Linux系统之ELF文件
一、总述
ELF(Executable and Linkable Format,可执行与可链接格式)文件是一种用于存储可执行文件、目标代码、共享库以及核心转储的文件格式,广泛应用于类 Unix 操作系统(如 Linux 和 FreeBSD)中。
二、结构
这是一张结构图,下面我们一起探讨一下:
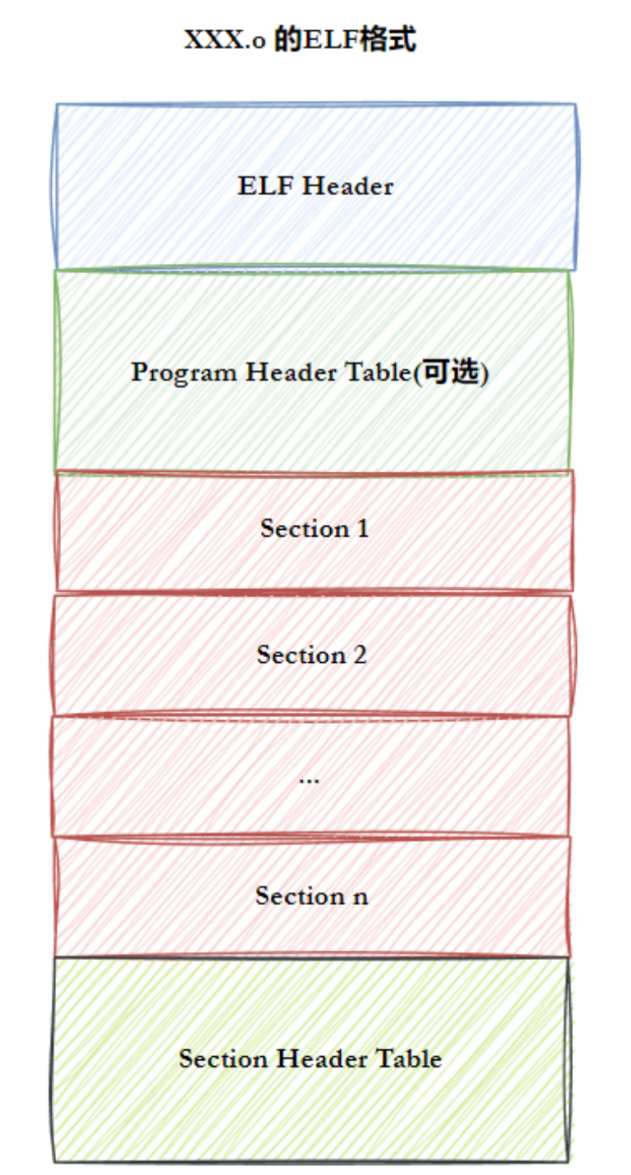
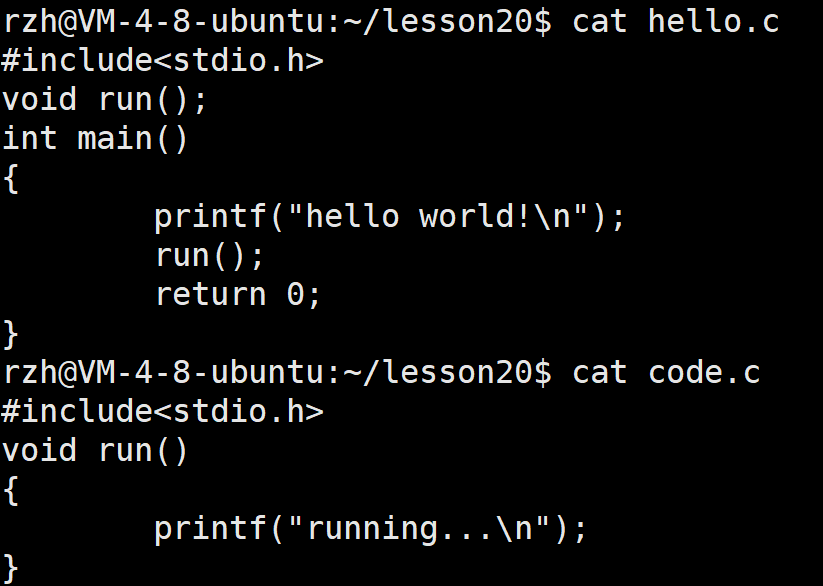
我们先写一段代码:
// hello.c
#include<stdio.h>
void run();
int main() {
printf("hello world!\n");
run();
return 0;
} /
/ code.c
#include<stdio.h>
void run() {
printf("running...\n");
}//编译一下
gcc *.c -o myexe
之后我们查看一下文件:file myexe

1.ELF Header
现在我们来查看一下ELF Header:
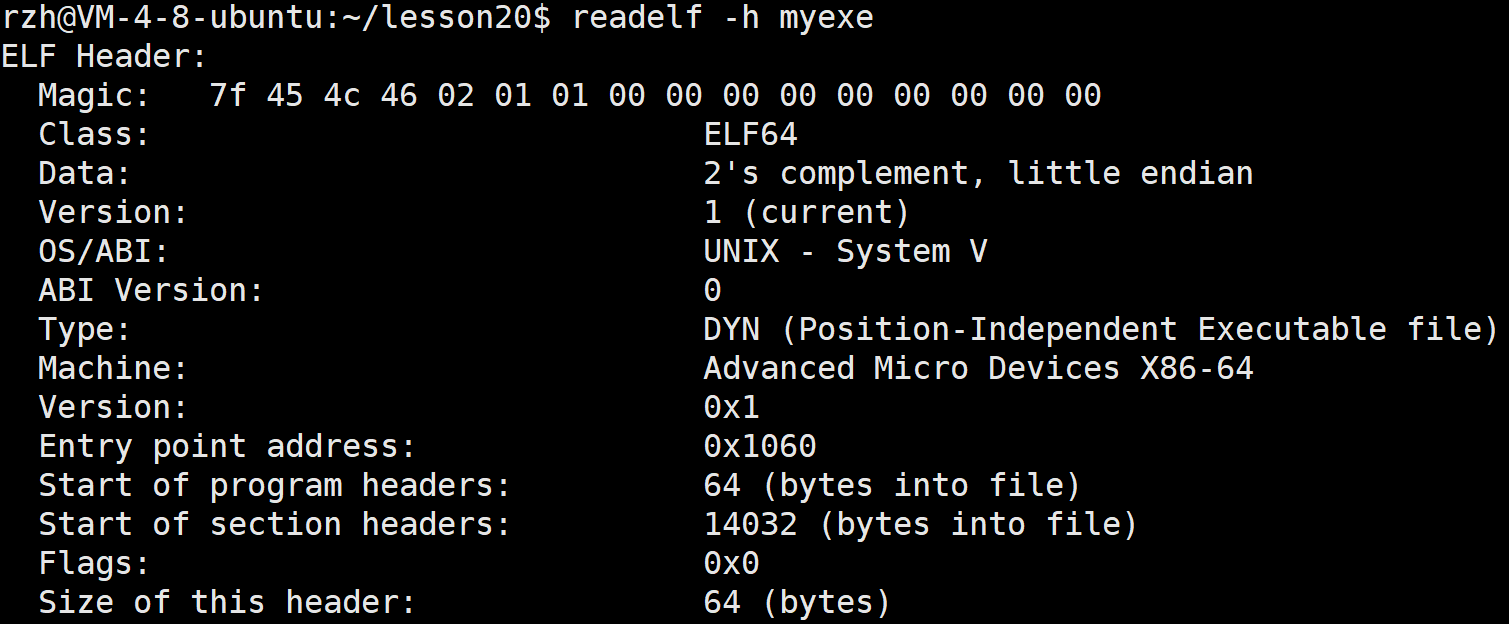
这上面有很多信息,我们来说明一下:
Magic Number:用于标识文件类型,通常是
7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00。Class:文件类别,例如 ELF64(64位)或 ELF32(32位)。
Data:数据的字节序,可以是大端(big endian)或小端(little endian)。
Version:ELF 格式的版本号。
OS/ABI:操作系统和应用程序二进制接口。
ABI Version:ABI 版本号。
