大语言模型(LLM)核心概念与应用技术全解析:从Prompt设计到向量检索
1 LLM关键概念👑
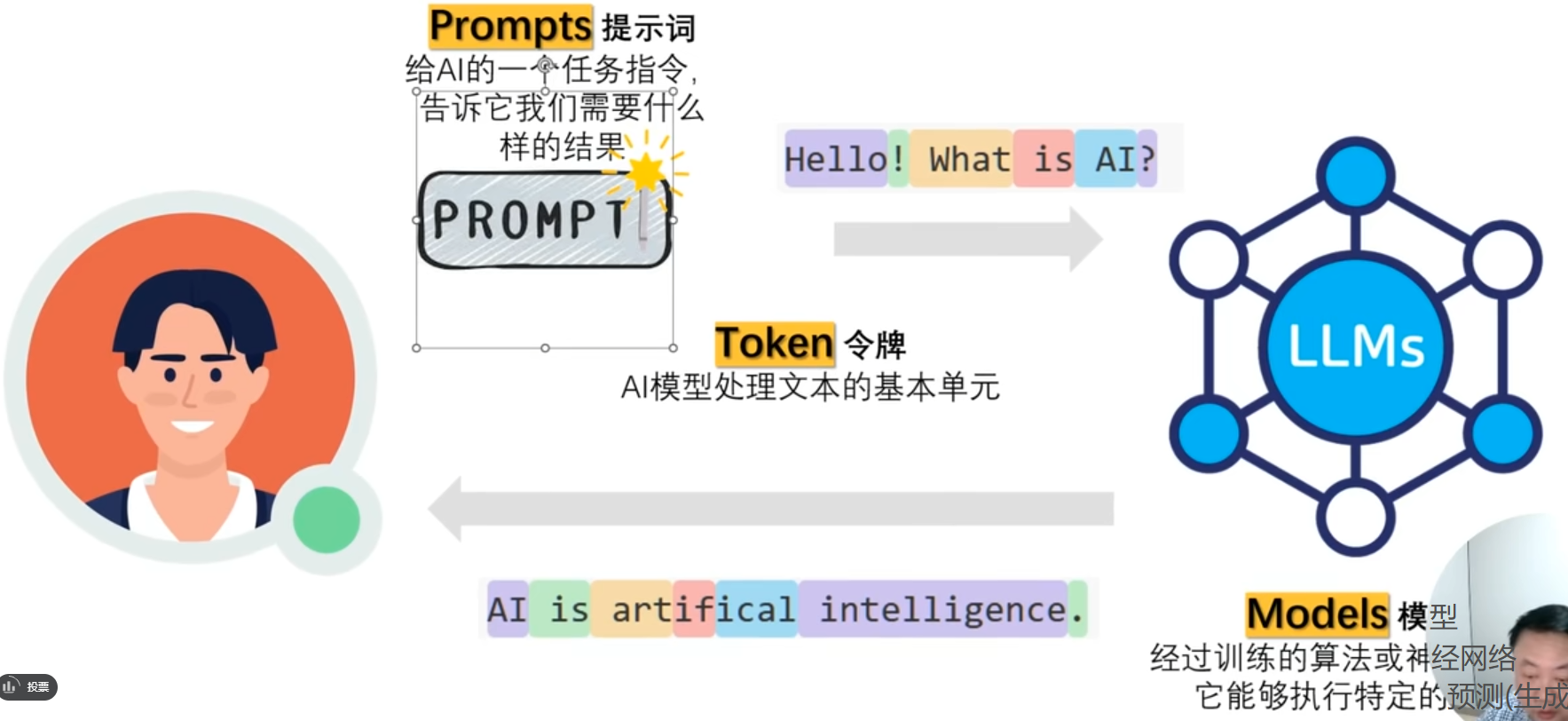
🎈1.1 Prompts提示词
用户的输入就是一个Prompts提示词,提示词来源是用户的提问,途径是经过embedding后输入去模型。
我们一般写Prompts提示词的结构就是一句话,但是如果使用结构化Prompts提示词,那么效果会好很多的,下面是一个结构化Promopts提示词的模板:
## Role
本科论文写作导师## Profile
- author: Kevin
- version: 0.1
- language: 中文
- description: 你是一名经验丰富的本科生导师,能够指导学生写出优秀的毕业论文。## Goals
1. 严格按照写作要求,写出一篇符合本科要求的论文。## Constraints
1. 使用 Markdown 格式。
2. 体现学术创新性。## Skills
1. 拥有丰富的本科论文指导经验。
2. 具备强大的需求理解能力。## Workflow
1. 引导用户输入需要写作的论文方向。
2. 根据用户提供的【论文方向】,为用户提供几个选题。
3. 根据用户确认的【选题】生成论文大纲,并向用户确认是否合理。- 如果用户觉得不合理,需要重新生成。- 如果合理,执行下一步。
4. 按照生成的【论文大纲】,逐节生成内容。- 每生成一节,需要与用户确认是否合理。## Initialization
向用户简单介绍你自己,严格按照【Workflow】开始工作。
🎈1.2 Token令牌
Token 是自然语言处理中一个AI大模型处理文本的一个基本单元,也是基于此来收费的,单位是Token/¥。其通常指的是文本被拆分后的最小单位。不同的模型对 Token 的定义和计算方式有所差异,这直接影响模型的输入长度限制和计算效率。
在传统的 NLP 模型中,Token 通常是单词或子词(subword),例如英文中的单词“playing”可能被拆分为“play”和“ing”两个 Token。而在一些更先进的模型中,Token 可能是更细粒度的字符片段,甚至是字节对编码(Byte Pair Encoding, BPE)生成的子单元。
不同模型的 Tokenizer(分词器)设计决定了 Token 的粒度和数量:
- 基于空格分词:简单直接,但对复合词和多义词处理有限。
- 子词分词(Subword Tokenization):如 BPE、WordPiece,能够有效处理未登录词和词形变化,提高模型泛化能力。
