零基础-动手学深度学习-10.3. 注意力评分函数

import math
import torch
from torch import nn
from d2l import torch as d2l10.3.1. 掩蔽softmax操作
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了在 9.5节中高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。 下面的masked_softmax函数 实现了这样的掩蔽softmax操作(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0(不是真的0,是很小很小的数字)。
#@save
def masked_softmax(X, valid_lens):"""通过在最后一个轴上掩蔽元素来执行softmax操作"""# X:3D张量,valid_lens:1D或2D张量if valid_lens is None:return nn.functional.softmax(X, dim=-1)else:shape = X.shapeif valid_lens.dim() == 1:## 1-D:每个 batch 元素一个长度 → 复制成每行一条valid_lens = torch.repeat_interleave(valid_lens, shape[1])
#把 [len0, len1, …] 扩展成 [len0, len0, …, len1, len1, …],让每一行 token 都拿到属于自己的有效长度值。else:## 2-D:已经 (batch, num_rows) → flatten 成 1-Dvalid_lens = valid_lens.reshape(-1)#就是一个2-1的flatten操作# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,value=-1e6)#核心操作在这 给你变形为最后一个维度前面全部flatten掉之后做上面说的替换return nn.functional.softmax(X.reshape(shape), dim=-1)为了演示此函数是如何工作的, 考虑由两个2*4矩阵表示的样本, 这两个样本的有效长度分别为2和3。 经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))输出:tensor([[[0.5980, 0.4020, 0.0000, 0.0000],[0.5548, 0.4452, 0.0000, 0.0000]],[[0.3716, 0.3926, 0.2358, 0.0000],[0.3455, 0.3337, 0.3208, 0.0000]]])#同样,也可以使用二维张量,为矩阵样本中的每一行指定有效长度。masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))输出:tensor([[[1.0000, 0.0000, 0.0000, 0.0000],[0.4125, 0.3273, 0.2602, 0.0000]],[[0.5254, 0.4746, 0.0000, 0.0000],[0.3117, 0.2130, 0.1801, 0.2952]]])10.3.2. 加性注意力

下面的广播扩展是真的非常秒的思路
#@save
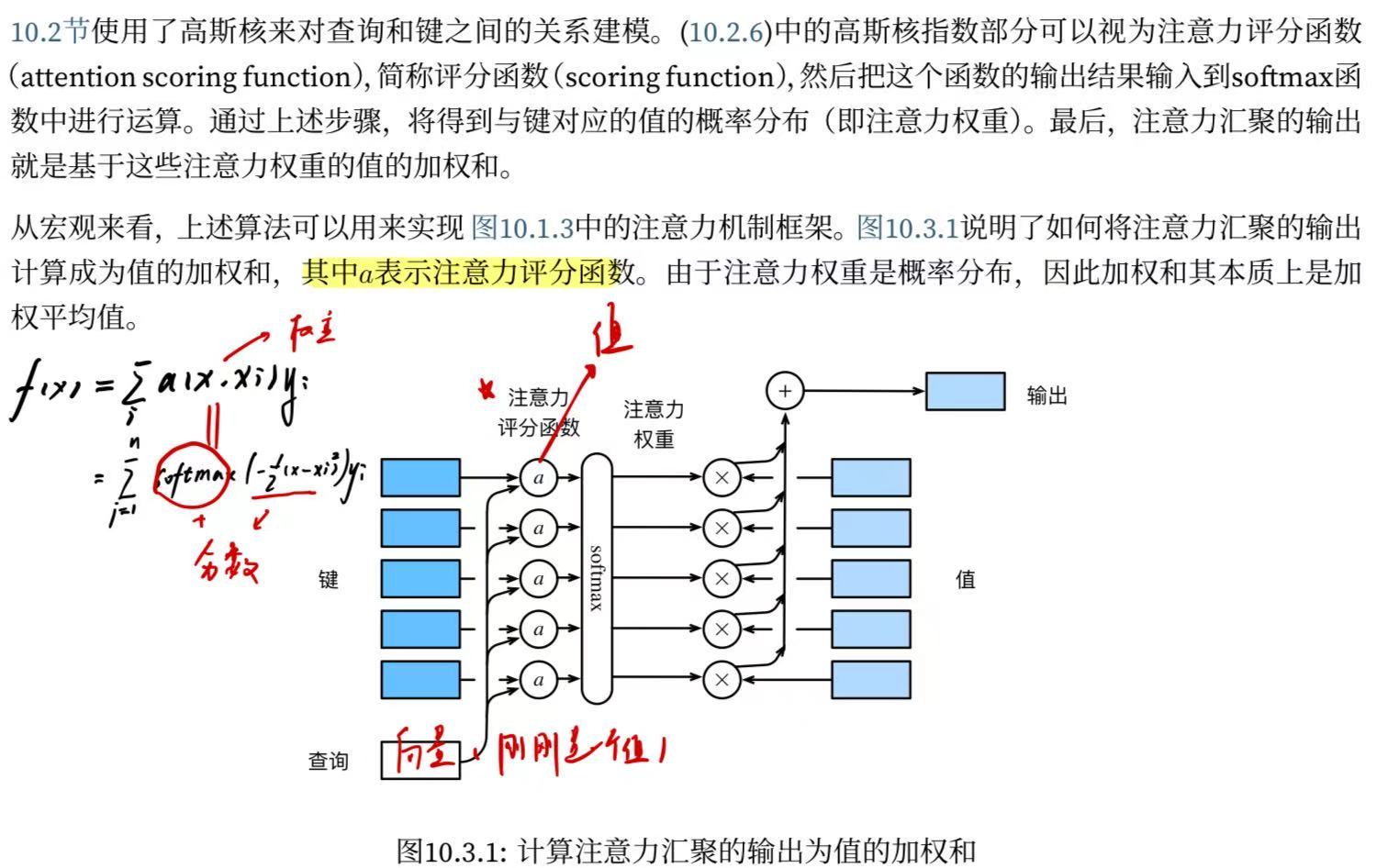
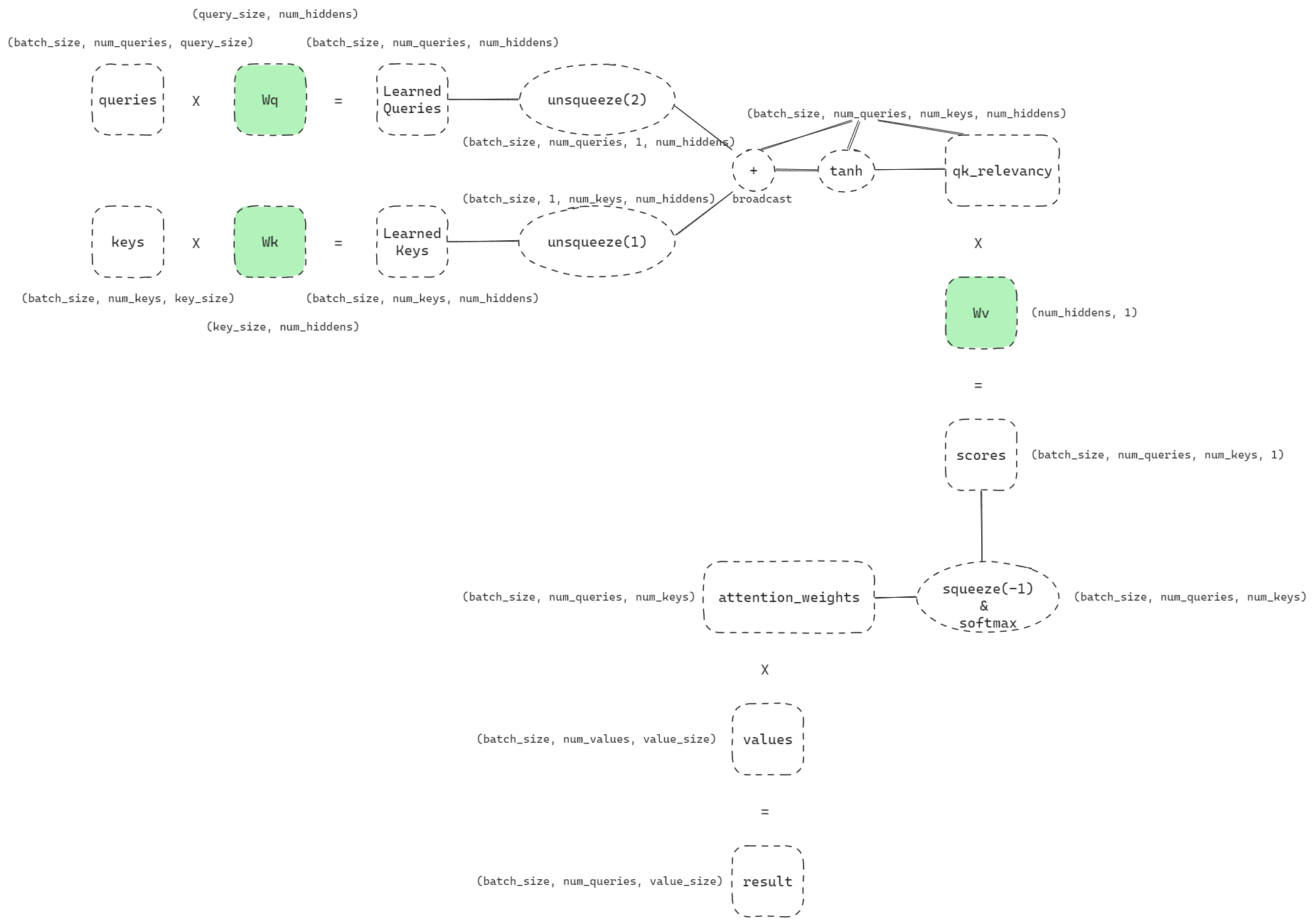
