图像分割-动手学计算机视觉9
前言
平面设计师在对图像进行处理时,往往需要提取图像中的某一个物体(如图9-1所示),这种技术被形象地称为“抠图”。“抠图”是图像分割的一个实际应用。在计算机视觉领域,图像分割(image segmentation)是最古老的,也是被研究得最多的一个问题。根据是否基于人为给定的语义监督,图像分割可分为无监督图像分割(unsupervised image segmentation)和有监督图像分割(supervised image segmentation)。本章将聚焦无监督图像分割,而有监督图像分割(包括语义分割和实例分割等)应归类于图像识别问题,将在后续章节介绍。无监督图像分割,其目的是把图像划分成若干互不相交的区域,使得具有相似特征的像素被划分到同一区域,具有不同特征的像素被划分到不同的区域(如图9-2所示)。这一目标完全通过挖掘图像内在结构信息实现,而不基于人为标注的语义类别,所以无监督图原图效果图像分割是一个普适性的问题,其结果可以为图9-1“抠图”解决高层视觉识别任务(如语义分割、目标检测、实例分割等)提供基础或者初始条件。
 ps:可爱的小猫
ps:可爱的小猫
在本章中,我们将介绍两种代表性的无监督图像分割算法一基于k均值的图像分割算法和基于归一化割的图像分割算法。
图像分割算法
本章聚焦无监督图像分割,因此我们首先要知道什么是无监督学习(unsupervised learning)。无监督学习是机器学习的一种类型,其特点是每个用于训练的样本只有其本身的信息,而没有任何标签信息,即没有“监督”信息。聚类(clustering)就是一种常用的无监督学习的方法,是指根据在数据中发掘出的样本与样本之间的关系,将数据进行分簇,使簇内的数据相互之间是相似的(相关的),而不同簇中的数据是不同的(不相关的)。簇内相似性越大,簇间差距越大,说明聚类效果越好。作为一种无监督学习的方法,聚类是许多领域常用的机器学习技术。图像分割的本质就是对像素进行聚类,所以图像分割算法一般是基于聚类算法的。
基于k均值聚类的图像分割算法 k均值(k-means)是一种在机器学习和数据分析领域广泛使用的聚类算法。它旨在将数据集划分为k个不同的、不重叠的子集或簇,每个数据样本归属于距离其最近的簇。具体而言, k均值算法通过以下几个关键步骤进行迭代操作。
(1)初始化:从数据集中随机选择k个数据样本,并将其视为初始簇中心。
(2)分配:将每个数据样本分配给与其距离最近的簇中心所属的簇。
(3)更新:当所有数据样本分配完毕,计算每个簇中所有数据样本的均值,并将其作为新的簇中心。
(4)重复:重复分配和更新步骤,直到簇中心不再发生显著变化,或达到预设的迭代次数。
k均值算法因其计算简单和收敛速度快而受到广泛应用,它不仅应用于传统的数据分析,还广泛应用于图像处理领域。如果将图像的像素视作数据点,并使用k均值算法对其进行聚类,就可以实现图像分割。那么,对于一幅图像,应该如何定义像素的信息呢?我们知道,每个像素包含R、G、B这3个通道的数值(如图9-3所示),因此可以以RGB值为特征对像素进行聚类。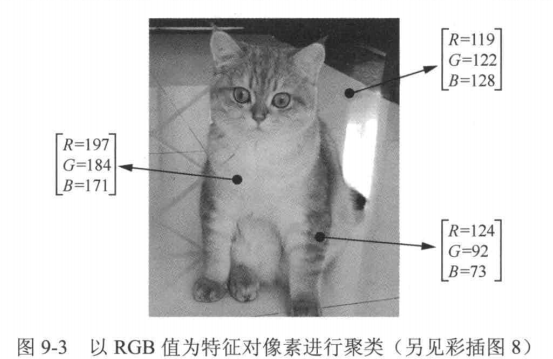
我们来手动编写k-means算法实现用RGB完成聚类实现图像分割
RGB代码实现
cat.jpg
# use k-means algorithm to cluster the images
from sklearn.cluster import KMeans
import numpy as np
from matplotlib.image import imread
import matplotlib.pyplot as plt
from PIL import Image# load the images
image = imread('cat.jpg')
# 将rgb值统一到0~1之间
if np.max(image)>1:image = image/255.0