- 字符级分词:粒度最细,适合处理拼写错误或低资源语言,但计算量较大。
Token 的计算方式不仅影响模型的输入长度限制,还关系到模型的训练和推理效率。比如,GPT 系列模型对 Token 数量有限制,超过限制需要截断或分批处理。
🎈1.3 LLM大模型的局限性

① 大模型是预训练模型。例如 LLaMA、GPT-4o、DeepSeek 等,这些模型的训练依赖于海量且公开的互联网数据。训练完成后,模型的知识库即固定下来,不会随时间自动更新。举例来说,如果模型的训练截止于2024年4月23日,那么它所掌握的知识也就停留在那个时间点,之后发生的新知识、新事件都无法被模型直接感知。
需要特别说明的是,联网查询只是大模型的一个辅助插件功能,并非模型本身具备实时更新的知识。通过联网查询,模型可以实时爬取互联网数据,再结合检索增强生成(RAG)技术,将外部信息融入回答中,从而呈现出“知识库具备实时性”的假象。实际上,模型本体的知识库依然是静态的,实时性来源于外部检索和后续处理,而非模型自身的动态更新。
② 大模型的知识库本质上是私有化的,尽管训练数据来源于公开的互联网海量信息,但模型对私有化数据的理解和处理能力有限。当遇到企业内部文档、专有数据库等私有数据时,模型往往会产生偏差甚至错误,因为这些信息未被纳入训练语料。
解决方案:针对上述问题,目前主要有两种有效的技术手段:
RAG(检索增强生成)
适用于大多数文献资料、文字版本的知识库。通过先检索相关文档,再结合生成模型进行回答,既保证了信息的时效性,也提升了回答的准确度和丰富度。SFT(监督微调)
适用于问答类数据,尤其是专业领域如法律咨询、医学问诊等。通过在特定领域的高质量问答数据上进行微调,使模型更精准地理解和回答专业问题,减少误差和偏差。
2 LLM应用落地核心技术👑
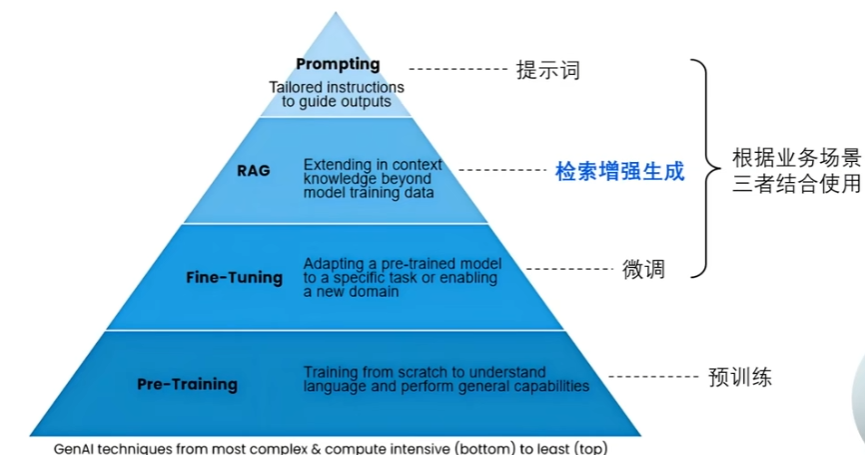
- Prompting(提示设计):Prompting 是通过设计输入提示,引导大语言模型生成特定内容的方法。它利用模型预训练时学到的语言知识,通过巧妙构造问题或示例,激发模型在零样本或少样本条件下完成任务,无需修改模型参数。
- RAG(检索增强生成):RAG 是结合信息检索和生成模型的技术,先检索相关文档,再基于这些文档生成答案,即两者共同结合后输出结果。它通过动态调用外部知识库,弥补模型预训练知识的时效性和覆盖不足,提高生成内容的准确性和可信度。
- Fine-Tuning(微调):Fine-Tuning 是在预训练模型基础上,用特定任务数据继续训练模型参数,使其更适应具体应用。通过调整模型权重,使得模型实际掌握的数据更加私有化,能够通过这种方式使得模型涵盖自己企业的知识库或者个人的知识库。