class AdditiveAttention(nn.Module):"""加性注意力"""def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.Linear(key_size, num_hiddens, bias=False)self.W_q = nn.Linear(query_size, num_hiddens, bias=False)self.w_v = nn.Linear(num_hiddens, 1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)# 在维度扩展后,# queries的形状:(batch_size,查询的个数,1,num_hidden)# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)# 使用广播方式进行求和features = queries.unsqueeze(2) + keys.unsqueeze(1)#增加维度features = torch.tanh(features)# self.w_v仅有一个输出,因此从形状中移除最后那个维度。# scores的形状:(batch_size,查询的个数,“键-值”对的个数)scores = self.w_v(features).squeeze(-1)self.attention_weights = masked_softmax(scores, valid_lens)#过滤掉不需要的qk# values的形状:(batch_size,“键-值”对的个数,值的维度)return torch.bmm(self.dropout(self.attention_weights), values)大佬做的一个流程图,原链接参考:李沐老师【动手学深度学习v2】 P65 注意力分数——Additive Attention 代码深度注释 & 数据流程图 - 就是玩
这里我关于维度有比较难以理解的地方,首先为什么要升维?“扩维再相加”只是为了一次性并行计算所有 query-key 对的加性得分,这么说好像不太好理解,但是注意这里的相加其实是作用到hiddens上面的!!!为什么?看下面:
我们直接看关于这个维度的压缩,其实一开始hiddens里面相当于是一个很长的隐藏层,它的存在就是储存隐藏单元的值,但是在wv的张量乘法中它变成了一个score,相当于在原本的三维张量里b1,q1,k1=score111,位置本身就是其大小了,就相当于只有一个变量没必要在找一个列表或者数组来储存了。
同时最下面和values的张量乘法是要有一个标注的,这里num_values&num_keys是等于一个“键值对个数”也因此才能构成矩阵乘法。
用一个小例子来演示上面的AdditiveAttention类, 其中查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小), 实际输出为(2,1,20)、(2,10,2)和(2,10,4)。 注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)。
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])#查query看前两个和查key看前六个attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens)输出:
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)尽管加性注意力包含了可学习的参数,但由于本例子中每个键都是相同的, 所以注意力权重是均匀的,由指定的有效长度决定。
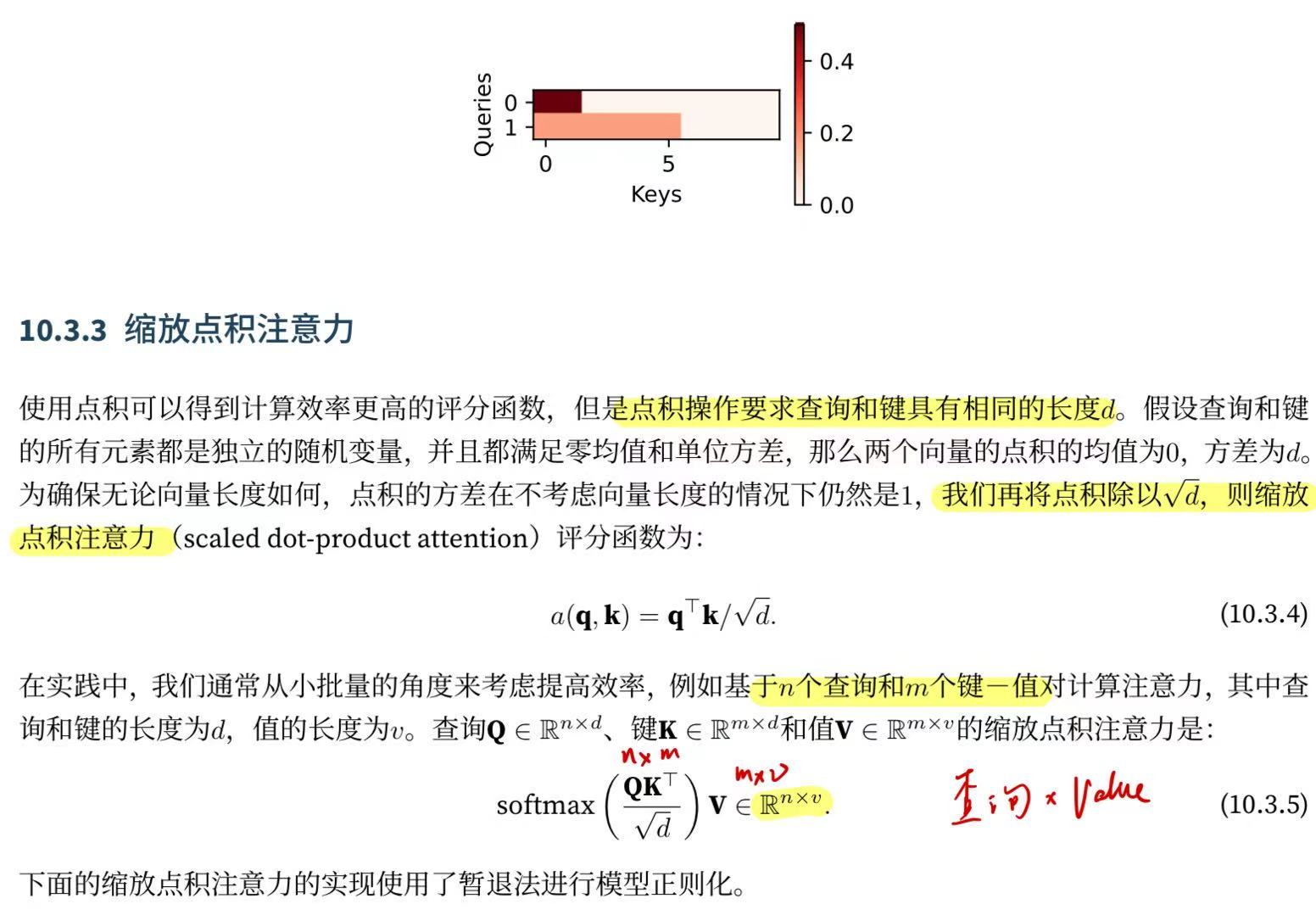
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')10.3.3. 缩放点积注意力
#@save