Type:文件类型,例如可执行文件(EXEC)、可重定位文件(REL)、共享对象(DYN)等。
Machine:目标架构,例如 x86-64(Advanced Micro Devices x86-64)。
Entry point address:程序的入口点地址。
Program header table offset:程序头表的偏移量。
Section header table offset:节头表的偏移量。
Flags:与文件相关的标志。
Size of this header:文件头的大小。
Size of program headers:程序头表条目的大小。
Number of program headers:程序头表条目的数量。
Size of section headers:节头表条目的大小。
Number of section headers:节头表条目的数量。
Section header string table index:节头表字符串表的索引。
问题:如何理解ELF Header以及文件位置
ELF Header是用于标识和描述可执行文件、目标代码、共享库等的关键数据结构,它让编译器和操作系统能够识别文件类型、结构和系统兼容性。文件在磁盘上以一维字节数组的形式存储,无论是二进制还是文本文件,操作系统通过路径名来定位文件位置,可以使用命令行工具、图形界面或编程API来查看和管理这些文件
2.程序头表和节头表
2.1 程序头表(Program Header Table)
程序头表是ELF文件中的一个重要组成部分,它描述了文件中的段(segments)。段是文件在内存中的布局单位,每个段可以包含不同类型的数据,如代码、数据、堆栈等。程序头表的主要作用是:
描述段的属性:每个段在程序头表中都有一个对应的条目,描述了段的类型、文件偏移、虚拟地址、物理地址、文件大小、内存大小、对齐要求等。
