NLP学习开始-02逻辑回归
逻辑回归
- 什么是逻辑回归
- 逻辑回归的应用场景
- 逻辑回归几个重要概念
- Sigmoid 函数
- 损失函数
- 构建逻辑回归模型的步骤
- 举个例子
- 参数解释
- 模型优化
什么是逻辑回归
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计学习方法,尽管名字中带有"回归",但它实际上是一种用于二分类或多分类问题的算法。
逻辑回归通过使用逻辑函数(也称为 Sigmoid 函数)将线性回归的输出映射到 0 和 1 之间,从而预测某个事件发生的概率。
逻辑回归的应用场景
信用评分:预测贷款申请人的违约风险。
医疗诊断:根据病人的症状预测疾病的可能性。
市场营销:预测用户是否会点击广告或购买产品
垃圾邮件检测(是垃圾邮件/不是垃圾邮件)
疾病预测(患病/不患病)
客户流失预测(流失/不流失)
逻辑回归几个重要概念
Sigmoid 函数
σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
一个简单的图形表示,sigmoid函数将输出映射到了0和1之间,从而预测某个事件发生的概率
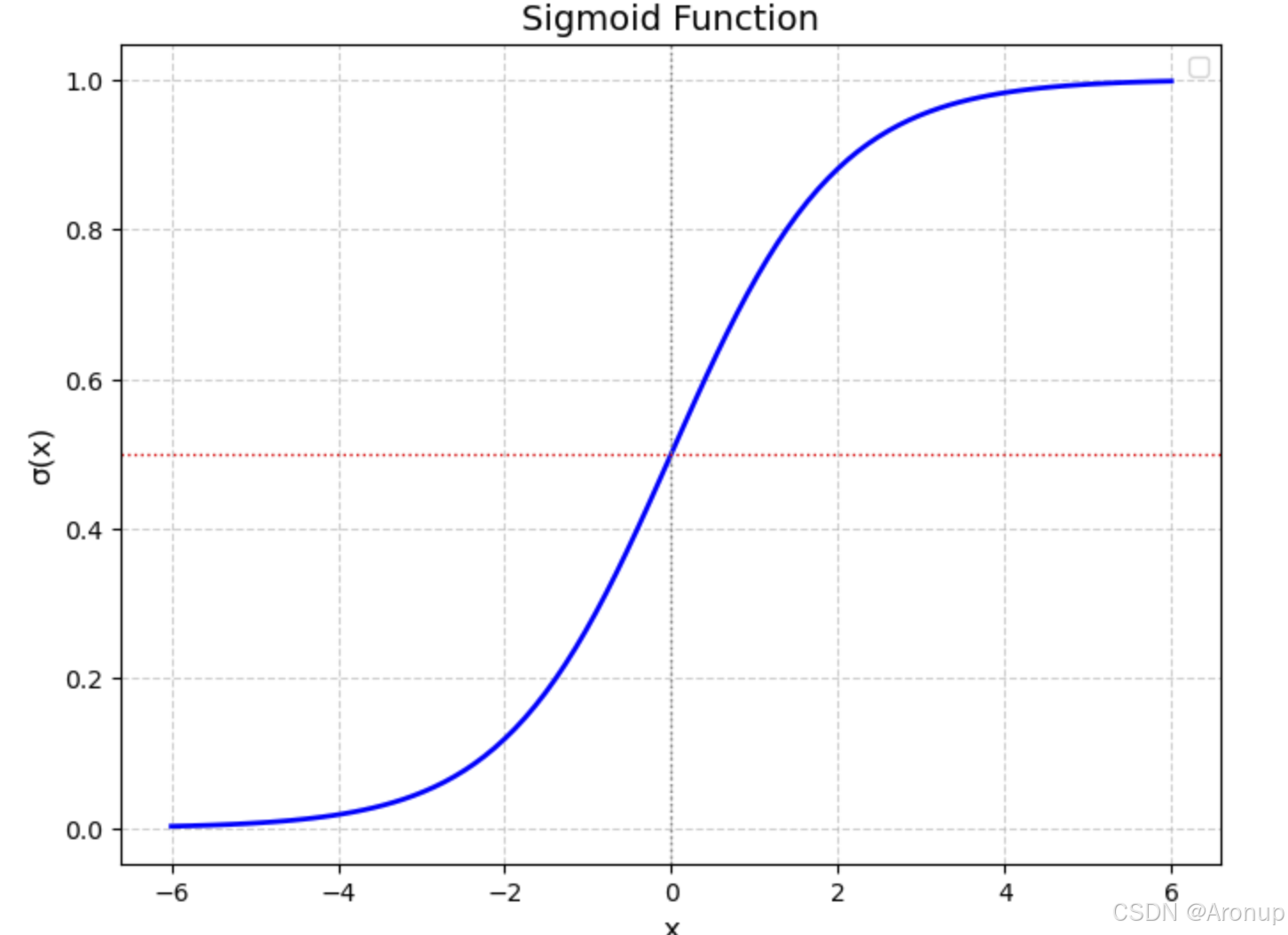
损失函数
是机器学习中用于量化模型预测结果与真实标签之间差异的数学工具。其核心目标是为模型优化提供一个可计算的目标,通过最小化损失函数,模型能逐步调整参数以逼近真实数据分布
逻辑回归常用的损失函数是对数损失,又叫交叉熵损失函数,来衡量模型预测的效果。
对于每个样本,它的损失可以表示为:
L(θ)=−[yilog(y^i)+(1−yi)log(1−y^i)]L(\theta) = -[y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i) ] L(θ)=−[yilog(y^i)+(1−yi)log(1−y^i)]
对整个训练集的损失是对所有样本损失的平均:
L(θ)=−1N∑i=1N[yilog(y^i)+(1−yi)log(1−y^i)]L(\theta) = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i) \right] L(θ)=−N1i=1∑N[yilog(y^i)+(1−yi)log(1−y^i)]
其中 N 是训练样本的数量,yi 是真实标签,y^i 是预测概率值
下面是一个简单的图形,p是预测的概率,图表直观地展示了当真实标签固定时,损失如何随着预测概率的变化而变化
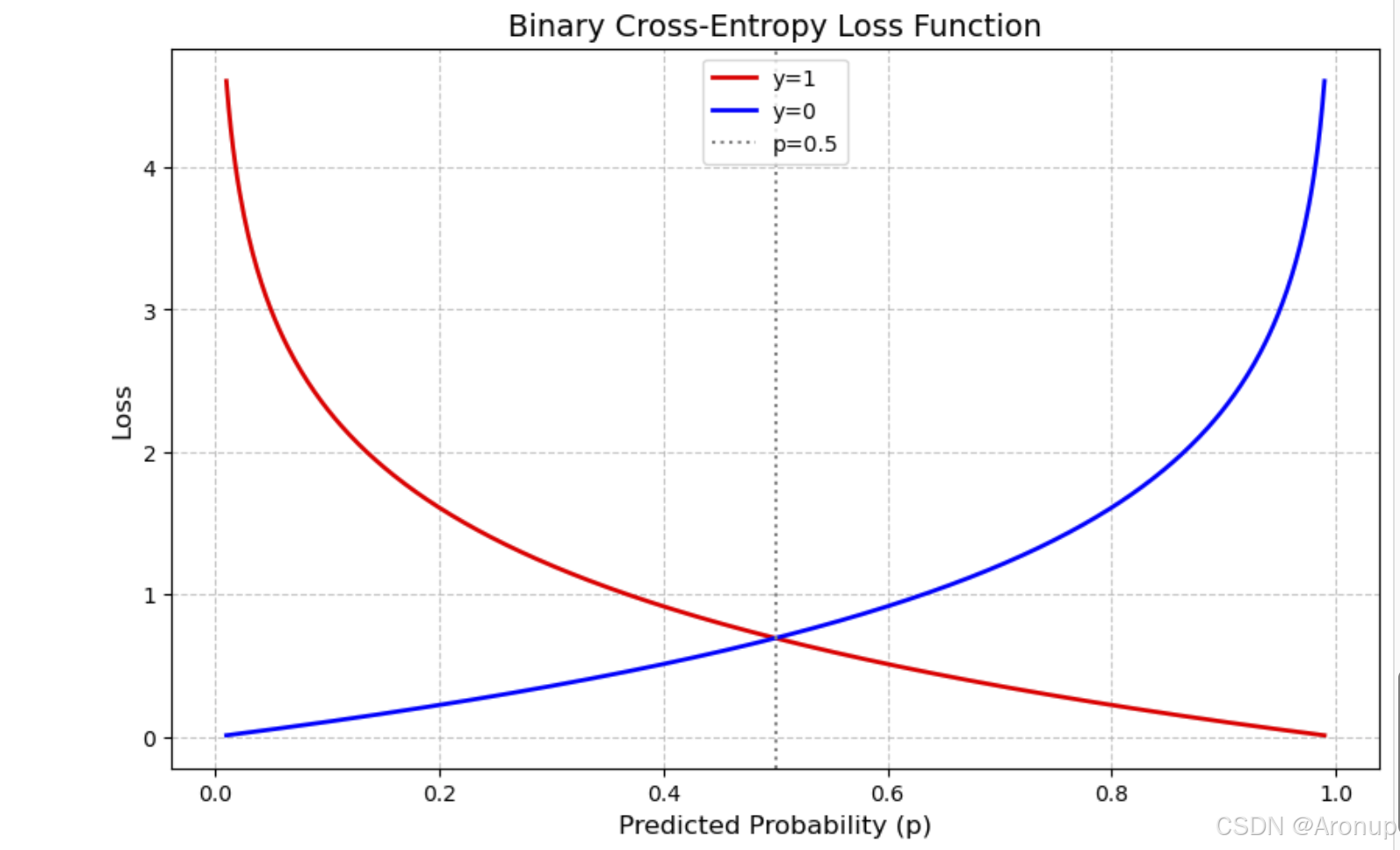
横轴(Predicted Probability, p):表示模型预测的概率为正类(通常标记为1)的概率值,范围从0到1。
纵轴(Loss):表示对应的损失值,反映了预测概率与真实标签之间的差异程度。
曲线:
红色曲线(y=1):当真实标签为1时,损失随预测概率的变化。当预测概率接近0时,损失非常大,因为模型严重错误地预测了负类。当预测概率接近1时,损失接近0,因为模型正确预测了正类。
蓝色曲线(y=0):当真实标签为0时,损失随预测概率的变化。当预测概率接近1时,损失非常大,因为模型严重错误地预测了正类。当预测概率接近0时,损失接近0,因为模型正确预测了负类。
虚线(p=0.5):表示预测概率为0.5的位置,此时模型对正负类的预测不确定。
构建逻辑回归模型的步骤
1.数据EDA
2.特征工程
3.模型构建与训练
4.模型评估与调优
5.模型解释与部署
举个例子
课题:Binary Classification with a Bank Dataset
