MySQL中的查询、索引与事务
目录
一 . MySQL 中的查询
(1)插入的同时进行查询:insert into 表名 select 列名 from 表名。
(2)分组聚合查询:
(3)联合查询(多表查询):
内连接与外连接:
编辑(4)子查询:
(5)合并查询:
二 . MySQL 中的索引
(1)索引是什么?
(2)索引付出了什么代价?
(3)如何使用 SQL 操作索引?
(4)索引背后的数据结构?
B + 树的特点:
B + 树的优势:
三 . 事务
(1)事务的基本概念
(2)事务的基本特性
四大隔离级别
一 . MySQL 中的查询
在 SQL 中,主要的操作就是,增删改查,其中,增、删、改都是很简单的操作,其中的重点就是查询,而除了一般的查询呢,还有很多种更为复杂的查询。
(1)插入的同时进行查询:insert into 表名 select 列名 from 表名。
(2)分组聚合查询:
a)搭配聚合函数:针对行与行之间,进行运算和统计。
b)通过 group by 分组:针对每个分组,还能够使用聚合函数进行进一步的查询。
c)分组时搭配条件:分组之前的条件用 while;分组之后的条件用 having。
(3)联合查询(多表查询):
我们在查询的时候,不一定只是针对一张表来进行查询,也可以针对多张表进行查询。而在进行多表查询的时候,一般来讲我们会按照一定的步骤顺序来进行:
a)分析出要查询的数据来自于那些表。
