Graph-R1:一种用于结构化多轮推理的智能图谱检索框架,并结合端到端强化学习
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

大型语言模型(Large Language Models, LLMs)在自然语言处理领域设立了新的基准,但它们在知识密集型应用中仍存在“幻觉”问题——即生成不准确内容。检索增强生成(Retrieval-Augmented Generation, RAG)框架试图通过引入外部知识来解决这一问题。然而,传统RAG依赖基于文本切块(chunk-based)的检索方式,难以表示复杂的语义关系。基于实体关系图的RAG方法(GraphRAG)在一定程度上改善了结构问题,但依然面临高构建成本、一次性检索不灵活、依赖长上下文推理及对提示词设计的敏感性等问题。
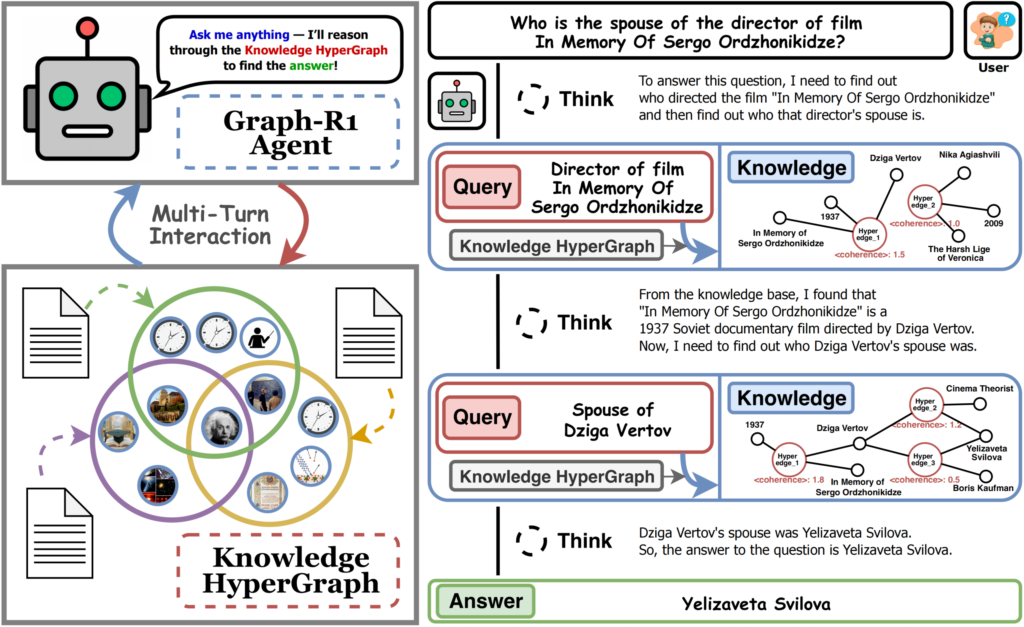
来自南洋理工大学、新加坡国立大学、北京计算机技术与应用研究所和北京安贞医院的研究人员提出了Graph-R1——一种由端到端强化学习驱动的智能型GraphRAG框架。
核心创新
- 轻量级知识超图构建
Graph-R1将知识构建为超图(hypergraph),每个知识片段通过LLM驱动的n元关系抽取得到。这种方法能编码更丰富、语义更扎实的关系,在保持低成本与可控计算需求的同时增强智能推理能力。
- 效率:在构建阶段,每1000个token耗时5.69秒、成本2.81美元(相比之下,GraphRAG为3.35美元,HyperGraphRAG为4.14美元)。即便如此,生成的超图仍包含120,499个节点和98,073条边,语义信息丰富。
- 多轮智能检索过程
Graph-R1将检索建模为多轮交互循环(“思考–检索–再思考–生成”),使智能体能够在推理过程中自适应地查询与调整知识路径,不再局限于一次性检索。
- 动态推理:智能体在每一步都判断是继续探索还是终止并输出答案。实体检索与超边检索通过倒序排名融合,提高获取最相关知识的概率。
- 端到端强化学习优化
Graph-R1采用组相对策略优化(Group Relative Policy Optimization, GRPO)进行端到端强化学习,将格式遵循、相关性和答案正确性整合到统一奖励机制中。这一机制确保推理策略与知识结构和输出质量紧密对齐。
- 结果导向奖励:结合格式奖励(结构连贯性)与答案奖励(语义准确性),仅在推理轨迹结构有效且答案正确时才给予奖励。
关键实验结果
- 在RAG问答任务中的表现
Graph-R1在六个标准问答数据集(2WikiMultiHopQA、HotpotQA、Musique、Natural Questions、PopQA、TriviaQA)上进行评测。
在使用Qwen2.5-7B模型时,Graph-R1平均F1分数达到57.82,显著超越所有已有基线方法(相比之下,GraphRAG为24.87,HyperGraphRAG为29.40,Search-R1为46.19)。更大的基础模型能进一步放大性能提升。 - 消融分析
