基于 LDA 模型的安徽地震舆情数据分析
摘 要
为了提高地震相关舆情信息的获取效率与分析深度,本研究针对安徽地区地震事件中的社交媒体舆情数据,构建了一套基于LDA主题模型的舆情分析系统。通过Spring Boot、Vue、Python等多项技术手段,有效解决了舆情数据采集难、主题提取难以及可视化展示不足的问题,尤其是LDA(Latent Dirichlet Allocation)主题建模方法在舆情核心议题挖掘中的使用,使得地震事件中公众关注焦点得以自动识别与量化表达。
本系统后端采用Spring Boot搭建服务框架,负责数据处理逻辑与模型结果API接口的提供;前端则以Vue结合Axios构建动态页面,实现与后端的数据交互;Python语言作为建模工具,结合Gensim与Scikit-learn完成文本清洗、向量化及主题分布建模,最终借助ECharts对主题分布、关键词词云与情绪趋势等结果进行可视化呈现。
本研究说明了主题建模与前后端联动架构在地震舆情分析中的可行性与有效性,对于公共突发事件的信息应对策略制定具有一定的借鉴意义。同时也表明,LDA模型与自然语言处理技术在灾害类舆情挖掘与智能预警等方面具有广泛的应用前景。
关 键 词:LDA 主题模型、地震舆情分析、Spring Boot、Vue、CSV 数据集
ABSTRACT
In order to improve the efficiency of obtaining earthquake related public opinion information and the depth of analysis, this study constructed a public opinion analysis system based on LDA theme model for social media public opinion data in earthquake events in Anhui region. Through various technical means such as Spring Boot, Vue, Python, etc., the problems of difficult public opinion data collection, difficult topic extraction, and insufficient visualization display have been effectively solved. In particular, the use of LDA (Latent Dirichlet Allocation) topic modeling method in mining core public opinion issues has enabled the automatic identification and quantitative expression of public attention focus in earthquake events.