# 输出:二维矩阵 X,形状为 (像素总数, 通道数)。-1:自动计算该维度的大小,shape[2]为通道数
X=image.reshape(-1,image.shape[2])
# Use means算法
segment_imgs=[]
n_cluster=4
kmeans=KMeans(n_clusters=n_cluster, random_state=0).fit(X)
labels=kmeans.labels_
# 输出聚类标签
print(np.unique(labels))
# 输出聚类中心
centers=kmeans.cluster_centers_
print(centers)
# 输出每个像素所属的类别
label_img=np.reshape(labels,(image.shape[0],image.shape[1]))
# 输出聚类结果
plt.imshow(label_img)
plt.show()输出效果:
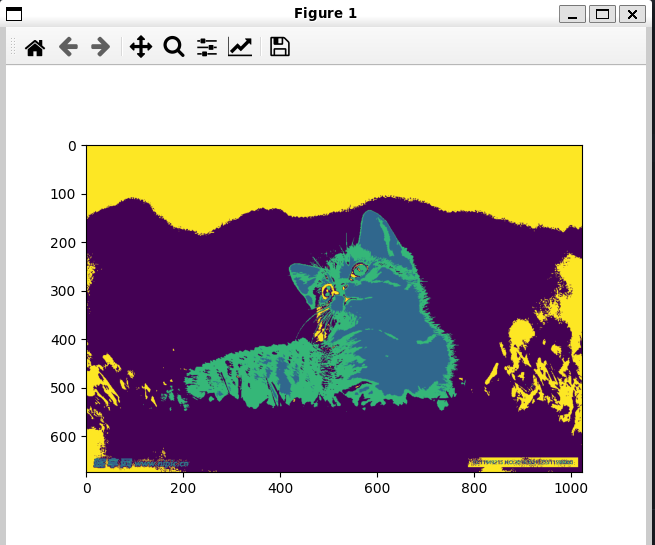
可以看到确实划分好了四个类别,可以尝试不同的n_cluster的值来观察不同效果如2,6,8
观察实验结果不难发现,仅用RGB值作为特征可能会在分割时出现一些离散的点。实际上,由于图像的像素本身就蕴含着坐标信息,除了可以选择RGB值作为像素的特征,也可以将坐标信息纳入其中。在特征中纳入坐标信息,便可以将图像中这些离散的点分割到周围的物体中。这种做法既考虑了颜色的相似性,也考虑了空间的离散程度。我们再次尝试图像分割,并比较设置不同个数的聚类中心对图像分割的影响。
在特征中纳入坐标信息代码
from sklearn.cluster import KMeans
import numpy as np
from matplotlib.image import imread
import matplotlib.pyplot as plt# 加载图像
image = imread('cat.jpg')
if np.max(image) > 1:image = image / 255.0sp = image.shape# 添加空间信息(改进的归一化方式)
weight = 0.5 # 调整这个值观察效果
y = weight * np.array([[i for i in range(sp[1])] for j in range(sp[0])]) / sp[1] # 水平坐标归一化到[0, weight]
x = weight * np.array([[j for i in range(sp[1])] for j in range(sp[0])]) / sp[0] # 垂直坐标归一化到[0, weight]# 添加坐标通道
image_with_pos = np.append(image, x.reshape(sp[0], sp[1], 1), axis=2)
image_with_pos = np.append(image_with_pos, y.reshape(sp[0], sp[1], 1), axis=2)# 准备聚类数据
X = image_with_pos.reshape(-1, image_with_pos.shape[2])# K-means聚类
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
labels = kmeans.labels_# 结果可视化
plt.figure(figsize=(12, 6))# 显示原始图像
plt.subplot(1, 2, 1)
plt.imshow(image)
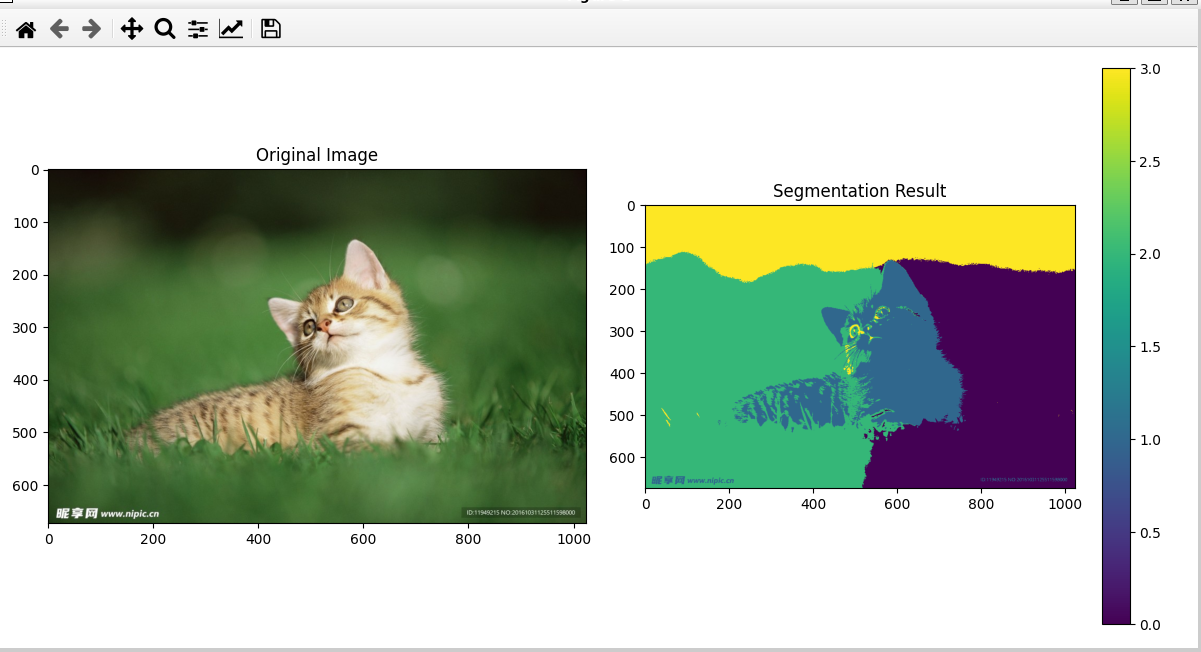
plt.title('Original Image')# 显示分割结果(使用离散颜色映射)
plt.subplot(1, 2, 2)
label_img = labels.reshape(sp[0], sp[1])
plt.imshow(label_img)
plt.title('Segmentation Result')