#逻辑回归
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression# 数据
test = pd.read_csv("../data/BankDataset/test.csv") # 验证集
train = pd.read_csv("../data/BankDataset/train.csv") # 训练集
# 合并测试集和训练集
test['type'] = 'test'
train['type'] = 'train'
all_data = pd.concat([test,train])
all_columns = all_data.columns.tolist()
数据EDA
print(all_columns)
"""
id → ID(标识符/唯一编号)
age → 年龄
job → 职业
marital → 婚姻状况
education → 教育程度
default → 是否有违约记录(通常指信贷违约,如“是否拖欠债务”)
balance → 账户余额
housing → 是否有住房贷款(或“住房贷款状态”)
loan → 是否有个人贷款(或“贷款状态”)
contact → 联系方式(或“沟通渠道”,如电话、邮件等)
day → 日期(日)(当月中的第几天)
month → 月份
duration → 通话时长(单位:秒,常见于电话营销场景)
campaign → 营销活动次数(客户被联系的次数)
pdays → 上次联系间隔天数(距离上次联系的间隔天数,999表示未联系过)
previous → 之前营销活动次数(客户在本次活动前参与的营销次数)
poutcome → 之前营销结果(如“成功”“失败”“未响应”等)
y → 目标变量(通常为二分类标签,如“是否购买产品”“是否响应营销”)
"""#查看列类型
print("train",all_data.dtypes)
# 缺失值查看
missing_report = pd.DataFrame({'Missing_Count': all_data[all_columns].isnull().sum(),'Missing_Ratio': (all_data[all_columns].isnull().sum() / len(all_data[all_columns])).round(4),'Valid_Count': all_data[all_columns].count(),'Valid_Ratio': (all_data[all_columns].count() / len(all_data[all_columns])).round(4)
})
print(missing_report)# 获取文本列和数值列
numeric_cols = all_data.select_dtypes(include=['number']).columns.tolist()
non_numeric_cols = all_data.select_dtypes(exclude=['number']).columns.tolist()
# 查看文本特征列的值
for col in non_numeric_cols:print(col)print(all_data[col].unique())

对于一些有顺序性的特征进行有序编码
# 对于一些有顺序性的特征进行有序编码
poutcome_map = {'failure':0,'unknown':1,'other':2,'success':3,None:1} #使用顺序编码,从失败~成功
default_map={'no':0,'yes':1,None:-1} #