The backend of this system adopts Spring Boot to build a service framework, responsible for providing data processing logic and model result API interfaces; The front-end uses Vue combined with Axios to build dynamic pages and achieve data interaction with the back-end; Python language is used as a modeling tool, combined with Gensim and Scikit learn to complete text cleaning, vectorization, and topic distribution modeling. Finally, ECharts is used to visualize the results of topic distribution, keyword clouds, and emotional trends.
This study demonstrates the feasibility and effectiveness of theme modeling and front-end back-end linkage architecture in earthquake public opinion analysis, which has certain reference significance for the formulation of information response strategies for public emergencies. It also indicates that the LDA model and natural language processing technology have broad application prospects in disaster related public opinion mining and intelligent early warning.
KEY WORDS: LDA Theme Model, Earthquake Public Opinion Analysis, Spring Boot, Vue, CSV Dataset
目 录
1 绪论
1.1 研究背景和意义
1.1.1 研究背景
1.1.2 研究意义
1.2 研究现状
1.2.1 国外研究现状
1.2.2 国内研究现状
1.2.3 研究现状总结
1.3 系统设计思路
1.4 设计方法
2 相关技术介绍
2.1 LDA模型概述
2.2 LDA模型的数学原理
2.2.1 主题建模基本思想
2.2.2 朴素贝叶斯思想与条件独立性假设
2.2.3 LDA模型的概率生成过程
2.2.4 参数含义与符号解释(如 α、β、θ、z、w)
2.3 2.3 LDA模型推理与求解方法
2.3.1 吉布斯采样(Gibbs Sampling)
2.3.2 变分推断(Variational Inference)
2.3.3 选用的推理方法与原因
2.4 LDA模型在文本分析中的应用流程
2.4.1 文本预处理
2.4.2 文档-词矩阵构建
2.5 LDA模型的优势与局限性
3 总体工作流程
3.1 需求分析
3.2 非功能需求分析
3.3 可行性分析
3.3.1 时间可行性
3.3.2 经济可行性
3.3.3 技术可行性
3.4 LDA主题建模与优化
3.4.1 LDA模型原理与应用场景
3.4.2 模型参数设置与训练过程
3.4.3 模型稳定性与主题数量选择
3.5 主题识别与舆情解读
3.5.1 主题结果输出与关键词提取
3.5.2 舆情主题内容分析
4 数据采集与预处理
4.1 数据采集方法
4.2 数据来源与样本选择
