NLP基础
一、基本概念
自然语言处理(NLP)的主要目的是让计算机能够理解、解释和生成人类语言的数据。
NLP的应用方向包括:
1.自然语言理解(NLU):情感分析——对于给定的文本输入,在给定的选项范围内分析文本的情绪是正面还是负面的;文本分类——对于给定的文本输入,在给定的选项范围内对文本进行二分类或多分类;信息检索——搜索引擎依托于多种技术,如网络爬虫技术、检索排序技术、网页处理技术、大数据处理技术、自然语言处理技术等,为信息检索用户提供快速、高相关性的信息服务等等
2.自然语言转换(NLT):机器翻译;非抽取式阅读理解;文本风格转换;语音识别
3.自然语言生成(NLG):文本生成;语音合成;聊天机器人;文本到知识;语义解析;
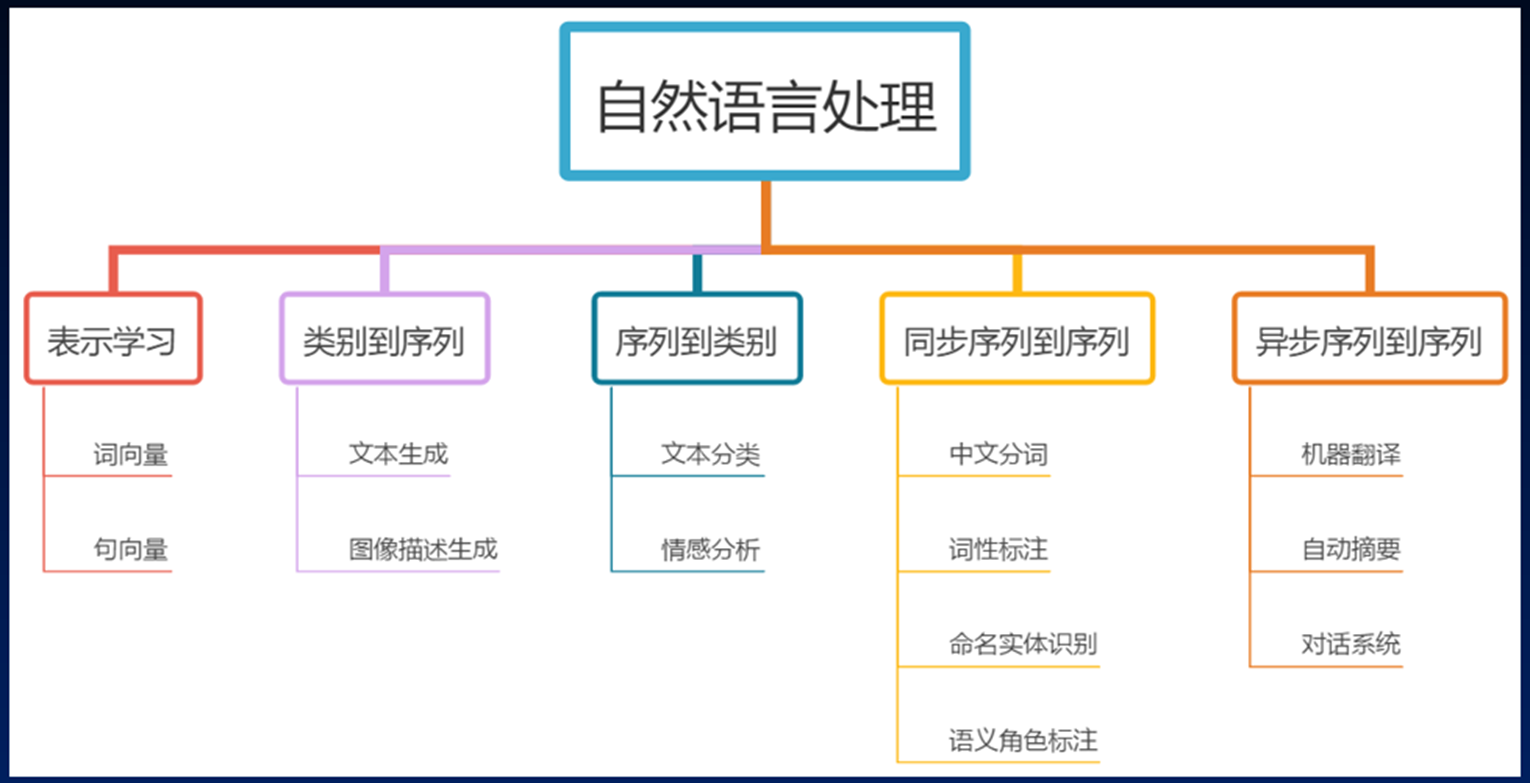
基础概念
(1)词表/词库:文本数据集中出现的所有单词的集合
(2)语料库:用于NLP任务的文本数据集合,可以是大规模的书籍、文章、网页等
(3)词嵌入:将单词映射到低维连续向量空间的技术,用于捕捉单词的语义和语法信息
(4)序列:指的是一个按顺序排列的元素集合,这些元素可以是字符、单词、句子,甚至更抽象的结构。序列的每个元素都有特定的顺序和位置,这意味着他们不能随意重排,否则会影响期意义或功能。
其他概念不再细说
二、NLP中的特征工程
特征是数据抽取出来的对结果预测有用的信息
在NLP中,特征工程是指将文本数据转换为适合机器学习模型使用的数值表示的过程。
通过特征工程能让机器学习到文本数据中的一些特征,比如磁性、语法、相似度等。
1、词向量
词向量是对词语义或含义的数值向量表示,包括字面意义和隐含意义。 词向量可以捕捉到词的内涵,将这些含义结合起来构成一个稠密的浮点数向量,这个稠密向量支持查询和逻辑推理。
词向量也称为词嵌入,其英文均可用 Word Embedding,是自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词表的单词或短语被映射为实数的向量,这些向量能够体现词语之间的语义关系
2、传统NLP中的特征工程(不细说)
2.1 独热编码(One-Hot Encoding)
是一种常见的特征表示方法,通常用于将离散的类别型数据转换为数值型表示,以便输入到机器学习模型中。它的特点是将每个类别表示为一个向量,在该向量中,只有一个元素为1,其余元素全部为0
2.2 词频-逆文档频率(TF-IDF)
文档频率和样本语义贡献程度呈反相关
文档频率和逆文档频率呈反相关
逆文档频率和样本语义贡献度呈正相关
2.3 n-grams
使用 n-grams 可以捕捉词之间的局部上下文关系。例如,1-gram 只关心词的独立出现频率,而 bigram 和 trigram 能捕捉到词之间的顺序关系。例如,bigram "love NLP" 表示词 "love" 和 "NLP" 是一起出现的,这种信息在建模中会比仅仅知道 "love" 和 "NLP" 出现频率更有价值。
假设句子为 "I love NLP and machine learning":
