【22-决策树】
决策树和树集成 decisiontrees and tree ensembles
决策树定义
决策树的工作原理
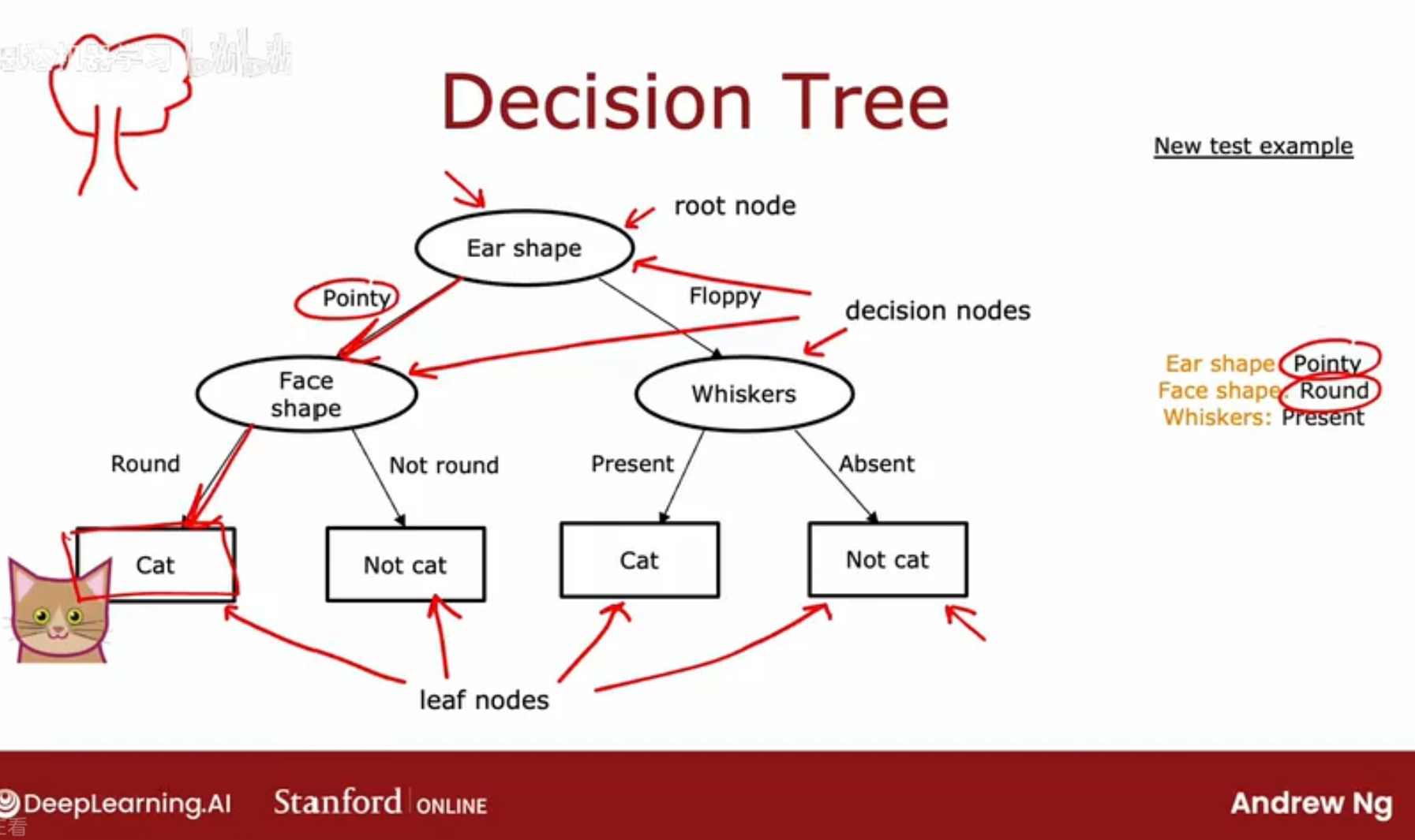
例子:猫分类,在一家猫咪收留中心,需要训练一个分类器快速地识别一个动物是否是猫;
输入特征:耳朵形状(尖的pointy 耷拉的floppy);脸形状;胡须whiskers;输出:是否是猫;

什么是决策树?