housing_map={'no':0,'yes':1,None:-1} #
loan_map={'no':0,'yes':1,None:-1} #
education_map = {'primary': 1,'secondary': 2,'tertiary': 3,'unknown': 0
}
order_columns=['poutcome','default','housing','loan','education']
all_data["poutcome_encode"]=all_data['poutcome'].map(poutcome_map)
all_data["default_encode"]=all_data['default'].map(default_map)
all_data["housing_encode"]=all_data['housing'].map(housing_map)
all_data["loan_encode"]=all_data['loan'].map(loan_map)
all_data["education_encode"]=all_data['education'].map(education_map)
#删除转换的列
all_data.drop(order_columns,axis=1, inplace=True)
对没有顺序性的列进行独热编码
# 对月份进行标签编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
all_data['month_encoded'] = le.fit_transform(all_data['month'])
# 对职业进行独热编码编码
job_dummies = pd.get_dummies(all_data['job'], prefix='job')
job_dummies = job_dummies.astype(int) # 转换为0/1
# 对婚姻状况进行独热编码
marital_dummies = pd.get_dummies(all_data['marital'], prefix='marital')
marital_dummies = marital_dummies.astype(int) # 转换为0/1
# 对联系方式进行独热编码
contact_dummies = pd.get_dummies(all_data['contact'], prefix='contact')
contact_dummies = marital_dummies.astype(int) # 转换为0/1
构建新的数据集
# 合并为新的数据集
finall_data=pd.concat([all_data,job_dummies,marital_dummies,contact_dummies],axis=1)
encode_col=['job','marital','contact','month']
finall_data.drop(encode_col,axis=1, inplace=True)
new_train = finall_data[finall_data['type']=='train'].copy()
new_test = finall_data[finall_data['type']=='test'].copy()
new_train.drop(['type'],axis=1, inplace=True)
new_test.drop(['type'],axis=1, inplace=True)
Y_train = new_train['y']