指导加载过程:操作系统的加载器使用程序头表中的信息来决定如何将文件中的段加载到内存中。例如,它可以根据段的虚拟地址和文件偏移来计算段在内存中的位置。
支持动态链接:对于动态链接库(shared libraries),程序头表还包含了动态链接所需的信息,如动态符号表、重定位表等。
2.2 节头表(Section Header Table)
节头表是ELF文件中的另一个重要组成部分,它描述了文件中的节(sections)。节是文件的逻辑单位,每个节包含特定类型的数据,如代码、数据、符号表、字符串表等。节头表的主要作用是:
描述节的属性:每个节在节头表中都有一个对应的条目,描述了节的名称、类型、大小、位置、对齐要求、链接信息等。
支持链接过程:链接器使用节头表中的信息来决定如何将不同的目标文件链接成可执行文件。例如,它可以根据节的链接信息来合并符号表和重定位表。
支持调试和分析:调试器和分析工具可以使用节头表中的信息来访问文件中的特定数据,如代码、数据、符号信息等。
2.3合并与加载
在ELF文件中,节是文件的逻辑单位,而段是文件在内存中的布局单位。在加载过程中,操作系统可能会将多个节合并成一个段,以优化内存使用和访问效率。这个过程称为合并(Merging)。
合并:操作系统会根据节的属性(如类型、对齐要求等)和内存布局需求,将多个节合并成一个段。例如,所有代码节可能被合并成一个代码段,所有数据节可能被合并成一个数据段。
加载:操作系统的加载器使用程序头表中的信息来将文件中的段加载到内存中。加载器会根据段的虚拟地址和文件偏移来计算段在内存中的位置,并根据段的属性(如可执行、可写、可读等)设置内存保护。
动态链接:对于动态链接库,加载器还需要处理动态链接所需的信息,如动态符号表、重定位表等。加载器会使用这些信息来解析动态链接库中的符号引用,并根据需要加载额外的动态链接库。
合并是在加载的时候进行的!!
