如何简单捋一遍LLM结构
今天以glm4_moe为例简单分享一下如何读懂LLM框架~
首先需要安装 transformers 库, 然后找到transformers库在电脑中的位置,一般是在:
your_python_env/site-packages/transformers/models/也可以直接在搜索栏中输入'transformers'搜索文件夹
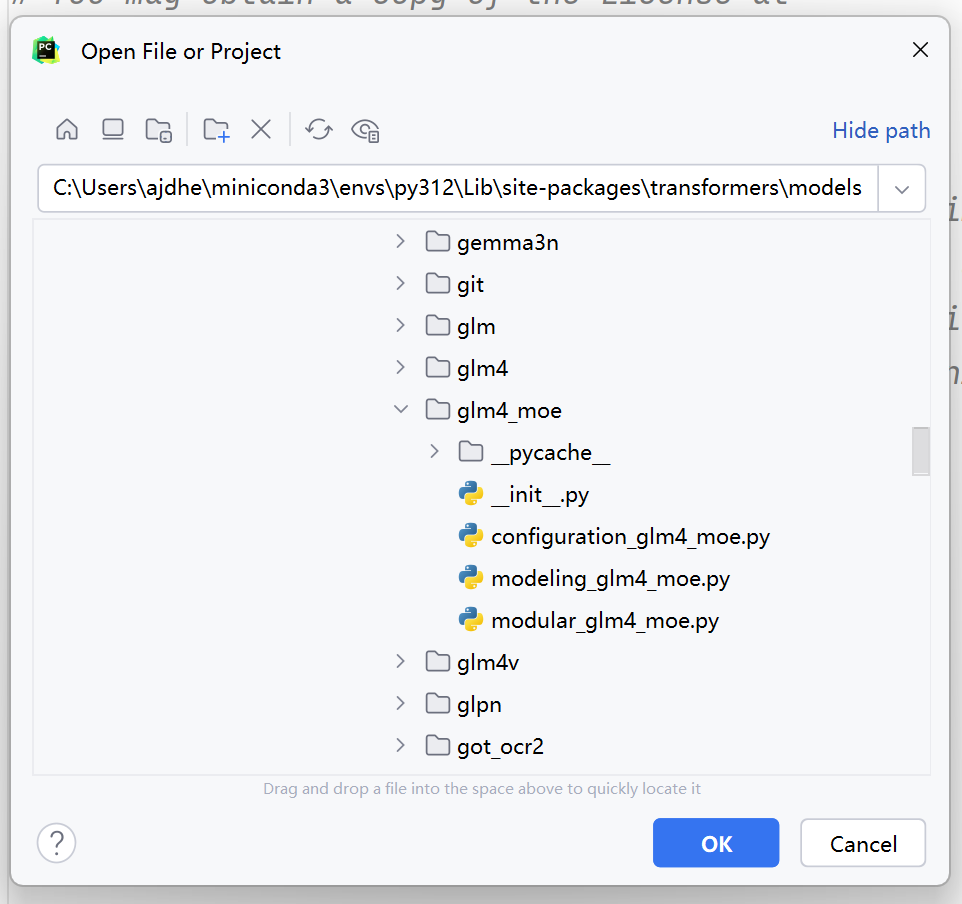
可以看到, glm4_moe下有四个文件,其中configuration文件是模型的配置信息, modeling文件是模型的结构信息,所以主要讲一下modeling文件
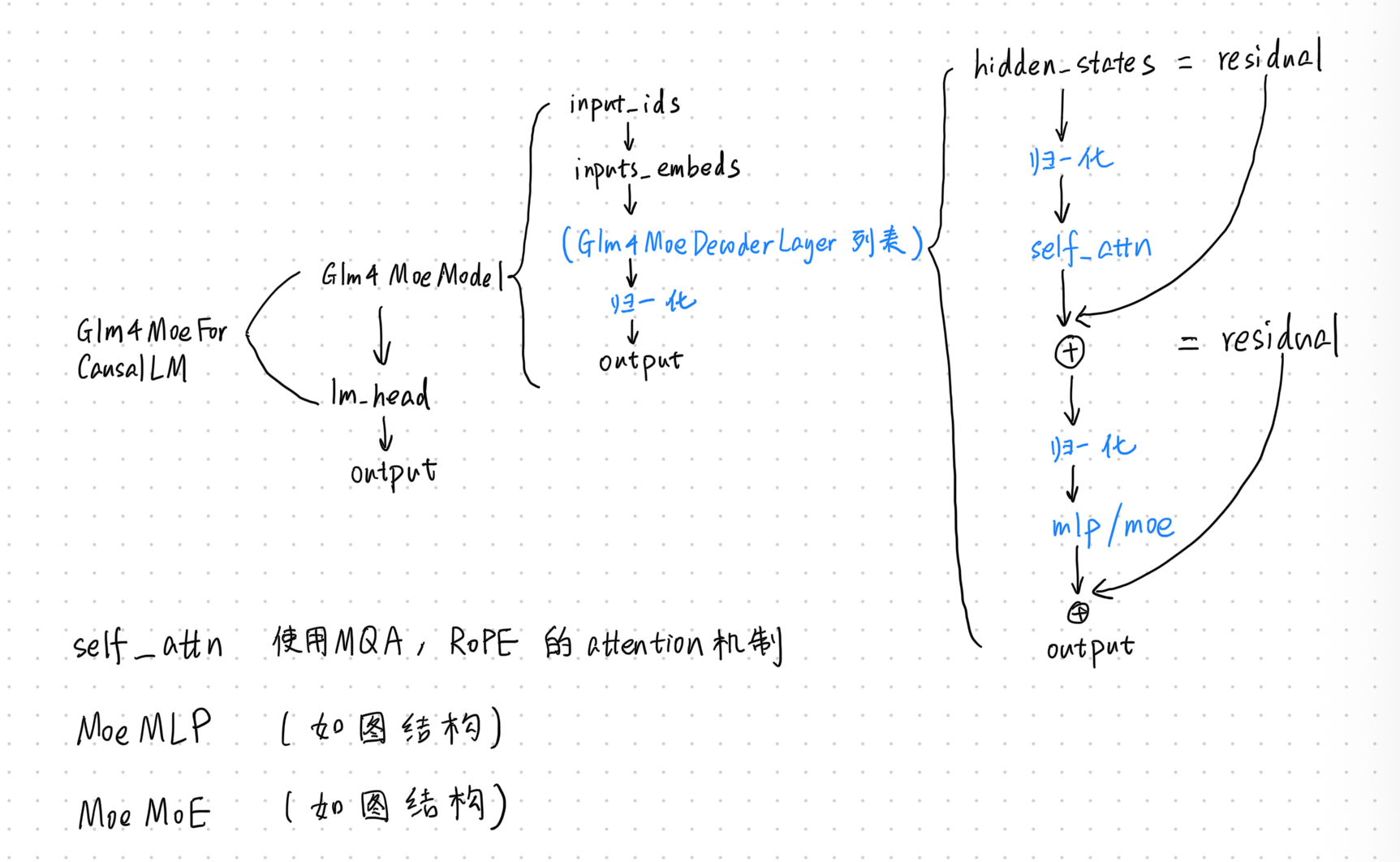
不用从头开始看, 可以翻到最后一个类,
Glm4MoeForCausalLM
这就是GLM模型用于做自回归的类,在 __init__中可以看到Glm4MoeModel, 这是真正用到的模型
另外还有一个线性层
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
这个线性层映射到词表大小,是用来预测下一个字的.
所以GLM模型由基础模型Glm4MoeModel和线性层lm_head组成
接着看forward部分, 首先将input送入基础模型Glm4MoeModel, 然后将输出的最后一个hidden_state 送入线性层lm_head,然后计算损失函数等.
基础模型Glm4MoeModel
这个部分也在同一个文件中. 在pytorch中,模型结构都分为两部分,一部分是__init__,一部分是forward, __init__会定义所有会用到的层,forward会将__init__中定义的层串起来,定义前向计算的过程.