4.2.1 数据清洗与去重
4.3 文本预处理技术
4.3.1 分词与词性标注
4.3.2 去停用词处理
4.3.3 特征提取与向量化
5 数据采集与构建
5.1 总体架构
5.2 模块划分
5.3 技术选型与工具支持
5.3.1 技术选型
5.3.2 工具支持
5.4 LDA模型应用与实现
5.4.1 数据预处理与清洗
5.4.2 LDA模型训练与优化
6 数据分析与预测
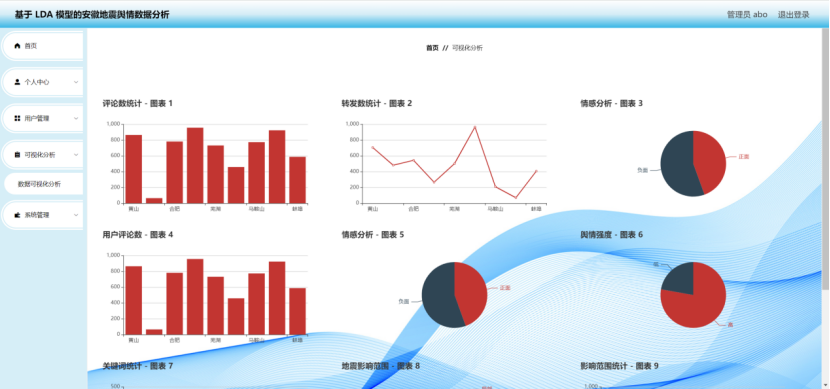
6.1 首页页面
6.2 登录页面
6.3 用户管理页面
6.4 可视化分析页面
7 总结
参考文献
致 谢
近年来,随着社交媒体和互联网技术的快速发展,公众对突发灾害事件的关注度不断提升,尤其是地震等自然灾害往往会在短时间内引发广泛的社会讨论。安徽省作为我国地震活动较为活跃的地区之一,虽然破坏性地震相对较少,但每当地震发生时,社交媒体平台(如微博、微信、新闻门户等)都会迅速形成大量的舆情信息。这些舆情不仅包含公众的情绪反应、信息传播路径,还可能涉及谣言传播、政府应对措施的评价等内容。因此,对安徽地震舆情数据进行有效的分析,对于提升政府危机管理能力、优化地震应急响应机制以及引导舆论方向具有重要的现实意义。
目前,文本挖掘技术在舆情分析领域得到了广泛应用,其中LDA(Latent Dirichlet Allocation,潜在狄利克雷分配) 主题模型是一种常用的无监督文本分析方法,能够自动提取文本数据中的潜在主题,帮助研究人员理解舆论的核心内容。然而,传统舆情分析大多基于关键词统计或情感分类,难以有效挖掘舆情的深层次结构。因此,结合LDA 主题建模方法,构建一套针对安徽地震舆情的智能分析系统,能够为政府、媒体和研究机构提供更精准的舆情监测和分析工具。
本研究采用 Spring Boot + Vue 作为系统开发架构,后端基于 Spring Boot 处理数据存储、模型计算和 API 提供,前端采用 Vue 进行交互界面设计,并通过 Axios 实现前后端数据通信。此外,数据来源于 CSV 格式 的舆情数据集,系统能够自动读取、清洗和分析文本数据,并可视化展示地震相关的舆情主题、情感倾向和传播趋势。
(1)提升地震舆情分析能力
本研究通过 LDA 主题模型对安徽地震舆情数据进行深度挖掘,能够有效识别舆论热点、情绪变化趋势以及社会关注的焦点问题。相比传统的关键词分析方法,LDA 主题建模能够从大量无序文本中自动提取主题,提高舆情分析的准确性和可解释性,为政府和媒体提供更有价值的参考信息。
(2)优化地震应急管理
地震发生后,舆情的快速传播往往影响公众情绪和社会稳定。通过本研究构建的舆情分析系统,政府可以及时了解公众对地震事件的态度,掌握社会情绪的变化趋势,进而优化危机应对策略,采取更有针对性的引导措施。例如,当系统检测到负面情绪占比上升时,政府可以加强正面宣传、辟谣和舆论引导,防止社会恐慌的扩大。
(3)推动智能化舆情监测系统建设
本研究采用 Spring Boot 和 Vue 进行系统开发,实现了前后端分离、可视化展示和自动化分析,提高了系统的可扩展性和用户体验。通过构建一套智能化的舆情监测系统,不仅可以应用于地震舆情分析,还可推广至其他自然灾害、社会事件等领域,进一步推动智能化舆情监测技术的发展。
(4)丰富灾害舆情研究的方法论
当前国内地震舆情研究大多采用传统的统计分析方法,而本研究引入 LDA 主题建模和数据可视化技术,使得地震舆情研究更加系统化、自动化和智能化。同时,本研究提供了一种基于大数据和人工智能的舆情分析思路,为未来灾害舆情研究提供了重要的理论和技术支持。