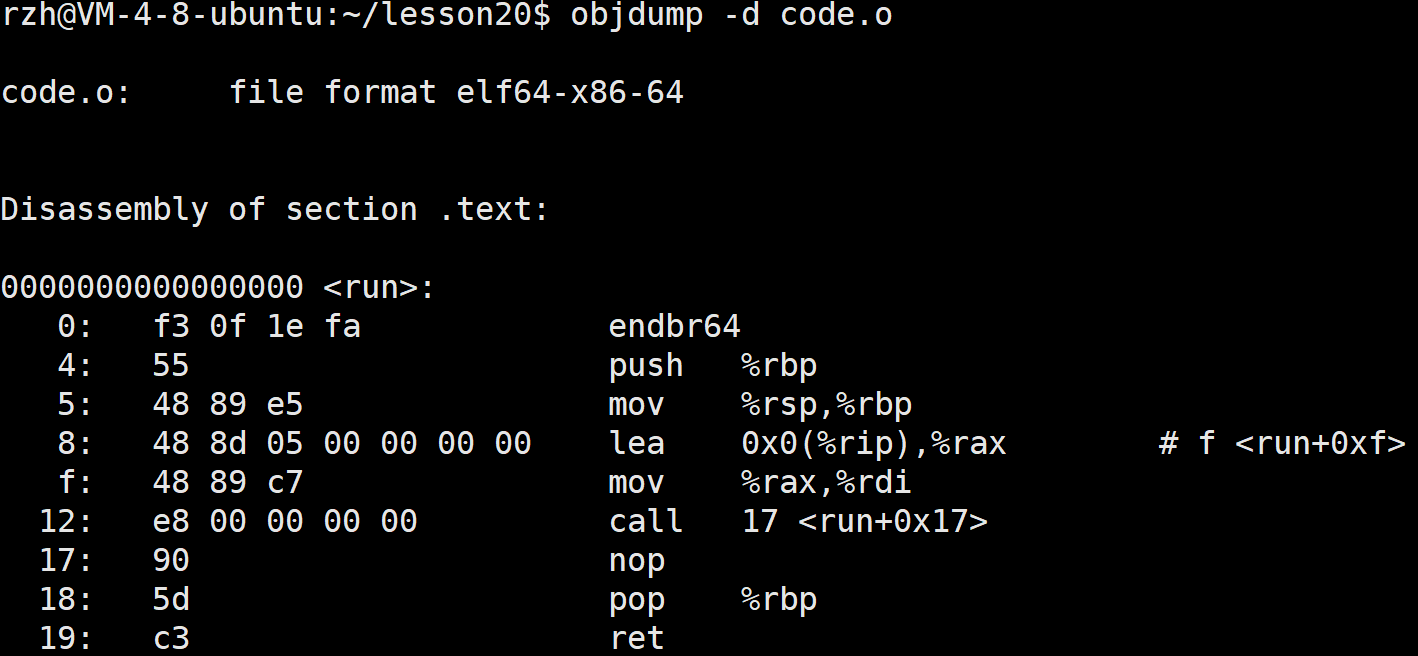
我们在来看一下反汇编:
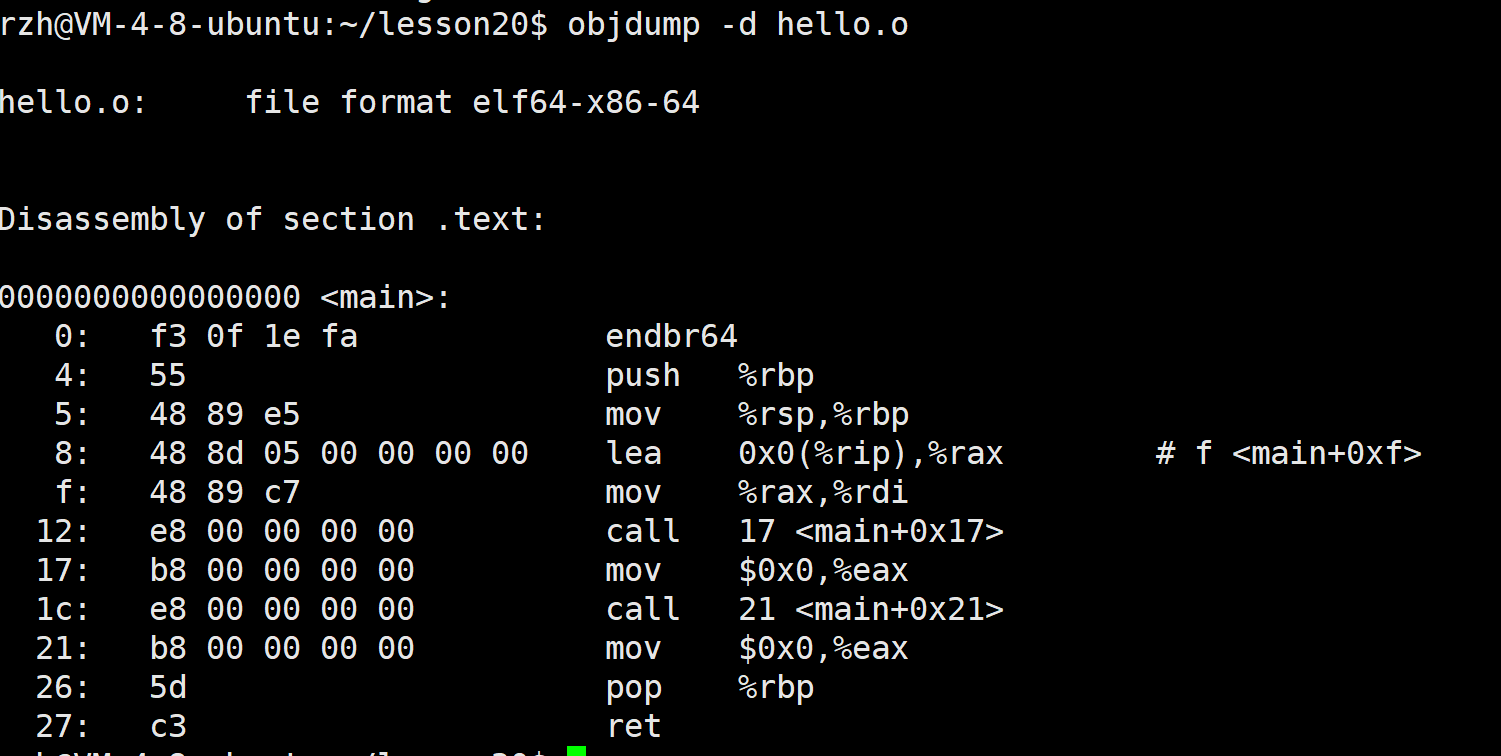
可以看到,
callq指令(调用函数)使用了相对地址(如<main+0xe>),这些地址在未链接的状态下是不确定的,因为没有进行地址重定位。
三、链接过程相谈
链接是编译过程中的一个重要步骤,它将一个或多个目标文件(.o文件)合并成一个可执行文件或共享库。在这个过程中,地址重定位是确保代码和数据在内存中正确定位的关键步骤。
1.地址重定位
1.1 为什么需要地址重定位?
编译时地址未知:编译器在编译程序时,不知道程序最终会在内存中的哪个位置执行。因此,它生成的指令中包含的是相对地址或符号地址,而不是最终的物理地址。
内存布局的灵活性:操作系统需要能够将程序加载到内存中的任何位置,以支持多任务和内存管理。这意味着程序必须能够在不同的内存地址上正确执行。
共享库和动态链接:在动态链接中,共享库可能在运行时被加载到不同的地址。地址重定位确保了程序能够正确地引用这些库中的函数和数据。
1.2 地址重定位的过程
编译阶段:编译器生成目标文件(.o文件),这些文件包含了程序的机器代码和数据,以及必要的元数据,如符号表和重定位信息。
链接阶段:
符号解析:链接器解析目标文件中的符号引用,确定每个符号(如函数和变量)的最终地址。
重定位计算:链接器计算每个需要重定位的地址的最终值。这涉及到将相对地址转换为绝对地址,通常是基于段的起始地址和偏移量。
加载阶段:
加载器:操作系统的加载器将可执行文件加载到内存中。加载器使用程序头表中的信息来确定每个段的加载地址。
最终重定位:在某些系统中,加载器还会进行最终的地址重定位,特别是当程序被加载到非预期的内存地址时。
2.平坦模式
平坦模式(Flat Memory Model)是一种简化的内存寻址方式,它在现代操作系统和CPU架构中已经不太常见。但在一些嵌入式系统或者简单的CPU设计中,平坦模式仍然被使用。
2.1什么是平坦模式?