移除超图构建、多轮推理或强化学习优化模块,都会显著降低性能,证明各模块的必要性。 - 检索与效率
Graph-R1的检索过程更加精简高效。平均每轮内容长度约1200–1500个token,交互轮次平均为2.3–2.5,能稳定准确地提取知识。
- 生成成本极低:平均每次查询响应时间为7.0秒,生成成本为0美元,优于如HyperGraphRAG(9.6秒,8.76美元)等竞争方法。
- 生成质量
在覆盖度、知识性、正确性、相关性、多样性、逻辑连贯性和事实性七个维度上,Graph-R1均优于所有基于强化学习和基于图谱的基线,在正确性(86.9)、相关性(95.2)和连贯性(88.5)等指标上表现最佳。 - 泛化能力
在分布外(Out-of-Distribution, O.O.D.)测试中,Graph-R1的性能与分布内(In-Distribution, I.I.D.)相比保持在85%以上,显示出强大的领域泛化能力。
理论保障
- 基于图结构的知识检索单位信息密度更高,比基于文本切块的方法更快收敛到正确答案。
- 多轮交互使智能体能够动态聚焦高价值的图谱区域,提高检索效率。
- 端到端强化学习优化连接了图结构证据与语言生成,降低输出熵值与错误率。
高层算法流程
- 知识超图抽取:LLM抽取n元关系以构建实体集与超边集。
- 多轮智能推理:智能体在反思、查询、超图检索(实体路径与超边路径双通道)和综合生成之间循环。
- GRPO优化:利用采样轨迹与奖励归一化更新强化学习策略,确保结构与答案的正确性。
结论
Graph-R1证明,将超图知识表示、多轮智能推理和端到端强化学习结合,可在事实问答性能、检索效率和生成质量方面实现前所未有的提升,为下一代智能型、知识驱动的大型语言模型系统奠定了基础。
常见问题解答
- Graph-R1与早期GraphRAG和RAG系统相比的关键创新是什么?
- 超图知识表示:采用语义超图而非简单实体关系图或文本切块,可表达更丰富的n元实体关系。
- 多轮推理循环:智能体以“思考–检索–再思考–生成”的模式在超图中动态调整查询,而非一次性检索。
- 端到端强化学习:奖励机制同时优化逐步逻辑推理与最终答案正确性,实现结构化知识与自然语言答案的紧密结合。
- Graph-R1在检索和生成效率上如何优于以往方法?
- 构建超图所需时间与成本更低(2Wiki数据集下每1000个token仅需5.69秒、2.81美元)。
- 查询响应更快(平均7秒)且生成成本为零。
- 答案更精简(1200–1500个token)且准确率更高,在六个问答数据集上均取得最优F1分数。
- Graph-R1适用于哪些场景或领域?
- 医疗健康AI:需要多跳推理、可追溯性与高可靠性。
- 法律与监管领域:要求精准且可解释的多步推理答案。
- 企业知识自动化:支持在海量文档与数据集中的动态可扩展检索与生成。
其架构也易于适配其他需要基于结构化表示进行多轮智能检索的领域。