日志系统(log4cpp)
日志系统的设计
日志系统的设计,一般而言要抓住最核心的一条,就是日志从产生到到达最终目的地期间的处理流程。一般而言,为了设计一个灵活可扩展,可配置的日志库,主要将日志库分为4个部分去设计,分别是:记录器、过滤器、格式化器、输出器四部分。
记录器(日志来源):负责产生日志记录的原始信息,比如(原始信息,日志优先级,时间,记录的位置)等等信息。
过滤器(日志系统优先级):负责按指定的过滤条件过滤掉我们不需要的日志。
格式化器(日志布局):负责对原始日志信息按照我们想要的格式去格式化。
输出器(日志目的地):负责将将要进行记录的日志(一般经过过滤器及格式化器的处理后)记录到日志目的地(例如:输出到文件中)。
下面以一条日志的生命周期为例说明日志库是怎么工作的。
一条日志的生命周期:
产生:info(“log information.”);
经过记录器,记录器去获取日志发生的时间、位置、线程信息等等信息;
经过过滤器,决定是否记录;
经过格式化器处理成设定格式后传递给输出器。例如输出“2018-3-22 10:00:00 [info] log information.”这样格式的日志到文件中。日志的输出格式由格式化器实现,输出目的地则由输出器决定;
5. 这条日志信息生命结束。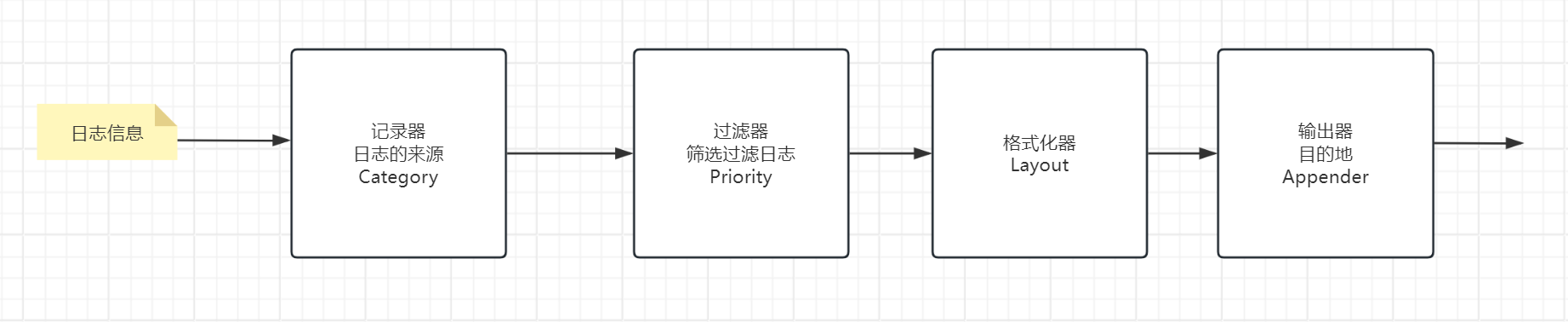
![]() 编辑
编辑
日志目的地(Appender)
https://log4cpp.sourceforge.net/
通过log4cpp官网查看常用类的信息
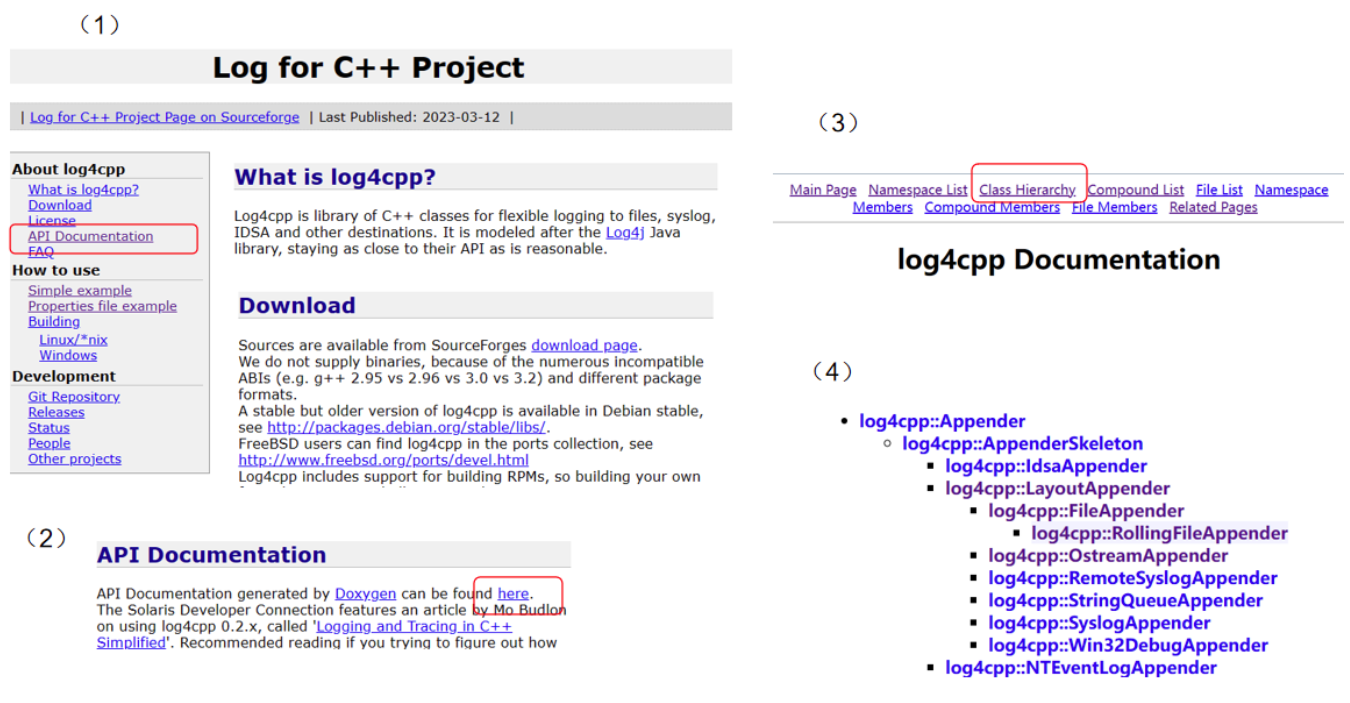
我们关注这三个目的地类,点开后查看它们的构造函数
OstreamAppender C++通用输出流(如 cout)
核心功能:将日志输出到 C++ 标准输出流(std::ostream),最常用的场景是输出到控制台(std::cout 或 std::cerr)。
特点:
灵活适配任何 std::ostream 类型的流对象(如控制台、自定义缓冲流等)。
无文件大小或滚动逻辑,日志会持续输出到指定流中(控制台会实时显示,若重定向到文件则类似普通文件输出)
// 输出到控制台(std::cout)
log4cpp::Appender* consoleAppender = new log4cpp::OstreamAppender("console", &std::cout);
// 输出到标准错误流(std::cerr)
log4cpp::Appender* errorAppender = new log4cpp::OstreamAppender("error", &std::cerr);FileAppender 写到本地文件中
核心功能:将日志直接写入本地磁盘文件,是最基础的文件日志输出组件。
特点:
日志会持续追加到指定文件中,文件大小会随着日志增多而无限增长。
无自动滚动或切割机制,若不手动处理,文件可能变得过大(如几十 GB),影响存储和读取。
// 输出到 "app.log" 文件,若文件不存在则创建,存在则追加内容
log4cpp::Appender* fileAppender = new log4cpp::FileAppender("file", "app.log");RollingFileAppender 写到回卷文件中
核心功能:日志写入文件时,会根据文件大小阈值自动切割(回卷)文件,避免单个文件过大。
特点:
可设置单个文件的最大容量(如 100MB),当文件达到该大小后,会自动重命名当前文件(如 app.log.1),并创建新的 app.log 继续写入。
可设置保留的历史文件数量(如最多保留 5 个历史文件),超过数量后会自动删除最旧的文件,节省磁盘空间。
// 参数:日志名、目标文件、单个文件最大字节数(100MB)、保留历史文件数(5个)
log4cpp::Appender* rollingAppender = new log4cpp::RollingFileAppender("rolling", // Appender 名称"app.log", // 基础文件名1024 * 1024 * 100, // 单个文件最大大小(100MB)5, // 最多保留 5 个历史文件false // 是否追加到现有文件(false 表示新建时覆盖)
);日志文件会按如下规律生成:
初始文件:app.log
达到阈值后:app.log 重命名为 app.log.1,新建 app.log
再次达到阈值:app.log 重命名为 app.log.2,app.log.1 变为 app.log.1(序号递增)
超过 5 个文件后,最旧的 app.log.5 会被删除。
适用场景:日志量较大、需要长期记录的场景(如生产环境服务),避免单个日志文件过大导致的存储和读取问题。
| 特性 | OstreamAppender | FileAppender | RollingFileAppender |
|---|---|---|---|
| 输出目标 | 标准输出流(如控制台) | 本地文件(单一文件) | 本地文件(自动切割为多个文件) |
| 文件大小管理 | 无(依赖输出流本身) | 无(无限增长) | 有(按大小阈值切割,保留历史) |
| 典型用途 | 开发调试、控制台输出 | 小规模日志、临时记录 | 生产环境、大规模长期日志 |
| 核心优势 | 灵活适配各类输出流 | 简单直接,无需配置切割 | 自动管理文件大小,节省存储空间 |
日志布局(Layout)
示例代码中使用的是BasicLayout,也就是默认的日志布局,这样一条日志最开始的信息就是日志产生时距离1970.1.1的秒数,不方便观察。