b)使这些表进行 “ 笛卡尔积 ” 。(进行多表查询最核心的操作)
c)指定连接条件:减去不必要的数据,只保留实际有意义的数据。(前提是两张或多张表有一列是相关联的数据)
d)进一步指定其他条件 / 聚合操作:除了上一步筛选去掉无意义的条件之外,我们还能进一步添加我们需要的、有意义的条件。
e)针对列进行精简 / 进行一些表达式的计算。(同样也是筛选操作,为了不使用 select * 将全部的信息列出来)
联合查询可以有两种方法:
(1)from 多个表 where 条件
(2)表1 join 表2 on 条件
上述所说的关于联合条件的内容,都是 “ 内连接 ” ,除此之外,我们还有 “ 外连接 ” :
外连接使用 left join 或者 right join 进行表示:
内连接与外连接:
(1)内连接
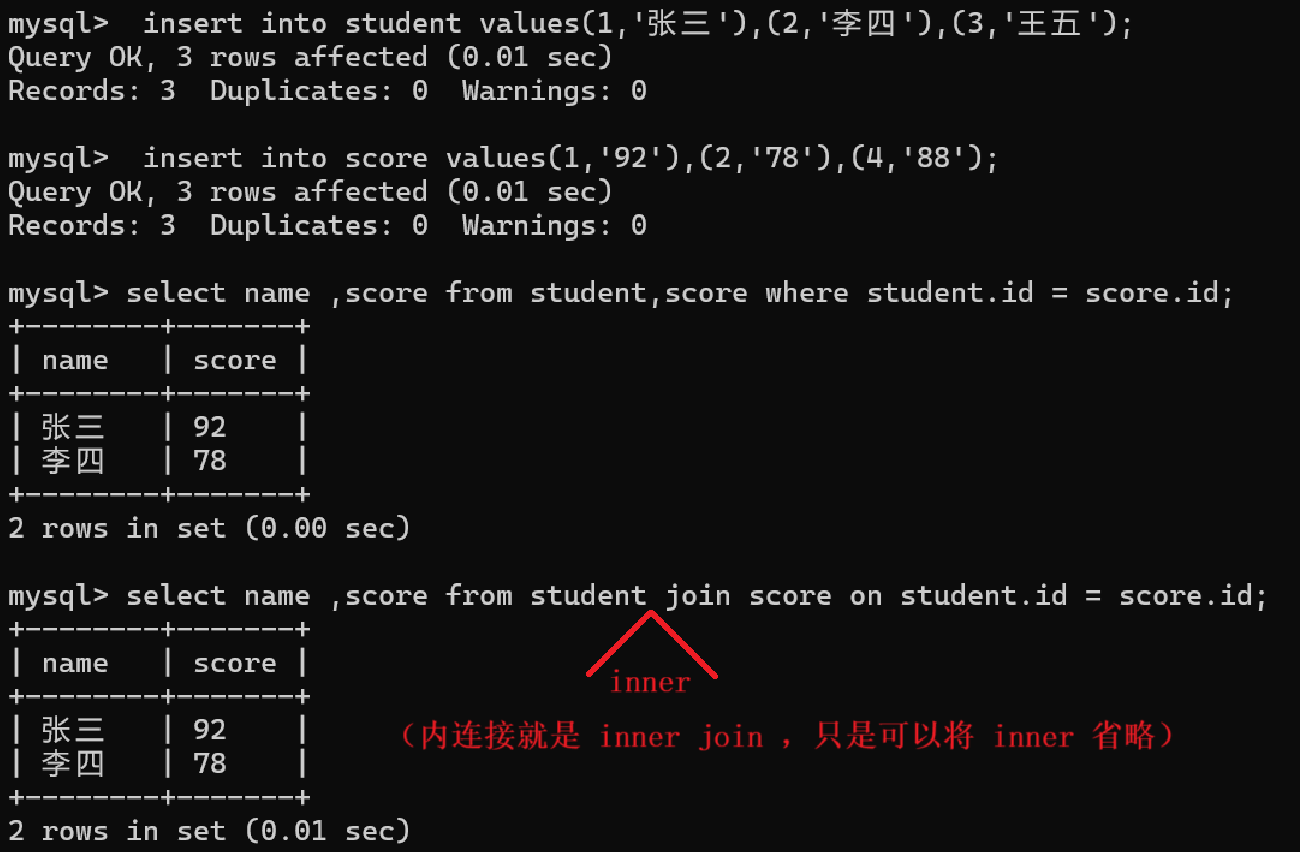
(2)外连接 (用 left join(左外连接)或者 right join(右外连接)表示)
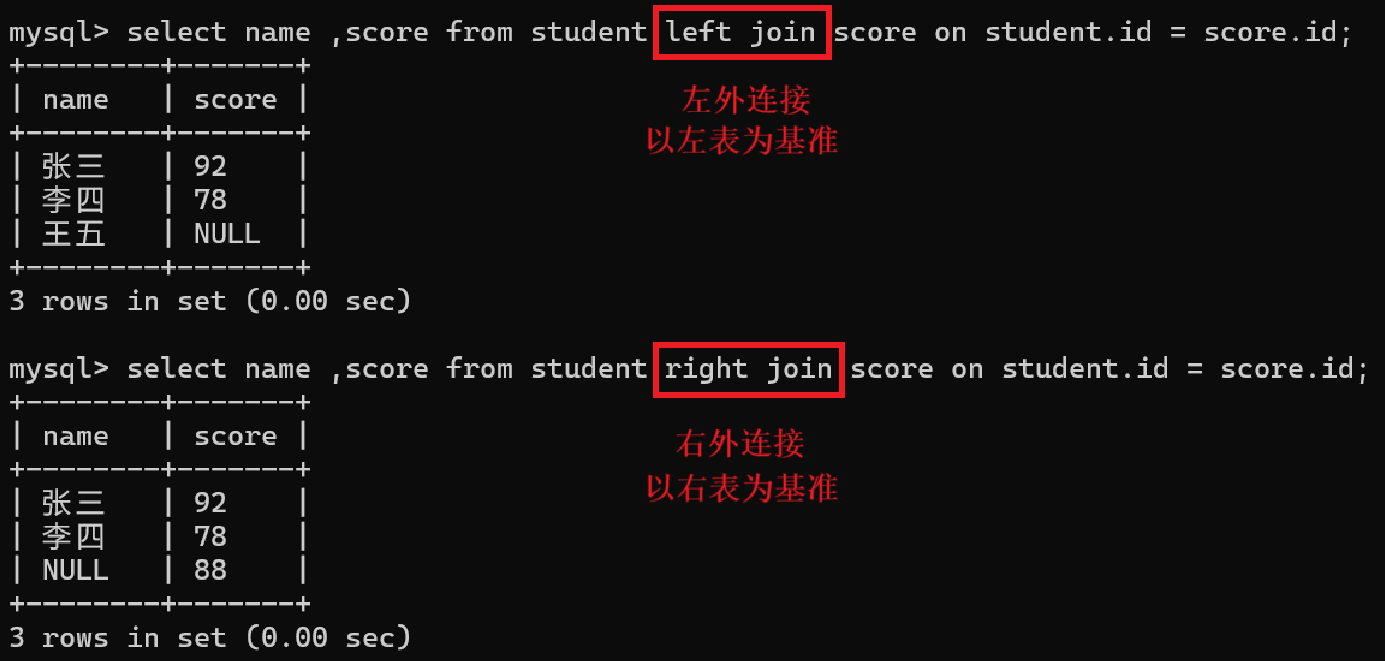
左外连接(left join):就是以左表为基准,能够确保左表中的每个记录都出现在最终结果里,如果左表中的记录在右表中没有相对应的记录,此时就会把右表中的相关字段填成 NULL。
右外连接(right join):就是以右表为基准,能够确保右表中的每个记录都出现在最终结果里,如果右表中的记录在左表中没有相对应的记录,此时就会把左表中的相关字段填成 NULL。