- Pre-Training(预训练):Pre-Training 是用海量无标注文本训练模型,让其学习语言结构和世界知识。通过自监督学习,模型掌握通用语言能力,为后续任务的零样本、少样本学习和微调打下基础。
3 Embedding Model向量模型👑
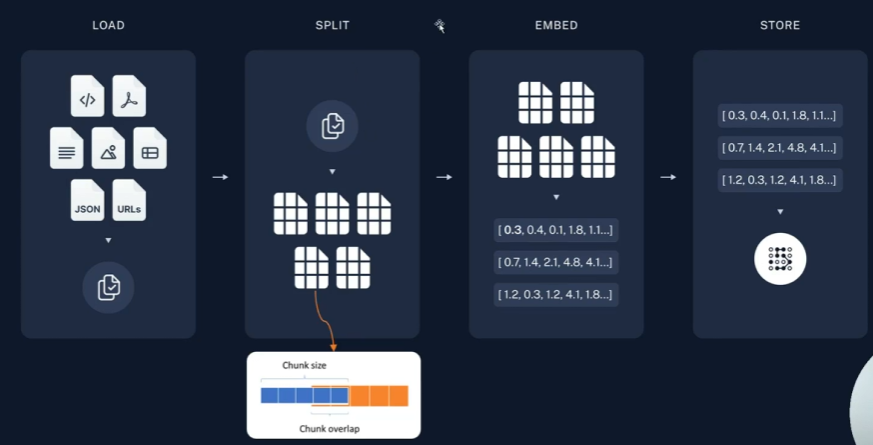
Embedding Model向量模型构建的步骤如上图所示,加载->拆分->嵌入->存储。
🎈3.1 Vector and Embeddings向量与文本向量
向量(Vector)是一种有大小和方向的数学对象,它可以表示为从一个点到另一个点的有向线段
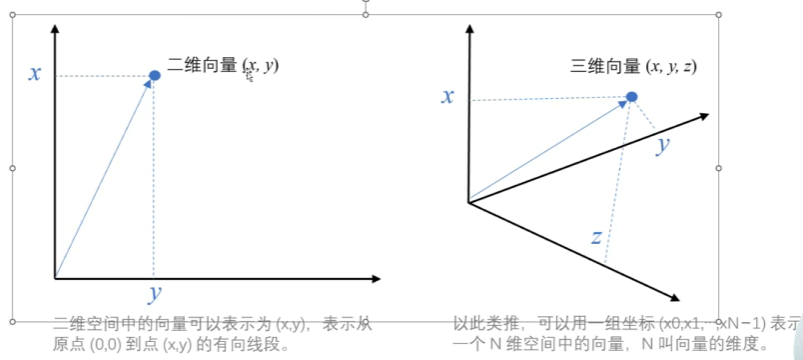
文本向量(Embeddings)就是:将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings。向量之间可以计算距离,距离远近对应语义相似度大小。
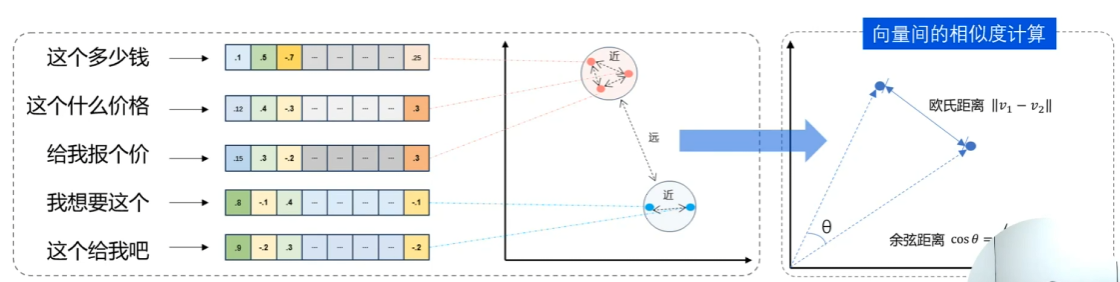
“这个多少钱”,“这个什么价格”,“给我报个价”这三个句子其实是同一个意思,它们三个位于文本向量空间时,一个正确的布局应当是近邻的。通过这样的位置信息,可以用于计算语义相似度。
从”文本“到“一组N维浮点数”的映射,是通过Embedding 训练神经网络模型(如Word2Vec、GloVe、BERT等),学习将词语、短语甚至整句文本映射到一个多维实数空间中去的。这个空间中的每个维度代表某种潜在的语义特征。
🎈3.2 Load and split(加载数据与拆分)
🥒简单文本处理:使用 LangChain 的 RecursiveCharacterTextSplitter 工具,基于预设的分隔符对文本进行拆分。常用的分隔符包括:
- 双换行符
"\n\n":通常用于区分段落。 - 单换行符
"\n":用于区分行或句子。
🥒复杂文本处理:
基于NLP篇章分析(discourse parsing)的方法
利用NLP篇章分析工具,提取文本中段落之间的逻辑关系,特别是识别主从、因果、对比等篇章结构。针对所有包含主从关系的段落,将它们合并成一个更大的语义单元,以保持上下文的连贯性和完整性。基于BERT NSP(Next Sentence Prediction)训练任务的方法
利用BERT模型中训练得到的Next Sentence Prediction能力,计算相邻两个段落的语义相似度。通过设定相似度阈值 tt,从文本前往后依次判断相邻段落的相似度分数:若相似度大于等于阈值,则合并这两个段落;否则保持段落独立,断开处理。