实际使用时可以用PatrrenLayout对象来定制化格式,类似于printf的格式化输出
%d 日期;日期可以进一步的设置格式,用花括号包围,例如%d{%H:%M:%S,%l}或者%d{%d/%m-%Y %H:%M:%S,%l}。如果不设置具体日期格式,则按如下默认格式被使用"1970-01-01 12:30:50,097"。
%c category信息;
%m 消息内容;
%n 换行符;
%p 优先级priority;
%r 自从layout被创建之后的毫秒数;
%R 自从1970年1月1日0时开始到目前为止的秒数;
%u 进程开始到目前为止的时钟周期数;
如果不设置,则默认是%m%n
使用new语句创建日志布局对象,通过指针调用setConversionPattern函数来设置日志布局
日志记录器(Category)
创建Category对象时,可以用getRoot先创建root模块对象,对root模块对象设置优先级和目的地;
再用getInstance创建叶模块对象,叶模块对象会继承root模块对象的优先级和目的地,可以再去修改优先级、目的地
补充:如果没有创建根对象,直接使用getInstance创建叶对象,会先隐式地创建一个Root对象。
子Category可以继承父Category的信息:优先级、目的地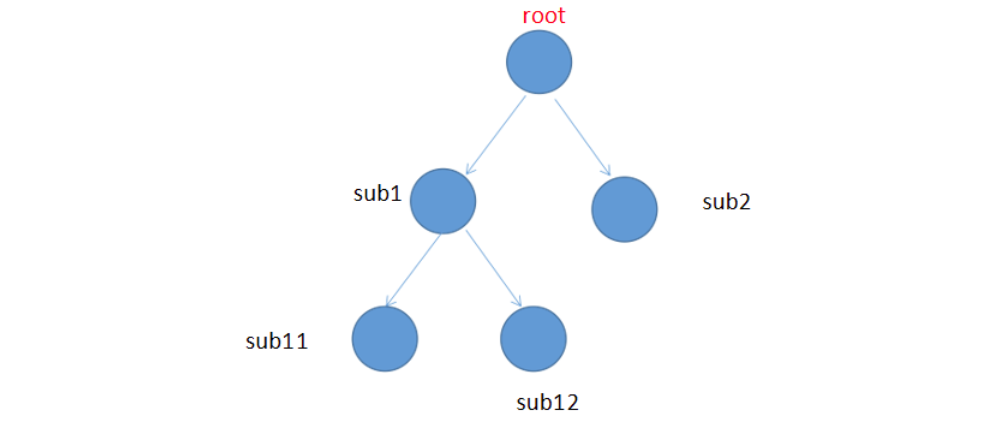
思考:为什么要创建叶模块对象呢??
如上图所示,叶模块对象可以继承根模块root对象的配置信息,只需要在root模块中进行配置,那么便可以实现全局的管理。另外也可以针对每个子模块分配做不同的配置以实现精细化管理。
日志优先级(Priority)
对于 log4cpp 而言,有两个优先级需要注意,一个是日志记录器的优先级,另一个就是某一条日志的优先级。Category对象就是日志记录器,在使用时须设置好其优先级;某一行日志的优先级,就是Category对象在调用某一个日志记录函数时指定的级别,如 logger.debug("this is a debug message") ,这一条日志的优先级就是DEBUG级别的。简言之:
日志系统有一个优先级A,日志信息有一个优先级B
只有B高于或等于A的时候,这条日志才会被输出(或保存),当B低于A的时候,这条日志会被过滤;
class LOG4CPP_EXPORT Priority {
public:typedef enum {EMERG = 0,FATAL = 0,ALERT = 100,CRIT = 200,ERROR = 300,WARN = 400,NOTICE = 500,INFO = 600,DEBUG = 700,NOTSET = 800 //这个不代表可以使用的优先级} PriorityLevel;//......
}; //数值越小,优先级越高;数值越大,优先级越低