plt.colorbar()plt.tight_layout()
plt.show()# 可选:用聚类中心颜色重建图像
segmented = kmeans.cluster_centers_[labels][:, :3] # 只取前3个通道(RGB)
segmented = segmented.reshape(image.shape)
plt.imshow(segmented)
plt.title('Reconstructed Image')
plt.show()效果:可以明显看出图像更加连续了因为加入了坐标信息,减少了异常点的数量
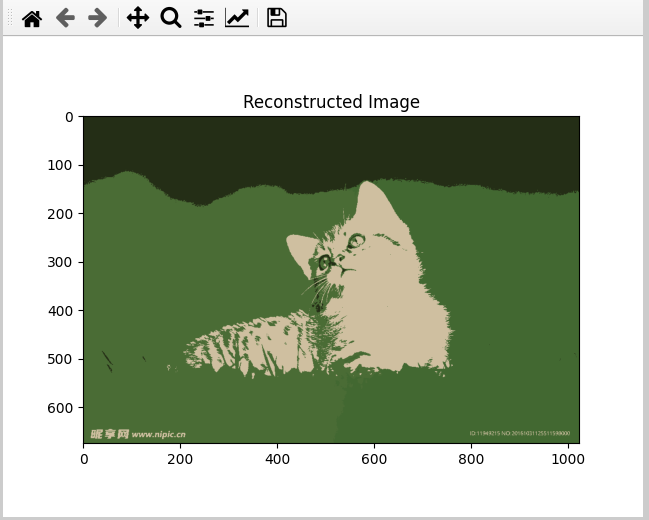
上图是用聚类颜色中心重建图像的结果
聚类颜色中心
将原始图像的所有像素用其所属簇的中心颜色替代,从而得到一个颜色简化的图像版本,颜色数量等于K-means中设置的簇数量(K值)。
图切割算法原理
图切割(Graph Cut)是一种基于图论的图像分割方法,将图像分割问题转化为图的最小割(Min-Cut)问题。图像中的每个像素对应图中的一个节点,相邻像素之间的边权重反映相似性。通过最小化能量函数,将图划分为前景和背景。
能量函数通常定义为: $$ E(A) = \lambda \cdot R(A) + B(A) $$ 其中:
- $A$ 是分割标签(前景/背景);
- $R(A)$ 是区域项,衡量像素与前景/背景模型的相似性;
- $B(A)$ 是边界项,鼓励相似像素分配相同标签;
- $\lambda$ 是权重系数。
能量函数的具体形式
区域项
对于像素 $i$ 和标签 $A_i$(前景或背景),区域项通常用负对数概率表示: $$ R(A_i) = -\log P(I_i | A_i) $$ $P(I_i | A_i)$ 是像素 $I_i$ 属于标签 $A_i$ 的概率,通常通过高斯混合模型(GMM)估计。
边界项
边界项衡量相邻像素 $i$ 和 $j$ 的差异性,常用颜色差异的指数函数: $$ B(A_i, A_j) = \exp \left( -\frac{|I_i - I_j|^2}{2\sigma^2} \right) \cdot \frac{1}{\text{dist}(i, j)} $$ 其中 $\sigma$ 是控制敏感度的参数,$\text{dist}(i, j)$ 是像素间的空间距离。
代码实现(Python示例)
以下是基于 PyMaxflow 库的图切割实现示例:
import cv2
import numpy as np# 加载图像
image = cv2.imread("cat.jpg")
if image is None:print("无法加载图像,请检查文件路径")exit()# 创建掩码
mask = np.zeros(image.shape[:2], np.uint8)# 定义前景矩形区域 (x,y,width,height)
# 调整为图像中央区域或包含猫的区域
height, width = image.shape[:2]
# rect = (width//4, height//4, width//2, height//2) # 调整为适合你的图像
rect=cv2.selectROI(img=image,windowName="Select ROI",fromCenter=False,showCrosshair=True)print(rect)
# 创建模型
bgd_model = np.zeros((1, 65), np.float64)
fgd_model = np.zeros((1, 65), np.float64)# 应用GrabCut - 增加迭代次数
cv2.grabCut(image, mask, rect, bgd_model, fgd_model, iterCount=5, mode=cv2.GC_INIT_WITH_RECT)# 修改掩码 - 更明确的处理
