述 v2-batch 代码,如何通过增加一个判断,删除处理二维 queue 的逻辑,使结构更清晰:
// v4-batch++
void* cpu1_task(void* arg)
{while(1) {if (batch_pool.counter > BATCH_SIZE) {MemoryBlock* block = dequeue(&pool);if (block) {READ_from_TUN(block);// 只要确保 pool 里保留 BATCH_SIZE 个 block,就可以放心回收enqueue(tun2socket, block); }} // else wait cpu2 signal}return NULL;
}int WRITE_to_SOCKET(struct iovec *iov)
{return 0;
}
void* cpu2_task(void* arg)
{struct iovec iov[BATCH_SIZE];while(1) {static int i = 0;MemoryBlock *block = dequeue(tun2socket);if (i < BATCH_SIZE && block)iov[i].iov_base = &block->data[2];iov[i].iov_len = (int)*(unsigned short *)&block->data[0];enqueue(&pool, block);i ++;} else if (i > 0){WRITE_to_SOCKET(iov, i); // 调用 sendmsgi = 0;}}return NULL;
}
最后,这类通过 tun 转发的结构难道不是非常适合用 DPDK 实现吗?即便仍然保留基本结构,用 Rust 重构一下肯定要比 C 更优雅的吧?总不能一点变化都没有。
浙江温州皮鞋湿,下雨进水不会胖。