机器学习之词向量转换
简介
jieba库、朴素贝叶斯算法和TF-IDF值是自然语言处理(NLP)中常用的工具和技术,各自在文本处理的不同阶段发挥作用。 在自然语言处理的世界里,如何让计算机 “读懂” 人类语言一直是核心难题,而词向量转换正是破解这一难题的关键钥匙。本次机器学习专题,我们就来深入探讨这一基础又核心的技术。词向量转换的本质,是将文本中离散的词语转化为连续的数值向量。这一步看似简单,却实现了从 “机器无法理解的文字” 到 “可计算的数字” 的跨越,为后续的文本分类、情感分析、机器翻译等任务铺平了道路。
一、词向量转换相关概念
1.为什么需要词向量转换
人类语言丰富多样,单词具有语义、语法和语境等多重信息。但计算机擅长处理数值数据,原始文本无法直接被计算机理解和分析。词向量转换通过将单词转换为数值向量,把语言信息编码成计算机能处理的形式。这样,计算机可以利用这些向量进行计算,从而挖掘文本中的有用信息,实现对文本的理解和处理。
2.词向量转换的分类
特征提取库中导入向量转化模块,自然语言转换成数据的形式,才能保证模型进行训练。
- 1、基于统计的方法 统计每个单词在这句话中出现的次数
- 2、基于神经网络模型训练的方法
今天讲述的是基于统计的方法进行词向量转换,第二种要利用深度学习的知识,后面再说。
二、算法应用
我们以一个小例子来说明词向量转换的代码过程
1.首先导入了CountVectorizer类,这是用于将文本转换为词频向量的工具
from sklearn.feature_extraction.text import CountVectorizer
CountVectorizer(input='content', # 输入类型:'content'(直接文本)、'filename'(文件路径)、'file'(文件对象)encoding='utf-8', # 文本编码格式decode_error='strict', # 解码错误处理:'strict'(报错)、'ignore'(忽略)、'replace'(替换)strip_accents=None, # 去除重音符号:None(不处理)、'ascii'(仅ASCII字符)、'unicode'(所有字符)lowercase=True, # 是否将文本转为小写(默认True)preprocessor=None, # 自定义预处理函数(输入文本字符串,返回处理后的字符串)tokenizer=None, # 自定义分词函数(输入文本字符串,返回分词列表)stop_words=None, # 停用词:None(不处理)、'english'(内置英文停用词)、自定义列表token_pattern=r'(?u)\b\w\w+\b', # 分词正则表达式(默认匹配2个及以上字符的单词)ngram_range=(1, 1), # 提取n元词范围,如(1,2)表示同时提取1元词和2元词analyzer='word', # 分析单位:'word'(按词)、'char'(按字符)、'char_wb'(按字符,不跨越词边界)max_df=1.0, # 最大文档频率(过滤高频词):0~1(比例)或整数(文档数)min_df=1, # 最小文档频率(过滤低频词):0~1(比例)或整数(文档数)max_features=None, # 保留的最大特征数(按词频排序取前N个)vocabulary=None, # 自定义词汇表(字典或列表,指定要提取的词)binary=False, # 是否将词频转为二进制(1表示出现,0表示未出现,默认False)dtype=np.int64 # 输出矩阵的数据类型
)2.定义了一个文本列表texts,包含 4 个字符串元素:
texts = ['apple banana orange','apple banana banana','orange pear','pear']3.创建了CountVectorizer实例,并设置了两个参数:
ax_features=6:只保留出现频率最高的 6 个特征(词语或词组)ngram_range=(1,3):考虑 1 元词(单个词)、2 元词(两个词的组合)和 3 元词(三个词的组合)
4.cv.fit_transform(texts)对文本进行拟合和转换:
fit:分析文本,构建词汇表transform:将文本转换为词频矩阵
5.print(cv_fit)输出的是一个稀疏矩阵表示,格式为(文档索引, 特征索引) 词频
(0, 0) 1(0, 3) 1(0, 4) 1(0, 1) 1(1, 0) 1(1, 3) 2(1, 1) 1(1, 2) 1(2, 4) 1(2, 5) 1(3, 5) 1表示第 0 个文档中,索引 0的特征出现 1 次,索引 3的特征出现 1 次等
6.cv.get_feature_names_out()返回所有提取的特征名称(词汇表),根据示例会输出类似:
['apple' 'apple banana' 'apple banana banana' 'banana' 'orange' 'pear']7.cv_fit.toarray()将稀疏矩阵转换为稠密矩阵(二维数组),每行代表一个文档,每列代表一个特征,值为该特征在对应文档中的出现次数:
[[1 1 0 1 1 0][1 1 1 2 0 0][0 0 0 0 1 1][0 0 0 0 0 1]]| 文本内容 | apple | apple banana | apple banana banana | banana | orange | pear |
|---|---|---|---|---|---|---|
| apple banana orange | 1 | 1 | 0 | 1 | 1 | 0 |
| apple banana banana | 1 | 1 | 1 | 2 | 0 | 0 |
| orange pear | 0 | 0 | 0 | 0 | 1 | 1 |
| pear | 0 | 0 | 0 | 0 | 0 | 1 |
三、案例分析
这里有从苏宁上爬取的关于手机的评论,一个好评与一个差评文件
1.数据集
差评
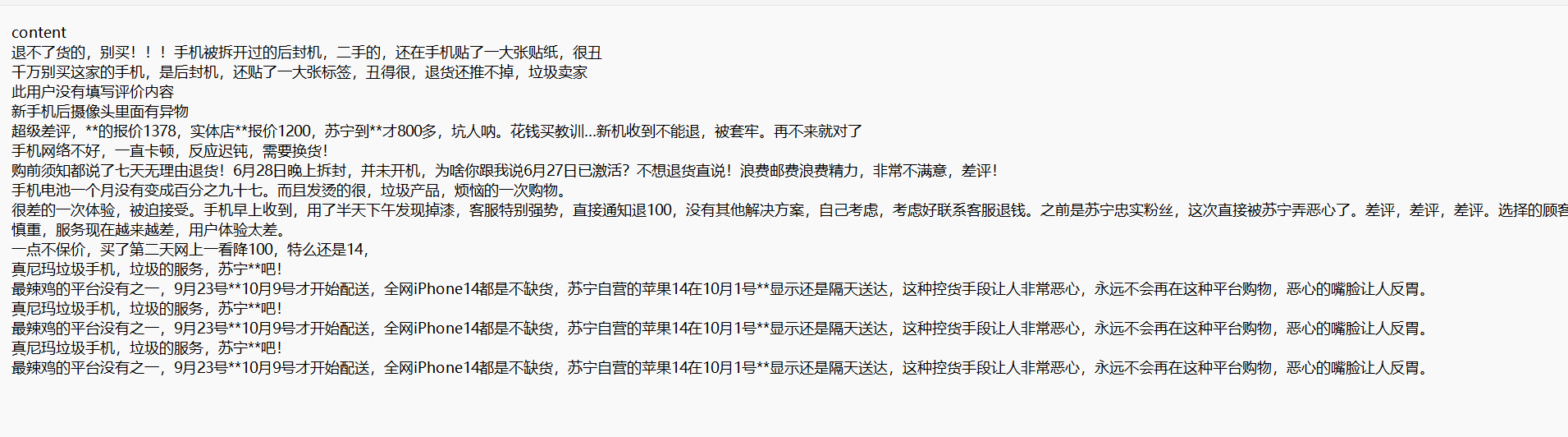
好评

2.整体功能概述
这段代码主要实现了 中文文本情感分类的前期数据处理与特征工程流程,包括:
- 读取好评、差评文本数据;
- 用
jieba进行中文分词; - 去除停用词(高频无意义词汇,如 “的”“了” 等 );
- 构建带标签的训练数据集;
- 拆分训练集、测试集;
- 用
CountVectorizer将分词后的文本转换为词频特征矩阵,为后续机器学习模型(如分类器)做准备。
3.代码分步详解
1.库与模块导入
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jiebaCountVectorizer:用于将文本转换为词频矩阵(scikit-learn 工具);pandas(别名pd):处理表格型数据(读取文件、DataFrame 操作);jieba:中文分词库,把连续的中文文本拆分为词语列表。
2. 读取原始数据
hp_content = pd.read_table("好评.txt", encoding='gbk')
cp_content = pd.read_table("差评.txt", encoding='gbk')- 用
pd.read_table读取本地文本文件,encoding='gbk'适配 GBK 编码(需确保文件实际编码一致,否则会报错 ); hp_content、cp_content是DataFrame类型,存储 “好评”“差评” 文本数据,默认有一列content存文本内容。
3.中文分词(差评 + 好评)
差评分词:
cp_segements = []
contents = cp_content.content.values.tolist()
for content in contents:results = jieba.lcut(content) # 精确模式分词,返回词语列表if len(results) > 1: # 过滤分词后长度<1的(避免空内容)cp_segements.append(results)cp_fc_results = pd.DataFrame({'content': cp_segements})
cp_fc_results.to_excel('cp_fc_results.xlsx', index=False)- 先提取
cp_content中content列的文本,转成列表遍历; jieba.lcut(content)对单条文本分词,结果是list(如 “这个产品好” →["这个", "产品", "好"]);- 用
DataFrame存储分词结果,再导出为 Excel(index=False不存行索引 )。
好评分词(逻辑与差评完全一致 ):
hp_segements = []
contents = hp_content.content.values.tolist()
for content in contents:results = jieba.lcut(content)if len(results) > 1:hp_segements.append(results)hp_fc_results = pd.DataFrame({'content': hp_segements})
hp_fc_results.to_excel('hp_fc_results.xlsx', index=False)4. 读取停用词
stopwords = pd.read_csv('StopwordsCN.txt',encoding='utf-8',engine='python',header=None,names=['word'],sep='\t'
)- 读取停用词表(通常是纯文本,每行一个停用词 );
header=None表示文件无表头,names=['word']手动设列名,sep='\t'用制表符分隔(按实际文件格式调整 );- 最终