# 0和2是背景,1和3是前景
mask2 = np.where((mask == 1) | (mask == 3), 255, 0).astype('uint8')# 应用掩码
result = cv2.bitwise_and(image, image, mask=mask2)
print('Segmented Image Finished')
# 显示结果
while True:cv2.imshow("Original", image)cv2.imshow("Segmented Image", result)if cv2.waitKey(1) & 0xFF == ord('q'):break
cv2.destroyAllWindows()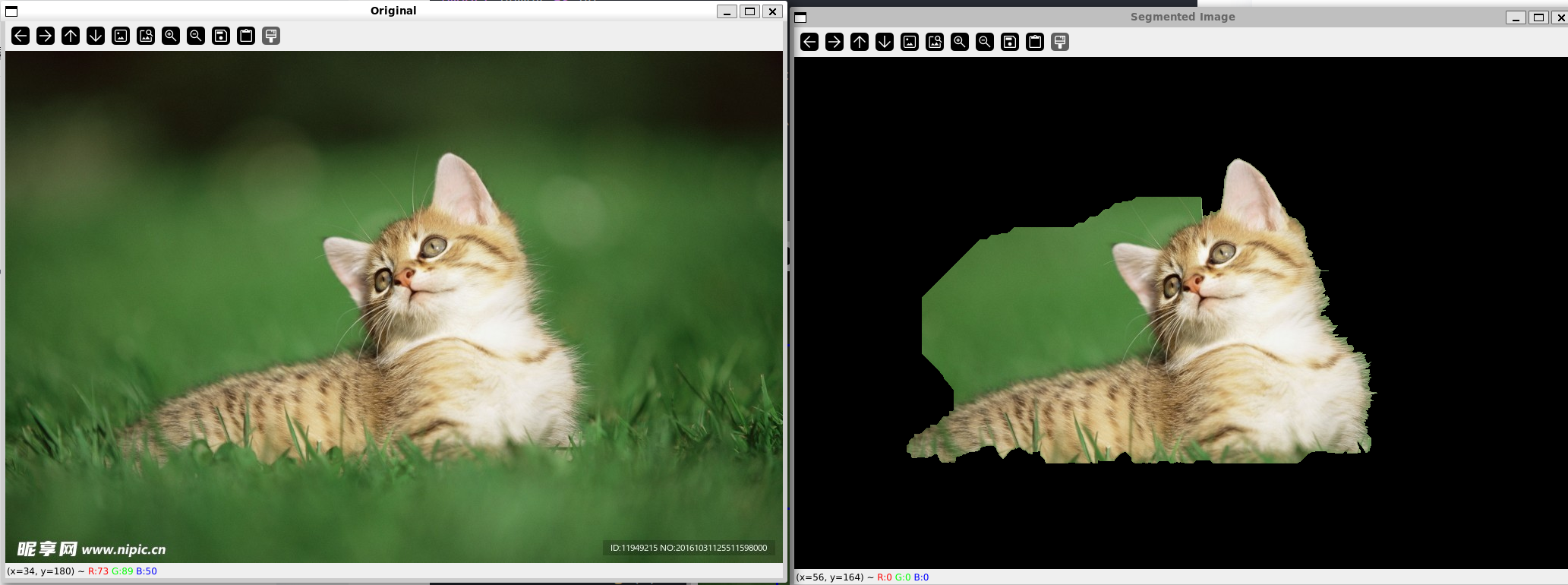
可以看到效果不怎么好
使用Unet
嗯,效果不怎么好
使用SAM
安装依赖
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv-python matplotlib torch torchvision torchaudio
下载 SAM 权重(示例用 sam_vit_h):
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
SAM 自动分割并提取前景代码实现
import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator# 1. 加载 SAM 模型
sam_checkpoint = "sam_vit_h_4b8939.pth" # 权重文件路径
model_type = "vit_h"device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)# 2. 自动分割器
mask_generator = SamAutomaticMaskGenerator(model=sam,points_per_side=32,pred_iou_thresh=0.86,stability_score_thresh=0.92,crop_n_layers=1,crop_n_points_downscale_factor=2,min_mask_region_area=500 # 去掉很小的区域
)# 3. 读取图片
image_path = "cat.jpg"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 4. 生成分割掩码
masks = mask_generator.generate(image_rgb)# 5. 合并所有掩码为一个前景
final_mask = np.zeros(image.shape[:2], dtype=np.uint8)
for m in masks:final_mask = np.logical_or(final_mask, m["segmentation"])final_mask = (final_mask * 255).astype(np.uint8)# 6. 提取前景
mask_3ch = cv2.merge([final_mask, final_mask, final_mask])
segmented_image = cv2.bitwise_and(image, mask_3ch)# 7. 显示结果
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(image_rgb)
plt.title("Original Image")
plt.axis('off')plt.subplot(1, 3, 2)
plt.imshow(final_mask, cmap='gray')
plt.title("SAM Mask")
plt.axis('off')plt.subplot(1, 3, 3)
plt.imshow(cv2.cvtColor(segmented_image, cv2.COLOR_BGR2RGB))