先看__init__, self.padding_idx和self.vocab_size继承了config中的参数, self.embed_tokens定义了embedding层,self.layers层是一个列表结构的transformer层结构,还有self.norm(使用RMSNorm结构),self.rotary_emb(使用旋转位置编码)等.其中的重点是self.layers层
我们仔细看一下self.layers层中的Glm4MoeDecoderLayer结构.(说明了看代码不要从头开始看,而是应该一层一层的看!想重点关注哪一层的时候看哪一层)看__init__部分可以看到有attention部分Glm4MoeAttention和MoE部分Glm4MoeMoE,
if layer_idx >= config.first_k_dense_replace:
说明是根据层索引决定前馈网络类型:MoE或普通MLP. 这种设计可以在保持模型性能的同时平衡计算成本,因为 MoE 结构通常比普通 MLP 计算量更大。
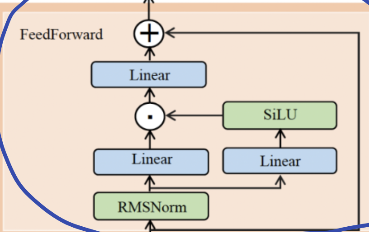
Glm4MoeMLP部分
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
输入先过一个线性层,再过一个激活,然后和另一个过线性层的输入相乘,最后再过一个线性层. 基本结构如下:
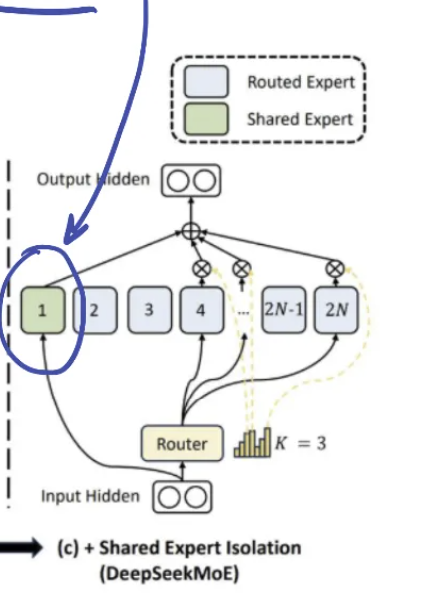
Glm4MoeMoE部分 (待补充完善 ^_^)
Moe由若干个MLP(专家),共享专家,路由层(线性层)组成,基本结构如下:
Glm4MoeTopkRouter
在 MoE 模型中,路由层(Router)是连接输入与专家网络的 “调度中心”:
- 输入:模型的隐藏状态(每个 token 的特征表示);
- 输出:每个 token 对应的 Top-K 专家索引(
topk_indices)和权重(topk_weights); - 目标:让每个 token 只被最擅长处理它的少数专家(而非所有专家)处理,在控制计算量的同时最大化模型能力。
experts/ shared_experts
传统 MLP 层的中间层大小(若存在)通常远大于 MoE 层中单个专家的中间层大小,通过查看config文件可以发现,glm4moe中也是如此,intermediate_size=10944, moe_intermediate_size=1408,这一设计是 MoE 架构通过 “多专家并行” 替代 “单一大型网络” 的核心体现,既提升了模型容量,又控制了实际计算开销。

moe
这段代码实现了 MoE 的核心逻辑:通过门控网络选择的 Top-K 专家索引和权重,将每个 token 分配给对应的专家处理,再加权融合所有专家的输出。其本质是通过 "动态路由" 让不同 token 由最擅长处理它们的专家网络(子模型)处理,从而在相同计算量下提升模型能力。
这边作者还用注释留了一个问题,
当前问题:用循环遍历每个专家(如 256 个专家)会导致效率低下,尤其是在大规模模型中。
Glm4MoeAttention部分
__init__中首先有一些继承自config的参数,然后是q_proj,k_proj,v_proj,线性层需要关注维度,可以看到kv的维度比q小很多,说明这里采用了MQA.
再看一下forward部分, 首先传入上一层的hidden states(batch_size,seq_len,hidden_dim), 然后进入q_proj,k_proj,v_proj,接着看是否需要使用归一化(根据config没有做归一化) 接下来使用了RoPE旋转位置编码,跳过一些判断之后,可以看到一个计算attention的部分(attention_interface),最后输出output.可以说是在传统attention结构的基础上做了一些改进.
今天先写到这里,有什么问题欢迎评论区留言 ^_^
像模型中的一些代码细节如果不懂的话可以问市面上主流的大模型,虽然小概率会答错,但是总的来说感觉大模型还是比较了解自身的(冷笑话)