new_train.drop(['y','id'],axis=1, inplace=True)
new_test.drop(['y','id'],axis=1, inplace=True)
构建模型
# 创建模型
from sklearn.linear_model import LogisticRegression
# 创建模型(可调整参数)
model = LogisticRegression(penalty='l2', # 正则化类型(L1/L2)C=1.0, # 正则化强度(越小正则化越强)solver='lbfgs', # 优化算法('lbfgs', 'liblinear', 'saga')max_iter=1000, # 最大迭代次数random_state=42
)
#训练模型
model.fit(new_train,Y_train)
使用模型
y_pred = model.predict(new_test)
submission_df = pd.DataFrame(data={'id': test['id'], 'y': y_pred})
submission_df.to_csv('output.csv', index=False)
参数解释
penalty(正则化类型)
作用:指定正则化类型,用于防止过拟合。
可选值: ‘l2’(默认):L2 正则化(权重衰减),对大权重施加惩罚,使参数更平滑。 ‘l1’:L1 正则化,倾向于产生稀疏解(部分参数为零,适用于特征选择)。 ‘elasticnet’:L1 和 L2 的组合(需额外设置 l1_ratio 参数)。 None:无正则化(不推荐,易过拟合)。
调整建议: 如果特征较多,尝试 ‘l1’ 进行特征选择。 默认 ‘l2’ 通常表现稳定
== C(正则化强度)==
作用:控制正则化的强度,与模型复杂度负相关。
取值: 必须为正浮点数(如 C=0.1, C=1.0, C=10)。
越小:正则化越强,模型更简单(可能欠拟合)。
越大:正则化越弱,模型更复杂(可能过拟合)。
调整建议: 通过交叉验证(如 GridSearchCV)搜索最优值(例如 C=[0.01, 0.1, 1, 10])。 默认值 C=1.0 适合多数场景。
solver(优化算法)
作用:指定损失函数的优化算法,不同算法对参数的支持和效率不同。 可选值:
‘lbfgs’(默认):拟牛顿法,适合中小型数据集,支持 ‘l2’ 和 ‘none’。
‘liblinear’:坐标下降法,适合小型数据集,支持 ‘l1’ 和 ‘l2’。
‘saga’:随机梯度下降,适合大数据集,支持 ‘l1’、‘l2’ 和’elasticnet’。
‘newton-cg’:牛顿法,支持 ‘l2’ 和 ‘none’。
‘sag’:随机平均梯度下降,适合大数据集,仅支持 ‘l2’。
调整建议: 数据量小:‘liblinear’ 或 ‘lbfgs’。 数据量大:‘saga’ 或 ‘sag’。 需要 L1 正则化:选择 ‘liblinear’ 或 ‘saga’。
max_iter(最大迭代次数)
作用:控制优化算法的最大迭代次数,确保算法收敛。
默认值:100(可能不足,尤其是复杂数据)。
调整建议: 如果收敛警告(ConvergenceWarning),增加此值(如 max_iter=1000)。 对于大型模型或高维数据,可能需要更大值(如 5000)。
random_state(随机种子)
作用:控制随机数生成,确保结果可复现。
适用场景: 当 solver=‘lbfgs’、‘sag’ 或 ‘saga’ 时,影响权重初始化。在交叉验证或数据洗牌时固定随机性。
调整建议: 固定为整数(如 42)以保证结果一致性。
模型优化
努力码字中…