class DotProductAttention(nn.Module):"""缩放点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)# queries的形状:(batch_size,查询的个数,d)# keys的形状:(batch_size,“键-值”对的个数,d)# values的形状:(batch_size,“键-值”对的个数,值的维度)# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)def forward(self, queries, keys, values, valid_lens=None):d = queries.shape[-1]# 设置transpose_b=True为了交换keys的最后两个维度scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)self.attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)为了演示上述的DotProductAttention类, 我们使用与先前加性注意力例子中相同的键、值和有效长度。 对于点积操作,我们令查询的特征维度与键的特征维度大小相同。
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)输出:
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],[[10.0000, 11.0000, 12.0000, 13.0000]]])与加性注意力演示相同,由于键包含的是相同的元素, 而这些元素无法通过任何查询进行区分,因此获得了均匀的注意力权重。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')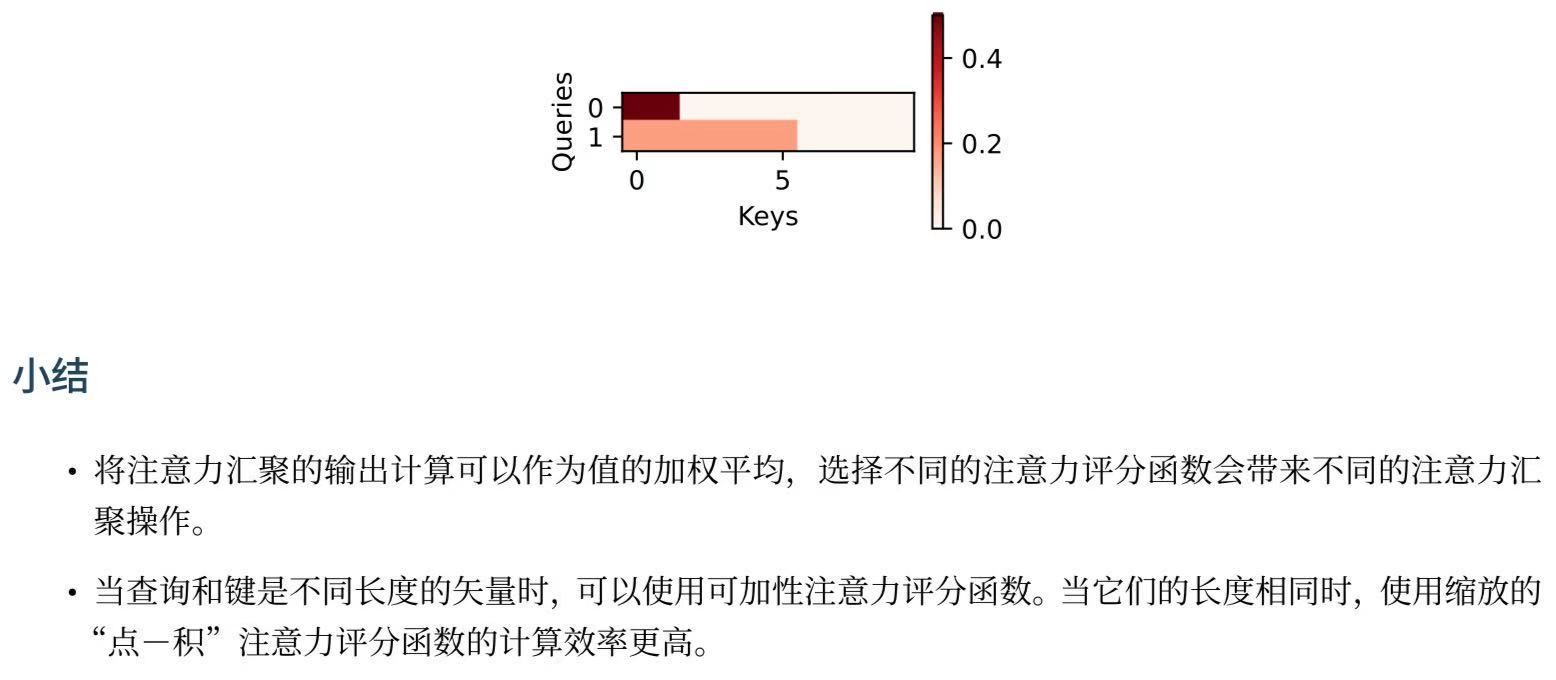
感觉好像没有讲为什么要这么做?我感觉就是一个是防止 softmax 饱和其次是保持不同相似度的区分度。