🎈3.3 向量检索引擎(Vector Search Engine)和向量数据库(Vector Database)
随着Embedding技术的广泛应用,如何高效存储和快速检索海量高维向量成为关键问题。向量检索引擎(Vector Search Engine)和向量数据库(Vector Database)应运而生,它们通过构建高效的索引结构(如倒排索引、近似最近邻算法ANN等),实现对向量的快速相似度搜索,支持语义搜索、推荐系统、问答系统等应用。
| 名称 | 类型 | 开源/商用 | 云服务支持 | 说明 |
|---|---|---|---|---|
| FAISS | 向量检索引擎 | 开源 | 否 | Meta开源的高性能向量检索库,专注于高效ANN搜索,适合嵌入式和本地部署。 |
| Chroma | 向量数据库 | 开源 | 有 | 开源向量数据库,支持本地和云端部署,适合构建语义搜索和知识库。 |
| Pinecone | 向量数据库 | 商用 | 有 | 专业的云端向量数据库服务,提供高可用、高扩展的向量检索解决方案,免运维。 |
| Milvus | 向量数据库 | 开源 | 有 | 高性能开源向量数据库,支持大规模向量存储和检索,广泛应用于AI和大数据领域。 |
| Weaviate | 向量数据库 | 开源 | 有 | 支持多模态数据的开源向量数据库,内置丰富的机器学习和知识图谱功能。 |
| Qdrant | 向量数据库 | 开源 | 有 | 现代化开源向量数据库,注重实时性和可扩展性,支持复杂过滤和分布式部署。 |
| PGVector | 向量检索引擎插件 | 开源 | 依赖Postgres | Postgres数据库的向量检索扩展,方便在关系型数据库中集成向量搜索功能。 |
| RediSearch | 向量检索引擎插件 | 开源 | 依赖Redis | Redis的全文搜索和向量检索模块,适合低延迟场景和实时数据处理。 |
| ElasticSearch | 搜索引擎(支持向量检索) | 开源 | 有 | 传统全文搜索引擎,新增向量检索功能,适合结合文本搜索和向量搜索的混合场景。 |
🥒它们的共同作用:
- 存储Embedding向量:将文本或其他数据通过Embedding模型转换成的高维向量存储起来。
- 构建索引:利用高效的索引结构(如HNSW、IVF、PQ等)加速向量的近似最近邻搜索。
- 快速检索:支持基于距离(如欧氏距离、余弦相似度)的快速相似向量查询。
- 扩展性与高可用性:部分支持分布式部署和云端服务,满足大规模应用需求。