plt.title("Segmented Foreground")
plt.axis('off')plt.tight_layout()
plt.show()

改成 SAM 的好处
不需要自己训练,直接用大模型分割
自动分割效果远好于训练不充分的 U-Net
可以自动过滤小区域噪声
也支持交互式分割(指定点或框)
如果你想让它 只分割一只猫 而不是所有物体,可以用 SAM + 点提示 的方式,让模型只输出你点击位置的目标掩码。
交互式鼠标点击选目标版本
这样就能精确地提取猫,记得多添加点目标点来使得模型更好的提取前景目标。
import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor# 1. 加载 SAM 模型
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# 2. 读取图片
image_path = "cat.jpg"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image_rgb)# 3. matplotlib 交互点击
click_points = []def onclick(event):if event.xdata is not None and event.ydata is not None:x, y = int(event.xdata), int(event.ydata)click_points.append((x, y))print(f"点击位置: {(x, y)}")ax.plot(x, y, 'ro') # 红点fig.canvas.draw()fig, ax = plt.subplots()
ax.imshow(image_rgb)
ax.set_title("点击选择目标,关闭窗口结束")
cid = fig.canvas.mpl_connect('button_press_event', onclick)
plt.show()# 4. 生成 SAM 掩码
if len(click_points) == 0:raise ValueError("未选择任何点!")input_point = np.array(click_points)
input_label = np.ones(len(click_points)) # 1 表示前景点masks, scores, logits = predictor.predict(point_coords=input_point,point_labels=input_label,multimask_output=True
)best_mask = masks[np.argmax(scores)]# 5. 提取前景
mask_uint8 = (best_mask.astype(np.uint8) * 255)
mask_3ch = cv2.merge([mask_uint8, mask_uint8, mask_uint8])
segmented_image = cv2.bitwise_and(image, mask_3ch)# 6. 显示结果
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(image_rgb)
plt.title("Original Image")
plt.axis('off')plt.subplot(1, 3, 2)
plt.imshow(best_mask, cmap='gray')
plt.title("Selected Mask")
plt.axis('off')plt.subplot(1, 3, 3)
plt.imshow(cv2.cvtColor(segmented_image, cv2.COLOR_BGR2RGB))
plt.title("Segmented Foreground")
plt.axis('off')plt.tight_layout()
plt.show()

可以看到效果很好