综上,本研究不仅对安徽地震舆情分析具有重要的现实意义,也可为全国范围内的地震舆情监测提供参考,为政府部门、媒体机构以及学术界在舆情管理和应急响应方面提供数据支撑和决策依据。
在全球范围内,地震舆情分析已成为灾害管理和社会科学研究的重要方向。许多研究机构利用文本挖掘、机器学习等方法,对社交媒体数据进行地震相关舆情研究,以提升政府应对地震灾害的能力。
(1)美国
美国地质勘探局(USGS)联合多所高校开发了“Did You Feel It?”(DYFI)系统,该系统利用社交媒体数据收集地震发生后的公众反馈。研究人员使用LDA 主题建模和情感分析方法,对 Twitter 等社交平台上的地震相关信息进行分析,发现公众的关注点主要集中在震级、破坏情况和政府应对措施上。此外,针对2019 年加利福尼亚地震的舆情演变,研究团队结合 LDA 主题分析与预训练语言模型,提出了一种基于社交媒体的舆情预警机制,以提高政府响应速度和信息透明度。
(2)日本
日本气象厅与多家研究机构合作,通过LDA 主题建模分析了2011 年东日本大地震后社交媒体上的舆论发展。研究发现,震后 30 分钟内,社交媒体上迅速形成多个主要话题,包括“救援需求”“核电站事故”和“政府应对”等。这项研究为政府优化灾害管理策略提供了数据支持,并推动了社交媒体在地震灾害管理中的应用。
(3)欧洲
英国学术机构对2021 年希腊克里特岛地震的社交媒体舆情进行了研究,利用LDA 主题分析和情感计算方法,对 Twitter 上 30 万条相关推文进行分析。研究结果表明,公众情绪在震后 24 小时内经历了“震惊—焦虑—恢复”的动态变化。这项研究进一步验证了主题建模在灾害舆情研究中的有效性,并为政府优化灾害信息传播策略提供了理论支持。
近年来,我国在地震舆情分析方面的研究逐步深入,多个机构和高校开始采用大数据分析、LDA 主题建模等方法,研究地震相关的舆情传播特征及公众情绪变化。
(1)地震部门的舆情监测
中国地震局相关研究机构开发了地震舆情监测系统,利用 LDA 主题建模方法分析微博、微信等社交媒体上的地震信息。在2021 年云南漾濞地震的研究中,该系统分析了超过 50 万条微博数据,提取出公众关注的核心问题,如“震中位置”“伤亡情况”和“政府救援进展”。该系统的研究成果为政府和媒体提供了数据支持,优化了地震信息传播策略。
(2)高校对社交媒体地震舆情的研究
国内多所高校针对2019 年四川长宁地震期间的微博数据进行了研究,采用 LDA 主题建模方法进行文本挖掘,并结合 TF-IDF 关键词提取技术,发现地震舆情在事件发生后 3 小时内形成多个主要话题,包括“震感体验”“官方通报”和“谣言传播”。研究表明,社交媒体上的舆论热点具有明显的时间演变规律,突出了及时监测和引导舆情的重要性。
(3)谣言传播分析
针对2022 年泸定地震期间的社交媒体数据,国内某研究机构采用 LDA 主题建模结合预训练语言模型,对 30 万条微博数据进行了分析。研究发现,震后 6 小时内,谣言信息占比达到 18%,主要涉及“误报震级”“夸大伤亡数据”和“虚假救援信息”。研究进一步揭示了地震谣言的传播模式,并提出了基于深度学习的舆情监测和谣言检测方案。
综合国内外研究现状,地震舆情分析已成为灾害管理的重要研究方向,LDA 主题建模在提取舆论热点、监测情绪演变方面展现出良好的应用价值。然而,仍存在以下研究空白和挑战:
时效性问题:当前研究主要聚焦震后舆情分析,而如何提升舆情分析的实时性仍然是一个挑战。