平坦模式是一种内存寻址方式,其中整个内存被视作一个单一的、连续的地址空间。这意味着所有的内存地址都直接通过一个统一的地址总线访问,没有分页或分段的概念。在这种模式下,内存地址的计算和访问非常简单,因为所有内存地址都是直接可访问的。
2.2 平坦模式的特点
单一地址空间:平坦模式下,所有的内存地址都在一个单一的地址空间内,没有任何分段或分页的限制。
简单的地址计算:由于内存是连续的,地址计算非常简单,直接使用线性地址即可访问任何内存位置。
适合简单系统:平坦模式适合于那些内存需求较小、结构简单的系统,如一些嵌入式系统或微控制器。
安全性和保护性较低:没有分页或分段,平坦模式在内存保护和安全性方面较弱,难以实现现代操作系统所需的复杂内存管理策略。
不适用大内存系统:对于需要处理大量内存的现代系统,平坦模式不够灵活,因为它不能有效地管理大容量的内存空间。
2.3 平坦模式与分页和分段
与平坦模式相比,现代操作系统广泛使用的分页(Paging)和分段(Segmentation)提供了更复杂的内存管理能力:
分页:将内存分为固定大小的块(页),并使用页表来映射虚拟地址到物理地址。这允许更有效的内存使用和保护。
分段:将内存分为不同大小的段,每个段代表程序的不同部分(如代码段、数据段等),并使用段表来管理这些段。这有助于实现内存保护和隔离。
2.4 总结
我们查看一下汇编代码: objdump -d myexe,往下翻可以看到如下内容: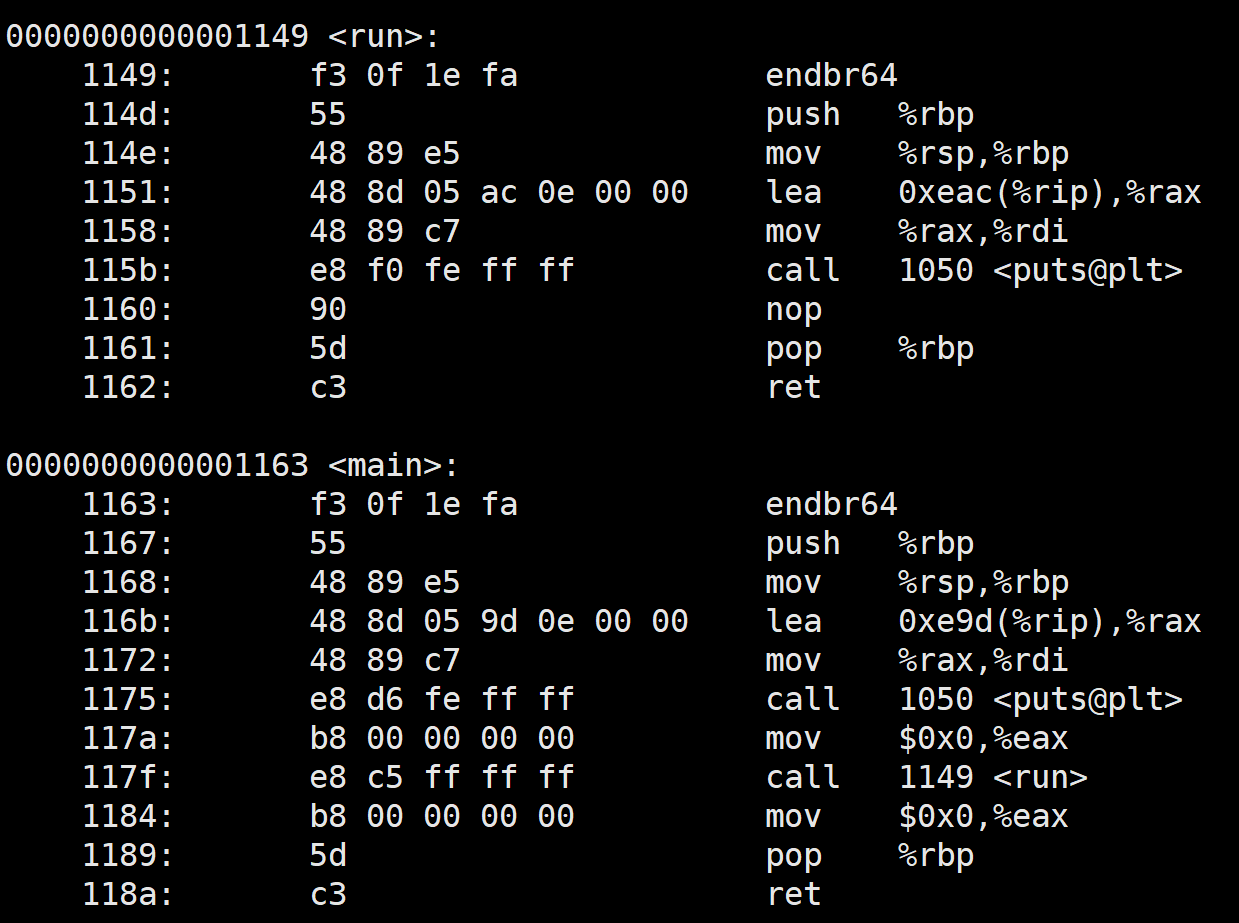
这里我要总结出几个结论:
1)我的程序,在链接静态库和.o文件,连接在做地址重定位!