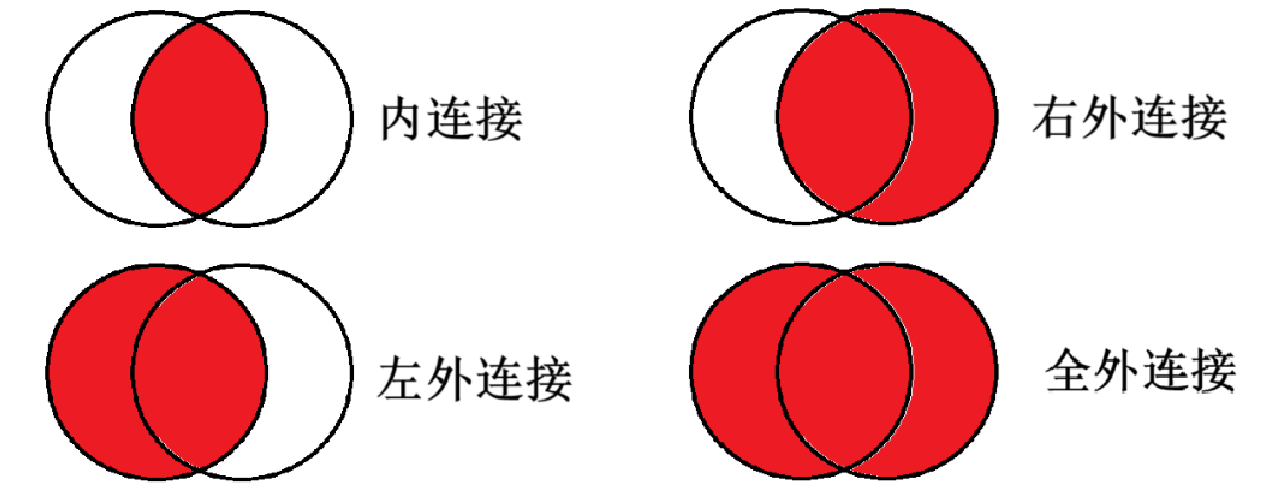
(2)全外连接
很可惜兄弟们,全外连接在 MySQL 中不支持,所以没办法给大家演示了,但是我用下面这一张图就能让大家理解清楚这几个连接之间的关系。
 (4)子查询:
(4)子查询:
子查询是一种特殊的连接:自连接,子查询就是自己与自己连接,将单独表中的行关系转化为列关系,自己与自己进行 “ 笛卡尔积 ” 。这一方式不推荐使用,因为这样会将简单问题复杂化,并不符合我们人类的认知规律。
(5)合并查询:
合并查询使用 union / union all ,可以将多个查询的结果合并在一起,但是合并的时候需要要求这些表的结果集的列数、类型、顺序都能够相互之间匹配。其优点是在合并的时候默认会对各个表结果集里的数据进行去重(不想要被去重就使用 union all )
二 . MySQL 中的索引
(1)索引是什么?
索引就相当于书的目录,能够提到查询的速度。
注意,不是一定能。
(2)索引付出了什么代价?
任何事情没有十全十美的,都是有利有弊的,索引虽然能在一些场景下可能起到加快查询速度的效果,但是它也付出了代价:
a)需要更多的存储空间.
b)可能会影响增、删、改的效率(不是一定会)。
但是就整体而言,索引对我们还是利大于弊,所以在日常开发中,索引的使用频率还是很高的。
(3)如何使用 SQL 操作索引?