多模态数据融合:现有研究多基于文本数据,如何结合图像、视频等多种数据类型进行综合分析尚待探索。
谣言检测的精准性:LDA 主题建模虽然可以识别谣言传播主题,但如何结合深度学习进一步提高谣言检测的准确率仍是研究热点。
本研究在借鉴国内外先进研究成果的基础上,针对安徽地震舆情,构建基于LDA 主题模型的分析系统,并结合Spring Boot + Vue 构建可视化平台,以提高舆情分析的智能化和实时性。研究成果将有助于理解安徽地区地震舆情的传播规律,并为政府及相关机构提供科学决策支持,优化地震灾害应急管理策略。
本研究构建了安徽地震舆情分析系统,采用 Spring Boot 作为后端框架,Vue 作为前端框架,实现数据采集、处理、分析及可视化展示。系统设计主要包括四个方面。
在数据采集与整理阶段,系统通过网络爬取或接口获取微博、新闻等平台上的地震相关信息,并以 CSV 格式存储。数据经过筛选、去除无关内容、合并同类信息等处理,以确保分析内容的准确性和完整性。
在信息分类方面,系统对整理后的文本内容进行归类,提取公众关注的核心话题,如灾情描述、政府应对、救援进展等。通过合理设定分类规则,确保主题划分清晰,使不同类别的信息可以更直观地展现。
在系统架构上,后端采用 Spring Boot 进行数据存储、分类计算和接口开发,前端使用 Vue 结合 Axios 访问后端接口,实现内容的动态更新和展示。该架构设计提高了整体运行效率,并保证了后续功能扩展的灵活性。
最后,在展示和分析部分,系统通过图表方式呈现不同主题的分布情况、信息传播趋势以及高频词汇,使舆情变化更加直观。同时,提供筛选和查询功能,支持按时间、关键词等条件查看相关信息,方便用户追踪和分析不同阶段的舆情发展。本系统能够有效整理和分析安徽地震舆情,为相关部门的决策和应对措施提供参考依据。
在研究的过程中,不同的方法适用于不同的需求场景,选择恰当的方法是确保研究质量的重要环节。研究方法的正确使用能够提高研究的科学性和可靠性,使研究结论更加准确。下面列举本研究在开展过程中采用的几种方法:
资料收集法:在研究过程中,参考和整理已有的相关资料是必不可少的。国内外关于地震舆情的研究已有较长时间积累,每个阶段都形成了一定的理论体系和实践经验,并以论文、报告等形式存档。通过查阅这些文献,可以获取已有的研究成果和相关案例,为本研究提供理论依据。同时,参考前人的研究可以减少重复性工作,提高研究效率,类似于数学问题的公式推导,可以直接使用成熟的方法,而不必重新验证其合理性,从而加快研究进度。
对比分析法:比较不同的数据特征和研究方法,有助于理解研究对象的差异和共性。在本研究中,对比分析主要用于不同地震事件的舆情演变趋势、不同社交媒体平台上的信息传播规律,以及现有地震舆情分析系统的优缺点。通过这样的对比,可以明确本研究的创新点,同时发现现有研究的不足,以便优化分析方法,提高系统的适用性和实用价值。
调研法:调研是获取实际需求和验证研究成果的重要手段。舆情数据的收集和分析不仅需要技术支撑,也需要结合社会实际情况进行需求分析。例如,不同群体对地震信息的关注点可能不同,政府机构可能更关注信息的真实性和传播速度,而公众可能更关心地震的影响范围和救援进展。因此,通过调研,了解不同用户的关注重点,有助于调整分析方向,使研究成果更具参考价值。此外,调研还能用于评估系统的可用性,例如界面的友好性、信息的呈现方式等,以确保最终系统的实用性。
实验验证法:研究成果的可靠性需要通过实验来验证。在本研究中,实验验证主要用于评估 LDA 模型的效果,如主题分类的准确性、关键词提取的合理性等。通过对比不同参数设置下的分析结果,可以优化模型,提高分析的准确性和稳定性。此外,通过在不同的数据集上测试模型,可以验证其适用范围,确保研究成果的泛化能力。