使用决策树学习算法对数据集进行训练后得到的模型,看起来像一棵树;树最顶端的叫根节点;椭圆型的叫决策节点,矩形框叫叶节点,用作输出预测结果;
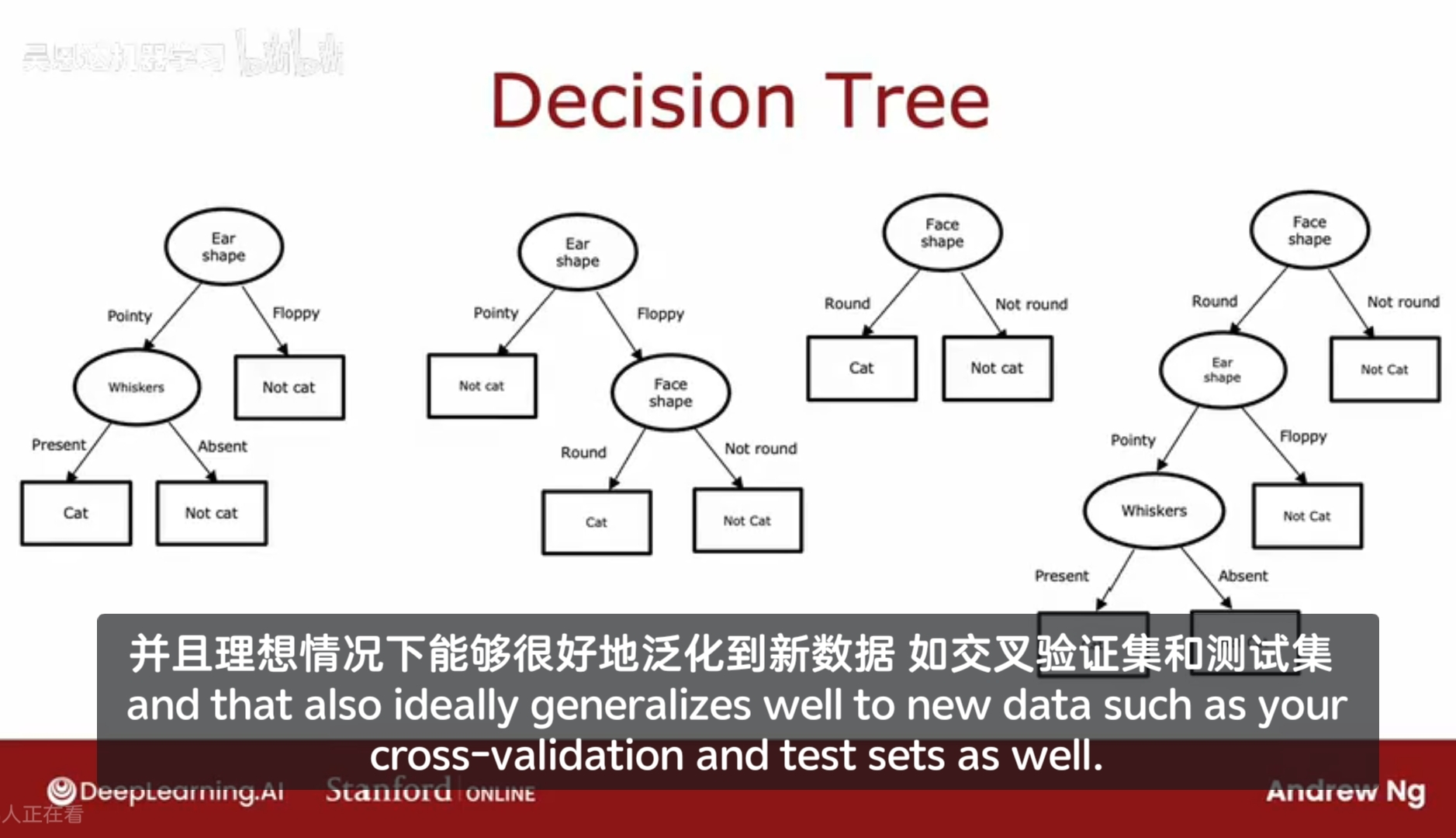
除了示例的决策树,实际上还存在其他很多种决策树,它们根据每种特征的值做不同的选择,走不同的分支;这些决策树有些在测试数据集上表现地好,有些表现地差。
所以决策树学习算法的任务是,从所有可能的决策树中,选择一个在训练集上表现最好,并且泛化能力较强的决策树。
如何让算法根据训练集学习一个特定的决策树?
决策树的训练
构建决策树
对于给定一个训练集,构建决策树有几个步骤
1、决定在根节点使用哪个特征,选择在子节点使用哪个特征,然后尽可能将示例数据集全部分开(cat & not cat);
如何选择特征来拆分数据集;选择那些尽可能能将猫和其他动物区分开来的特征;区分之后的纯度尽可能高;
决策树学习算法必须在耳朵形状、脸型、胡须之间做选择,

熵entropy,如何估计杂质以及最小化杂质;
2、何时停止划分?
当一个节点全部为猫/非猫;
当拆分节点会导致树达到最大深度;节点的深度:从根节点到达该节点所需的步数;
当提高纯度得分超过了阈值;
当节点的示例数量低于某阈值;
限制树的深度:确保树不会太大,便于管理;保持小规模,以避免过拟合;
在一个节点上如何划分
熵,entropy,描述节点不纯度的一种说法;
一组数据全是猫/全不是猫,则纯度很高;
p1:一组中猫占的比例;
当p1 = 0.5时,即一半一半时,不纯度最高;