如何使用索引呢?包含三个方法:
a)show index from 表名 ;这是查看索引(主键、外键、unique 会自动生成索引)。
b)create index 索引名 on 表名(列名);给指定列创建索引。
c)drop index 索引名 on 表名;删除索引。
使用时的注意事项:索引是根据 “ 列 ” 来创建的,后续查询的时候,查询条件使用的列需要和索引列相匹配才能索引生效,才能提高效率。此外,针对比较大的表,创建 / 删除索引是相当危险的,可能会触发大量的硬盘 IO ,把机器搞挂。
(4)索引背后的数据结构?
索引背后的数据结构就是我们的 B + 树。
B + 树的特点:
a)N 叉搜索树,每个节点上包含 N 个 key ,划分出 N 个区间。
b)每个父节点中的元素都会下沉到子节点中,作为节点中最大值的角色存在。
c)B + 树的叶子结点这一层就构成了数据集合的全集。
d)使用类似于链表这样的结构,把叶子结点串起来。
B + 树的优势:
a)N 叉搜索树,高度比较低,降低了硬盘 IO 的次数。
b)范围查询非常方便、高效。
c)所有的查询都是落到叶子结点上,开销非常稳定,容易预估成本。
d)叶子结点存储数据行,非叶子结点只存储索引列的 key ,使得非叶子结点占据空间小,可以加载到内存中,进一步的减少查询时 IO 的访问进阶。
三 . 事务
(1)事务的基本概念
事务,是用来解决一类特定场景的问题的,如为了完成某个操作,需要多个 SQL 配合实现。

例如在前些年,我们在银行进行转账的时候,就应该是这个账户扣完钱,另一方账户相应的金额到账了,这一过程,就应该是两个 SQL 都执行完毕,转账这一操作才完成,但是经常会出现一种情况:这边账户扣钱了,但是在这一个程序执行完这第一个操作之后,在执行第二个操作之前,出现了严重问题,例如程序崩溃,主机断电之类的,就会使得数据库的内容出错,导致另一方账户迟迟不到账这样的情况。而我们后来引入 “ 事务 ” 就是为了解决上述问题,避免出现 “ 转账转一半 ” 这样的情况。
所谓 “ 事务 ” ,就相当于把多个要执行的 SQL 打包成一个整体,在这个 “ 整体 ” 的执行过程中,就能够做到要么整个程序的操作都执行完,要么一个都不执行。就可以有效的避免发生上述这样卡在 “ 转账转一半 ” 这样的中间状态。
大家注意,此处的 “ 一个都不执行 ” 并不是 SQL 真的没执行,而知当事务执行到一半的发现出错时候,数据库就会自动进行 “ 还原操作 ” ,相当于把前面执行过的 SQL 进行 “ 撤销 ” ,所以最终呈现出来的效果就看起来好像一个都没执行一样。
这样的机制我们称之为 “ 回滚(RollBack)” 。“ 回滚 ” 类似于我们在某宝买东西的时候,在售后选择退货的机制。
同时,我们也将事务支持的上述 “ 特性 ” 称之为 “ 原子性 ” 。(因为再过去人们认为 “ 原子 ” 就是不可拆分的最小单位了)
然而数据库是如何知道我们之前执行一系列操作的顺序?如何知道前面的 SQL 做出了哪些修改?具体又是怎样实现 “ 回滚 ” 的呢?
这是因为在我们的数据库中存在一系列的 “ 日志体系 ” ,记录在 “ 文件 ” 中,这样既可以应对 “ 程序崩溃 ” 也能应对主机掉电。
当开启事务的时候,此时每一步执行的 SQL ,都对数据进行了哪些修改,这一系列信息就会被记录在案,后续如果需要回滚,就可以参考之前所记录的内容进行一步一步的还原。
这个时候就有小伙伴问了, 我们 drop database 这样的操作能否通过回滚 “ 滚 ” 回来呢?答案是否定的,因为回滚操作仅仅只是针对 “ 事务 ” 进行的。一方面 drop database 这样的操作不能放到事务当中去执行,另一方面这个操作也不能算是执行出错,而是正确的执行了我们的 SQL 指令。
(2)事务的基本特性
a)原子性:事务最核心的特性就是 “ 原子性 ” ,能够解决的问题就是批量执行 SQL 。
b)一致性:描述的是事务执行前和执行后,数据库中的数据都是 “ 合法状态 ” ,不会出现非法的临时结果的状态。
c)持久性:事务执行完毕之后,就会修改硬盘上的数据,事务都是会持久生效的。