综合运用以上方法,能够确保本研究在数据收集、分析对比、用户需求调研以及实验验证等多个环节的科学性,从而提高安徽地震舆情数据分析的有效性,为政府和相关部门提供更具价值的决策支持。
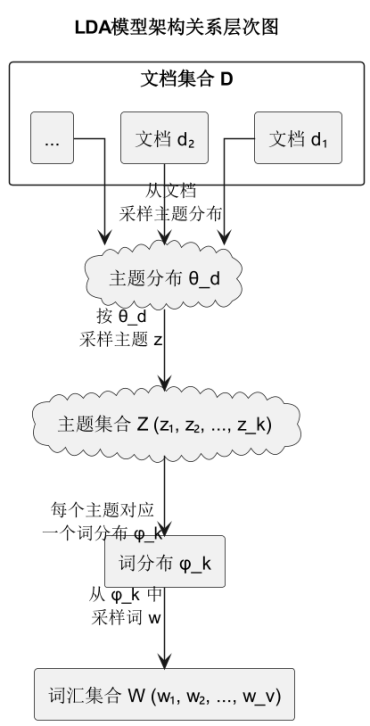
LDA模型是一个强大的主题建模工具,它的核心思想是从大量的文档中发现隐藏的主题,并揭示每个文档和主题之间的关系。简单来说,它通过数学模型来解释文档中出现的词汇,并尝试为每个文档分配一个或多个主题。在 LDA 中,把每个文档看作是由不同主题的词汇混合而成的,而每个主题则由一组词汇的分布所定义。
通过 LDA 模型,首先对每个文档生成一个主题分布(θ_d),然后从这个分布中随机选择一个主题。接着,选定的主题会根据其词分布(φ_k)来生成词语。最终,这些词语组成了文档的内容。
在实际应用中,LDA模型常常用于从大量的文本数据中提取潜在的主题,帮助更好地理解文档的结构和内容。在地震舆情分析中,LDA可以帮助从微博、新闻等数据中挖掘出公众关注的核心问题,从而为政府部门提供及时有效的信息支持。通过这种方式,不仅能理解舆论的动态,还能帮助预测未来可能的舆情热点。
主题建模的基本思想,其实就是试图从一大堆杂乱无章的文本中,自动找出那些“隐含的主题”。可以把它理解成一种“看透表象”的方法。比如收集了成千上万条关于安徽地震的微博或新闻报道,虽然每个人的表达方式不同,但背后总有一些共通的内容,比如“地震预警”“人员伤亡”“救援物资”“心理安抚”等。
主题建模做的事情就是:不管大家怎么说,它都能从中发现这些共通点,也就是“主题”。它不会看你具体用的是哪个词,而是分析词在不同文档中出现的频率和位置,从而判断哪些词经常一起出现,可能代表一个主题。比如“震中”“烈度”“余震”老是一起出现,那么模型就会把它们归到一个“震情信息”的主题里。
主题建模最常用的工具就是LDA模型,它可以帮把每篇文章拆解成几个不同主题的组合,同时也能看出每个主题主要说的是哪些词。这种方法特别适合处理大量文本数据,像这种地震舆情分析,就非常合适。
朴素贝叶斯的核心思想其实很简单,就是通过已有的数据去“猜”一个新东西属于哪个类别,它背后的逻辑是“贝叶斯定理”。举个例子,如果看到一条微博,里面提到了“余震”“救援”“震中”等词,就可以根据这些词出现的概率,来判断这条微博更可能属于“地震灾情”这个主题。
它之所以叫“朴素”,是因为它有个前提假设:在已知分类的前提下,所有特征(比如这些关键词)彼此之间是“独立”的。也就是说,模型默认“震中”出现不会影响“余震”出现的概率。虽然现实中这些词往往有关联,但这个假设能大大简化计算过程,让分类效率更高。
这个“条件独立性假设”虽然听起来有点理想化,但在实际中,比如文本分类、垃圾邮件识别、情感分析等场景下,效果却往往很不错。在安徽地震舆情分析中,也可以利用朴素贝叶斯对不同类型的舆论内容进行快速初步分类,为后续深入的主题建模和情感分析打基础。
LDA 模型的生成过程其实可以理解成“先选主题,再选词”。它一开始会设定两个参数,分别控制每篇文章偏向哪些主题、每个主题里又包含哪些词。对一篇具体的文档来说,模型会先根据某个概率分布选出主题,然后再根据这个主题去选一个词。比如在分析安徽地震的舆情时,如果一条微博被判断偏向“救援”这个主题,那么里面更有可能出现像“物资”“官兵”“转移”这样的词。整个过程是“主题先行,词语跟着主题走”,也就是说,文章中每个词的背后其实都有个隐含的主题。这个过程重复进行,就能让模型学会哪些词常常一起出现,代表一个主题,而哪些主题又在哪些文章里频繁出现。这就是它能从海量舆情中梳理出主题脉络的原因。虽然模型内部用的是数学概率,但整个思路很贴近人对文章内容的理解方式。
