深度学习(6):参数初始化
一、任意常数初始化
将所有参数初始化为某个非零的常数(如 0.1,-1 等)。虽然不同于全0和全1,但这种方法依然不能避免对称性破坏的问题。
import torch
import torch.nn as nndef test002():# 2. 固定值参数初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.constant_(linear.weight, 0.63)# 打印权重参数print(linear.weight)passif __name__ == "__main__":test002()"""
Parameter containing:
tensor([[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300]], requires_grad=True)
"""二、随机初始化
方法:将权重初始化为随机的小值,通常从正态分布或均匀分布中采样。
应用场景:这是最基本的初始化方法,通过随机初始化避免对称性破坏。
代码演示:随机分布之均匀初始化
import torch
import torch.nn as nndef test001():# 1. 均匀分布随机初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.uniform_(linear.weight)# 打印权重参数print(linear.weight)if __name__ == "__main__":test001()
"""
Parameter containing:
tensor([[0.4080, 0.7444, 0.7616, 0.0565, 0.2589, 0.0562],[0.1485, 0.9544, 0.3323, 0.9802, 0.1847, 0.6254],[0.6256, 0.2047, 0.5049, 0.3547, 0.9279, 0.8045],[0.1994, 0.7670, 0.8306, 0.1364, 0.4395, 0.0412]], requires_grad=True)
"""
三、Xavier 初始化
也叫做Glorot初始化。
方法:根据输入和输出神经元的数量来选择权重的初始值。权重从以下分布中采样
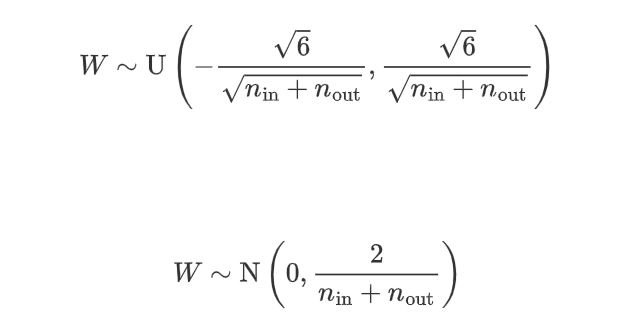
其中 n(in)是当前层的输入神经元数量,n(out)是输出神经元数量。
优点:平衡了输入和输出的方差,适合Sigmoid 和 Tanh激活函数。
应用场景:常用于浅层网络或使用Sigmoid 、Tanh 激活函数的网络。
import torch
from torch import nn# xavier初始化
# 核心思想:
# 1.前向传播的方差一致性
# 2.反向传播的梯度方差一致性# 作用:
# 避免神经网络训练前期出现梯度消失或梯度爆炸def test01():model = nn.Linear(6,4)#w参数:均匀分布初始化nn.init.xavier_uniform(model.weight)#b参数:随机初始化-均匀分布nn.inite.uniform(model.bias)print(model.weight)"""
tensor([[-0.6347, 0.4248, -0.3963, 0.6780, 0.7441, -0.0334],[ 0.2761, -0.6402, -0.2494, 0.2563, -0.2318, -0.1867],[-0.2232, -0.1069, -0.4601, -0.5499, -0.2174, -0.7201],[-0.6542, 0.2042, -0.5671, 0.2029, -0.2438, 0.0544]],requires_grad=True)
"""
def test02():model = nn.Linear(6, 4)# w参数:正态分布初始化nn.init.xavier_normal_(model.weight)# b参数:随机初始化-正态分布nn.init.normal_(model.bias)print(model.weight)print(model.bias)"""
Parameter containing:
tensor([-1.1664, 1.3327, -0.9933, -1.9076], requires_grad=True)
"""
if __name__ == '__main__':# test01()test02()四、He初始化
也叫kaiming 初始化。
方法:专门为 ReLU 激活函数设计。权重从以下分布中采样:
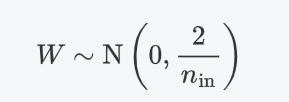
其中n(in)是当前层的输入神经元数量。
优点:适用于ReLU和 Leaky ReLU激活函数。
应用场景:深度网络,尤其是使用 ReLU 激活函数时。
import torch
from torch import nn# He初始化(kaiming)
# 核心思想:
# 1.前向传播的方差一致性
# 2.反向传播的梯度方差一致性# 作用:
# 避免神经网络训练前期出现梯度消失或梯度爆炸# 两种模式:
# 1.fan_in:优先保证前向传播的方差一致性,默认
# 2.fan_out:优先保证反向传播的梯度方差一致性def test03():model = nn.Linear(6, 4)# w参数:kaiming正态分布初始化nn.init.kaiming_normal_(model.weight)# b参数:随机正态分布初始化nn.init.normal_(model.bias)print(model.weight)def test04():model = nn.Linear(6, 4)# w参数:kaiming均匀分布初始化nn.init.kaiming_uniform_(model.weight)# b参数:随机均匀分布初始化nn.init.uniform_(model.bias)print(model.weight)# 当创建Linear线性层时,pytorch默认使用kaiming_uniform_对w参数进行初始化,使用uniform_对b参数进行初始化if __name__ == '__main__':# test03()test04()