stopwords是DataFrame,一列word存停用词。
5. 定义并调用 “去除停用词” 函数
def drop_stopwords(contents, stopwords):segments_clean = []for content in contents: # 遍历每条分词后的文本(列表套列表结构)line_clean = []for word in content: # 遍历单条文本的词语if word in stopwords: # 若词语在停用词表中,跳过continueline_clean.append(word) # 否则保留词语segments_clean.append(line_clean) # 收集单条文本清洗后的词语列表return segments_clean- 输入:
contents是分词后的文本列表(如[["这个","产品","好"], ...]),stopwords是停用词列表; - 输出:清洗后的词语列表(过滤掉停用词 )。
调用函数处理差评、好评数据:
# 处理差评
contents = cp_fc_results.content.values.tolist() # 从 DataFrame 提取分词结果(列表格式)
stopwords = stopwords.word.values.tolist() # 停用词 DataFrame → 列表
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)# 处理好评(逻辑同上)
contents = hp_fc_results.content.values.tolist()
hp_fc_contents_clean_s = drop_stopwords(contents, stopwords)6. 构建带标签的训练数据集
cp_trian = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s, 'label': 1}) # 差评标签设为 1
hp_train = pd.DataFrame({'segments_clean': hp_fc_contents_clean_s, 'label': 0}) # 好评标签设为 0
pj_train = pd.concat([cp_trian, hp_train]) # 合并差评、好评数据
pj_train.to_excel("pj_train.xlsx", index=False) # 导出合并结果label是情感标签:1代表 “差评”,0代表 “好评”;pd.concat按行合并两个DataFrame,形成完整训练数据集
7. 拆分训练集、测试集
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(pj_train['segments_clean'].values, # 特征:清洗后的分词列表pj_train['label'].values, # 标签:情感类别(0/1)random_state=0
)train_test_split按默认比例(一般 75% 训练、25% 测试 )拆分数据;x_train/x_test是特征数据(分词列表 ),y_train/y_test是对应标签。
8. 文本转词频特征(为模型做准备)
words = []
for line_index in range(len(x_train)):words.append(' '.join(x_train[line_index])) # 分词列表 → 用空格连接成字符串(如 ["这个","产品"] → "这个 产品" )
print(words)from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=4000, ngram_range=(1, 3)) # 初始化向量器
vec.fit(words) # 基于训练集构建词汇表x_train_vec = vec.transform(words) # 训练集文本 → 词频矩阵
print("a")构建可入模的文本格式:
CountVectorizer要求输入是 “用空格连接的字符串”,所以用' '.join(...)把分词列表转成字符串(如["这个","产品"]→"这个 产品")。CountVectorizer配置与作用:max_features=4000:只保留词频最高的 4000 个词(控制特征数量,避免维度爆炸 );ngram_range=(1, 3):提取 1 元词(单个词)、2 元词(两个词组合,如 “这个 产品” )、3 元词(三个词组合 );vec.fit(words):扫描words里的文本,统计词频并构建词汇表(后续用这个词汇表转换文本 );vec.transform(words):将训练集文本转换为 稀疏矩阵(每行是一条文本,每列是一个词,值是词频 ),供机器学习模型(如逻辑回归、SVM )使用。