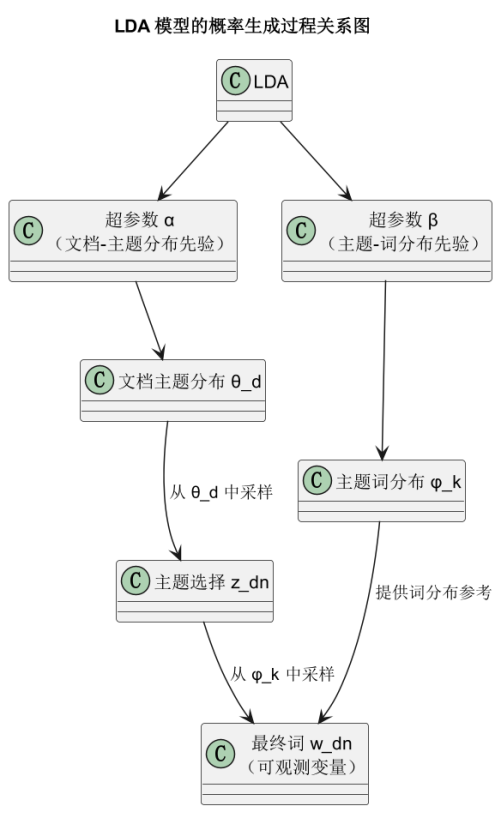
LDA 模型中,每个参数都有其独特的作用。α 控制着每篇文档中主题的分布。如果 α 值较小,意味着每篇文档只会集中在几个主题上;如果 α 值较大,则文档可能会包含更多的主题。β 则控制每个主题中的词汇分布,值小代表每个主题只包含少数关键词,而值大则意味着主题的词汇更加广泛。θ 是文档的主题分布,它描述了文档中各个主题的比例。z 是每个词的主题分配,LDA 会为文档中的每个词选择一个主题。最后,w 就是文档中实际的词汇,模型根据这些词来推断文档的主题结构。通过这些参数的相互配合,LDA 模型能够从大量文档中提取出潜在的主题,为理解文本提供有价值的信息,尤其在分析像安徽地震舆情这样的文本数据时,它可以帮助识别公众的关注点。
| 符号 | 含义 | 描述 |
| α | 文档-主题分布的先验参数(Hyperparameter) | 控制文档中主题分布的稀疏程度。较小的 α 值意味着文档偏向少数几个主题。 |
| β | 主题-词分布的先验参数(Hyperparameter) | 控制每个主题中词的分布的稀疏程度。较小的 β 值意味着每个主题只包含少数几个词。 |
| θ | 每篇文档的主题分布(Topic distribution) | 对于每篇文档,θ 表示它对不同主题的分布情况,通常是一个概率分布。 |
| z | 主题分配(Topic assignment) | 对于文档中的每个词,z 表示该词属于哪个主题。每个词有一个单独的主题分配。 |
| w | 可观察词汇(Words) | 文档中实际出现的词汇,LDA 模型通过这些词来推断文档的主题分布。 |
变分推断(Variational Inference,VI)是一种用于在复杂模型中进行推断的近似方法。它的核心思想是通过引入一个简单的分布来近似真实的后验分布,从而避免直接计算后验分布所需的高计算量。特别是在 LDA 模型中,计算文档的主题分布、词的主题分配等需要涉及大量的计算,直接求解会非常耗时。变分推断通过引入一个“变分分布”来替代这些复杂的后验分布,进而加速推断过程。
具体来说,变分推断的过程包括两个关键步骤:首先,选定一个简单的分布(如高斯分布或其他可解的分布)来近似目标后验分布;然后,通过最小化变分分布与真实后验分布之间的差异,通常是通过最大化证据下界(ELBO,Evidence Lower Bound)来实现。这种方法的优势是计算效率高,能够在大规模数据中迅速推断出模型的参数。
对于安徽地震舆情分析,变分推断可以帮助在大量的微博、新闻等文本数据中,快速识别出不同主题的分布,特别是在文本量庞大的情况下,变分推断使得 LDA 模型能够在有限的时间内完成对复杂数据的推断,从而支持舆情分析和决策支持。
在选择推理方法时,变分推断和吉布斯采样各有优缺点。变分推断适合大规模数据集,它通过近似方法在较短的时间内给出主题分布的估计,特别适合像安徽地震舆情这种大规模的文本数据分析。虽然变分推断的结果是近似的,但在计算效率方面有着明显优势,可以帮助快速从大量文本中提取主题。