d)隔离性:描述了多个事务在并发执行的时候,相互之间是怎样产生影响的,
在这之中,“ 隔离性 ” 是重中之重。我们要牢记,MySQL 是一个 “ 客户端 — 服务器 ” 结构的程序,而一个服务器,通常会给多个客户端同时提供服务,因此,很可能这多个客户端就同时给这个服务器提交事务来执行,与此相对,服务器就需要同时执行这多个事务,此时就是 “ 并发 ” 执行。
此时,如果这样同时执行的事务,恰好也是针对同一个表,进行一些增删改查,此时就可能引入一些问题:
(1)脏读
有两个事务 A 和 B 并发执行,其中事务 A 在针对某个表的事务进行修改,A 执行过程中,B 也去读取这个表的数据,当 B 读完之后,A 把表里的数据有改成别的了。这就导致,B 读到的数据,就不是最终的 “ 正确数据 ” ,而是读到了临时的 “ 脏数据 ” (脏数据往往是指 “ 数据过期了,过时了的错误数据 ”)
如何解决这个问题呢?就是我们在修改的时候,约定好别人不能读,也就是给 “ 给写操作加锁 ” 。
(2)不可重复读
此时有三个事务,首先事务 A 执行一个修改操作,A 执行完毕的时候,提交数据,接下来事务 B 执行,事务 B 读取刚才 A 提交的数据,在 B 读取的过程中,又来了一个事务 C ,C 又对刚刚 A 修改的数据再次做出了修改,此时在 B 的视角里,这段数据就会突然发生改变,对 B 来说,后续再读取到这个数据,读到的结果和第一次读到的结果就是不一样的,这样一整个过程,我们就称之为 “ 不可重复读 ” 。
不可重复读的重点:体现的是事务 B ,一个事务里多次读取到的结果不一样。(如果是有多个事务,每个事务读到的数据不一样,这种情况认为是正常的)
如何解决不可重复读呢?和上面的情况类似,就进行约定,一个事务在读取数据的过程中,其他事物不能修改它正在读的数据,也就是给 “ 读操作加锁 ” 。
(3)幻读
幻读就相当于不可重复读的一种 “ 特殊情况 ” ,有一个事务 A 在读取数据过程中,另一个事务 B 新增了或是删除了一些其他的数据,此时站在 A 的视角,就有可能突然冒出一个 B ,导致 A 多次读取的数据内容虽然一样,但是 “ 结果集 ” 不一样。
如何解决幻读呢?还是继续约定,只要有事务在读取数据,就不要对其进行操作,比如客户端,同时提交了多个事务过来,但是服务器一个一个的进行执行,这就是所谓的 “ 串行化 ” 。
那么总的来说,脏读,不可重复读,幻读这三个在并发执行事务的过程中容易遇到的问题,跟我们的隔离性有什么关系呢?
四大隔离级别
在 MySQL 中提供了四个隔离级别,可以通过配置文件来设置当前服务器的隔离级别是哪个级别。
设置不同的隔离级别,就会使得事务之间的并发执行的影响产生不同的差别,从而会影响到上述三个问题的情况。
(1)read uncommitted 读未提交
这种情况下,一个事务可以读取另一个事务未提交的数据,此时,就可能会产生脏读,不可重复读,幻读三种情况,但是此时,多个事务并发执行程度是最高,执行速度也是最快的。
(2)read committed 读已提交
这种情况下,一个事务只能读取另一个事务提交之后的数据(给写操作加锁了),此时,解决了脏读问题,但是仍可能产生不可重复读,幻读问题。 此时的并发程度会降低,执行速度会变慢,同时我们也称为隔离性提高了(事务之间的相互影响变小了,得到的数据更精准了)
(3)repeatable read 可重复读( MySQL 的默认隔离级别)
在这个情况下,相当于是给 “ 写 ” 和 “ 读 ” 操作都加锁了,此时,解决了脏读,不可重复读的问题,但是仍可能产生幻读问题。 并发程度进一步降低,执行速度进一步变慢,事务之间的隔离性也进一步提高了。
(4)serializable 串行化
此时所有的事务都是在服务器上一个接一个的执行,此时就解决了脏读,不可重复读,幻读等问题。此时的并发程度最低,执行速度最慢,隔离性最高,数据最准确。
总结:并发程度越高,速度越快,隔离性越低;并发程度越低,速度越慢,隔离性越高。
OKK,有关 MySQL 的查询、索引、事务这方面的知识咱们就说这么多了,这部分是面试的重点考察部分,就一个字,背背背!咱们下期再见吧,与诸君共勉!!!