1-gram(Unigram):
["I", "love", "NLP", "and", "machine", "learning"]2-grams(Bigram):
["I love", "love NLP", "NLP and", "and machine", "machine learning"]3-grams(Trigram):
["I love NLP", "love NLP and", "NLP and machine", "and machine learning"]
传统NLP中的特征工程缺点:
1.词典有多长,向量就有多长,计算量巨大
2.太稀疏,使用的是One-Hot编码,向量中大多数都是0
3.语义鸿沟
3. 深度学习中NLP的特征输入
深度学习使用分布式单词表示技术(也称词嵌入表示),通过查看所使用的单词的周围单词(即上下文)来学习单词表示。这种表示方式将词表示为一个粘稠的序列,在保留词上下文信息同时,避免维度过大导致的计算困难。
3.1 稠密编码(特征嵌入)
稠密编码在机器学习和深度学习中,通常指的是将离散或者高维稀疏数据转化为低维的连续、密集向量表示。这种编码方式在特征其中纳入中尤为常见。
特征嵌入:也称为词嵌入,是稠密编码的一种表现形式,目的是将离散的类别、对象或其他类型的特征映射到一个连续的向量空间。通过这种方式,嵌入后的向量可以捕捉不同特征之间的语义关系,并且便于在后续的机器学习模型中使用。
3.2 词嵌入算法
Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。
词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
在 PyTorch 中,我们可以使用 nn.Embedding 词嵌入层来实现输入词的向量化。接下来,我们将会学习如何将词转换为词向量,其步骤如下:
先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引;
然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
nn.Embedding(num_embeddings=10, embedding_dim=4)num_embedding 表示词的数量
embedding_dim 表示每个词用多少维的向量来表示,即每个词有多少个特征
embedding是一个类,用这个类创建的实例可以传入索引来提取对应词汇的向量表示。
3.3 word2vec
word2vec 一般分为CBOW和Skip-Gram两种模型:
CBOW :根据中心词周围的词来预测中心词
Skip-Gram:根据中心词来预测周围词
Skip-Gram 模型的优点:由于它是基于目标单词来预测上下文单词的,因此它可以利用目标单词的语义和语法特征来预测上下文单词;模型能够生成更多的训练数据,因此可以更好地训练低频词汇的表示;Skip-Gram 模型在处理大规模语料库时效果比CBOW模型更好。