另一方面,吉布斯采样精度更高,适用于数据量较小的情况。通过反复采样,它能够更准确地估计每个文档的主题分布,适合一些对结果精度要求较高的分析场景。不过,吉布斯采样的计算开销大,收敛速度较慢,所以在面对庞大的舆情数据时,就不太适用了。
最终,选择变分推断作为主推理方法,是因为它能在短时间内处理大量数据,满足实际应用中对效率的需求。吉布斯采样则用于较小数据集的精细化分析,以保证结果的准确性。
| 推理方法 | 描述 | 优点 | 缺点 | 选择原因 |
| 变分推断 | 通过引入变分分布来近似后验分布,采用优化方法求解近似结果。 | 计算效率高,适合大规模数据,能在较短时间内完成推断。 | 对结果是近似的,可能会有一定的误差;优化过程可能较为复杂。 | 数据量大,要求较高的计算效率;适合大规模舆情数据分析。 |
| 吉布斯采样 | 基于马尔可夫链蒙特卡洛(MCMC)方法,逐步对主题进行采样,得到后验分布的近似。 | 精度高,可以准确地估计后验分布,适用于较小数据集。 | 计算开销大,收敛速度较慢;需要多次采样才能达到较好的效果。 | 在数据量较小或对精度要求较高时使用,适用于深入分析特定数据集。 |
在进行安徽地震舆情数据分析时,文本预处理是必不可少的一步。首先,需要清洗数据,去掉一些无关的部分,比如网页标签、广告信息或多余的符号。接着,进行分词处理,将每条舆情数据分解成单个的词语或短语,这样才能有效地分析出主题。对于中文文本,常用的分词工具有jieba,它能帮助将句子按词语切分开。
此外,还需要去除一些停用词。停用词是那些对文本分析没有实际意义的常见词,比如“的”、“是”等,这些词会干扰对主题的提取。然后,对每个词进行标准化处理,例如将同义词归一化,统一词汇的表示。
最后,还可能需要对词进行词干化或词形还原,确保相同词汇形式的词被视为同一词语。通过这些处理步骤,能够把原始的舆情数据转化为适合主题模型分析的格式,从而更好地提取出潜在的主题信息。
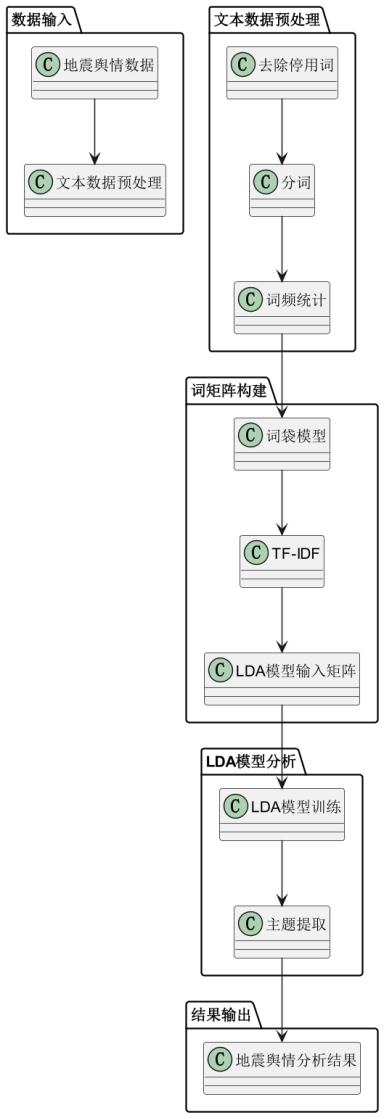
从输入的地震舆情数据开始,通过一系列文本预处理步骤对数据进行整理,包括去除停用词、分词处理和词频统计。经过这些处理后,生成了词袋模型和TF-IDF等特征,构建了用于LDA模型分析的输入矩阵。接下来,通过LDA模型进行训练,提取出地震舆情中的潜在主题。最后,论文输出了分析结果,揭示了舆情的主要话题和趋势。整个流程展示了如何利用LDA模型从庞大的舆情数据中提取出有价值的信息,帮助更好地理解地震相关的公众情绪和舆论走向。
-
- LDA模型的优势与局限性
LDA模型(Latent Dirichlet Allocation)作为一种常用的主题模型,在安徽地震舆情数据分析中有其独特的优势。首先,LDA能够自动从大量文本中发现潜在的主题结构,减少了人工标注的工作量。对于地震舆情数据这样庞大的信息量,LDA通过概率模型,能有效提取出文本中频繁出现的主题,帮助快速了解公众对地震的关注点和情绪倾向。其次,LDA具有较强的可解释性,分析结果可以清晰地反映出每个主题的关键词,便于研究者深入理解舆情变化背后的原因。
然而,LDA模型也并非完美无缺。它的局限性主要体现在几个方面。首先,LDA依赖于大量的预处理工作,如分词、去停用词等,且在面对一些复杂文本或不规范的舆情数据时,可能会受到影响。其次,LDA假设每个文档属于多个主题,这对于一些高度集中的舆情事件来说,可能并不完全准确。最后,LDA模型的参数选择也很关键,错误的参数设置可能导致结果不稳定或不符合实际情况,需要反复调试和优化。
因此,虽然LDA模型能够为安徽地震舆情数据分析提供有效的支持,但在应用时仍需注意其局限性,并结合其他方法进行改进和补充。