2).o/.obj 叫做可重定位目标文件
3)Linux系统编译形成可执行程序的时候,需要对代码和数据要进行编址
4)当代CPU和计算机和操作系统,对ELF编址的时候,采用的做法都是采用“平坦模式”进行编址!! 0000000.0000 ~ FFFF....FFFF 按照线性地址,统一编址的!!
5)函数的本质,就是相邻地址的集合!
6)其实线性编址得到的地址,就是我们之前讲的虚拟地址!! 磁盘可执行文件,起始地址+偏移量的这种地址,start: offset,逻辑地址!!! 平坦模式,起始地址是从0开始的.
7)Linux系统里面+平坦模式: 逻辑地址 和 虚拟地址(线性地址) 是一个硬币的两面 ,ELF文件中,逻辑地址; 内存中,虚拟地址!
8)代码也是数据,加载到内存之后,每一行代码都有自己的物理地址!我们程序内部互相调用,互相访问的地址是逻辑(虚拟)地址!!
四、MMU,EIP,CR3,mm_struct,vm_area_struct的关系
1. MMU(内存管理单元)
MMU是CPU内部的一个硬件组件,负责将虚拟地址转换为物理地址。它通过使用页表来实现这一转换,页表中包含了虚拟页和物理页之间的映射关系。在计算机系统中,内存管理单元(MMU,Memory Management Unit)是负责处理所有内存访问的硬件组件。它在虚拟内存系统和物理内存之间起着桥梁的作用。
2. 虚拟地址
虚拟地址是操作系统为每个进程提供的地址空间。它允许每个进程有一个独立的地址空间,即使所有进程都在使用相同的物理内存。虚拟地址由操作系统管理,对用户进程来说是透明的。
3. 物理地址
物理地址是实际内存芯片上的地址。每个物理地址对应一个实际的内存单元。物理地址是硬件可以直接访问的地址。
4. EIP(指令指针)
EIP是x86架构CPU中的一个寄存器,用于存储下一条将要执行的指令的地址。在函数调用和返回时,EIP会被修改以指向新的指令地址。
5. CR3(页目录基址寄存器)
CR3寄存器存储了当前进程的页目录的基地址。当CPU需要访问内存时,它会使用CR3寄存器中的地址来查找页目录,从而进行虚拟地址到物理地址的转换。
6. mm_struct
在Linux内核中,mm_struct 结构体表示一个进程的内存管理信息。它包含了页表、页目录等信息,是操作系统进行内存管理的核心数据结构。
7. vm_area_struct
vm_area_struct 结构体表示一个虚拟内存区域(VMA)。它描述了进程地址空间中的一个连续区域,包括该区域的起始和结束地址、权限(读、写、执行)等信息。
8.关系及联系与转化
虚拟地址到物理地址的转换:
当CPU需要访问内存时,它会从CR3寄存器中获取页目录的基地址。
然后,CPU使用虚拟地址中的页目录项索引和页表项索引在页表中查找对应的物理页。
MMU根据页表中的映射关系将虚拟地址转换为物理地址。
EIP与虚拟地址:
EIP寄存器存储的是虚拟地址,它指向下一条将要执行的指令。
当函数调用发生时,EIP会被修改为新函数的起始地址(虚拟地址)。
mm_struct和vm_area_struct:每个进程都有一个
mm_struct,它包含了该进程的所有vm_area_struct。vm_area_struct描述了进程地址空间中的一个连续区域,这些区域共同构成了进程的虚拟地址空间。
操作系统的内存管理:
操作系统通过
mm_struct和vm_area_struct来管理进程的虚拟内存。当进程访问一个虚拟地址时,操作系统使用
mm_struct中的页表信息通过MMU将虚拟地址转换为物理地址。
总结来说,MMU、虚拟地址、物理地址、EIP、CR3、mm_struct 和 vm_area_struct 共同构成了计算机系统中内存管理和地址转换的基础。MMU负责将虚拟地址转换为物理地址,而mm_struct 和 vm_area_struct 则提供了操作系统进行内存管理所需的数据结构和信息。