Linux下管道的实现
1.温故知新
在上一篇博客我们知道了动态库是怎么样进行链接的,我们知道我们的.o文件,可执行文件都是我们的ELF格式的文件,是ELF文件,里面就有ELF header,程序头表,节,还有节头表,我们链接器编译的时候需要合并节,节头表告诉编译器怎么合并,当加载进内存的时候又会根据程序头表,程序头表告诉节怎么合并成我们的段,我们ELF header里面有我们程序的入口,但是不和我们想象中的先程序我们的main函数,而是先去执行我们的_start,它里面会为我们实现动态库的地址重定向。我们动态库是程序加载的时候才从磁盘加载到内存里的,然后我们规定我们的代码区是不可以更改的,在数据区创建GOT表来实现我们的地址重定向,为了节省内存,我们动态库函数加载也是采用了延时加载的手段,就是先把函数在虚拟地址开辟好,当你调用的时候发现虚拟地址没有映射物理地址,发生中断,陷入内核,内核帮助我们从磁盘加载要用的库函数建立物理和虚拟的映射关系,实现我们的动态库函数调用,至于静态库,链接的时候就已经完成地址的重定向,直接把我们的库搞到可执行里,不需要再搞这个复杂的一套。
下面,我们介绍一下我们的进程间通信,我们知道进程是具有独立性的,进程之间的任务执行不会相互干扰,但是我们有的时候需要我们进程间通信,为了实现进行间通信我们创建出了管道的概念。下面来详细说明一下。
2.进程间通信
首先我们来说明:进程间通信本质就是让不同的进程看到同一份资源,并且拿到这份资源,但是由于我们的进程独立性,我们要做到这个并不是很容易。
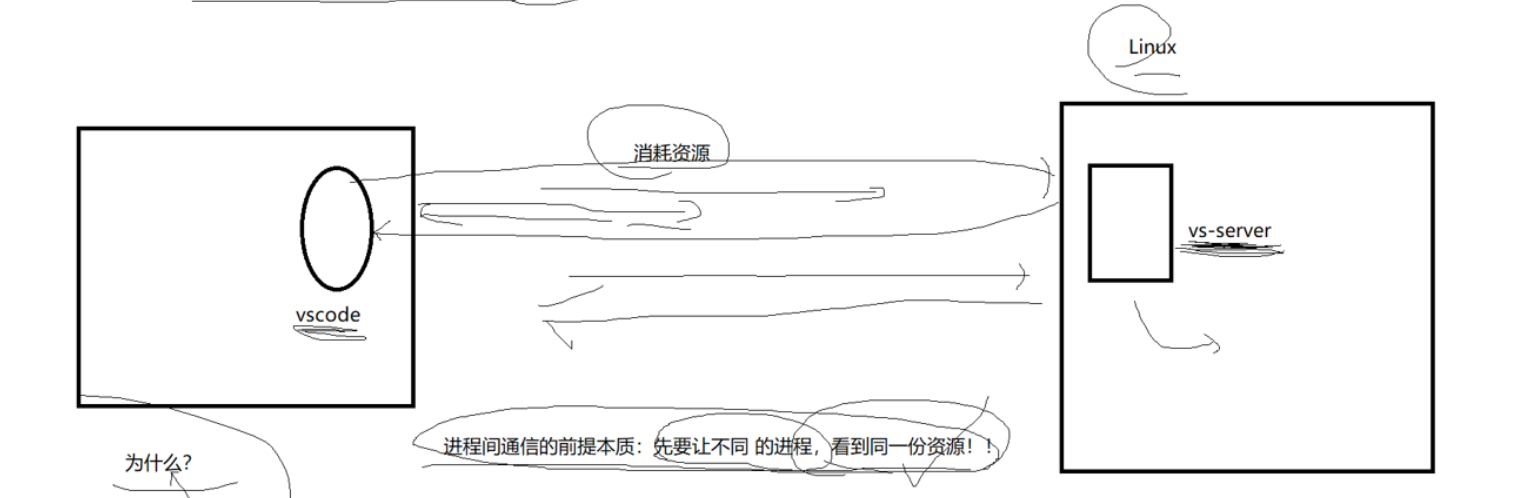
我们进程间通信有很多目的,比如共享资源,比如控制进程等等。
管道是什么呢?管道就是我们进行进程间通信的工具。
管道的定义是:管道是一个基于文件系统的一个内存级的实现进程间单向通信的文件
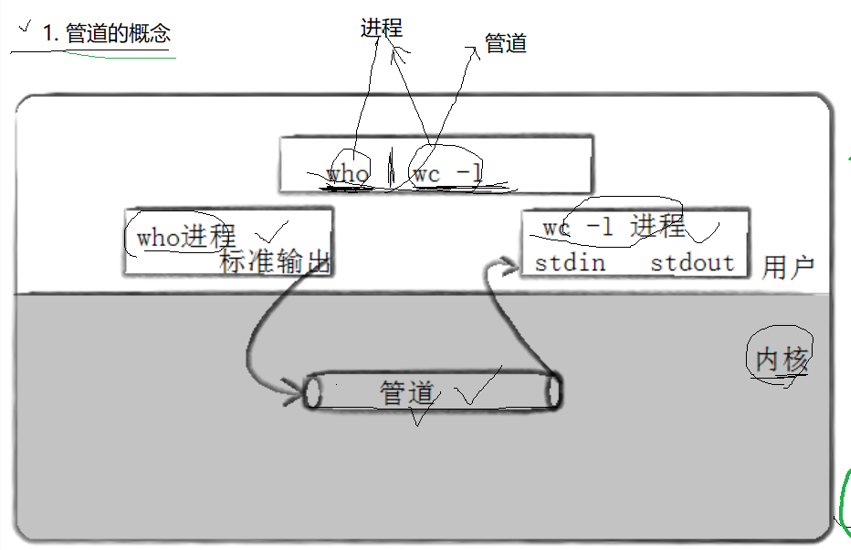
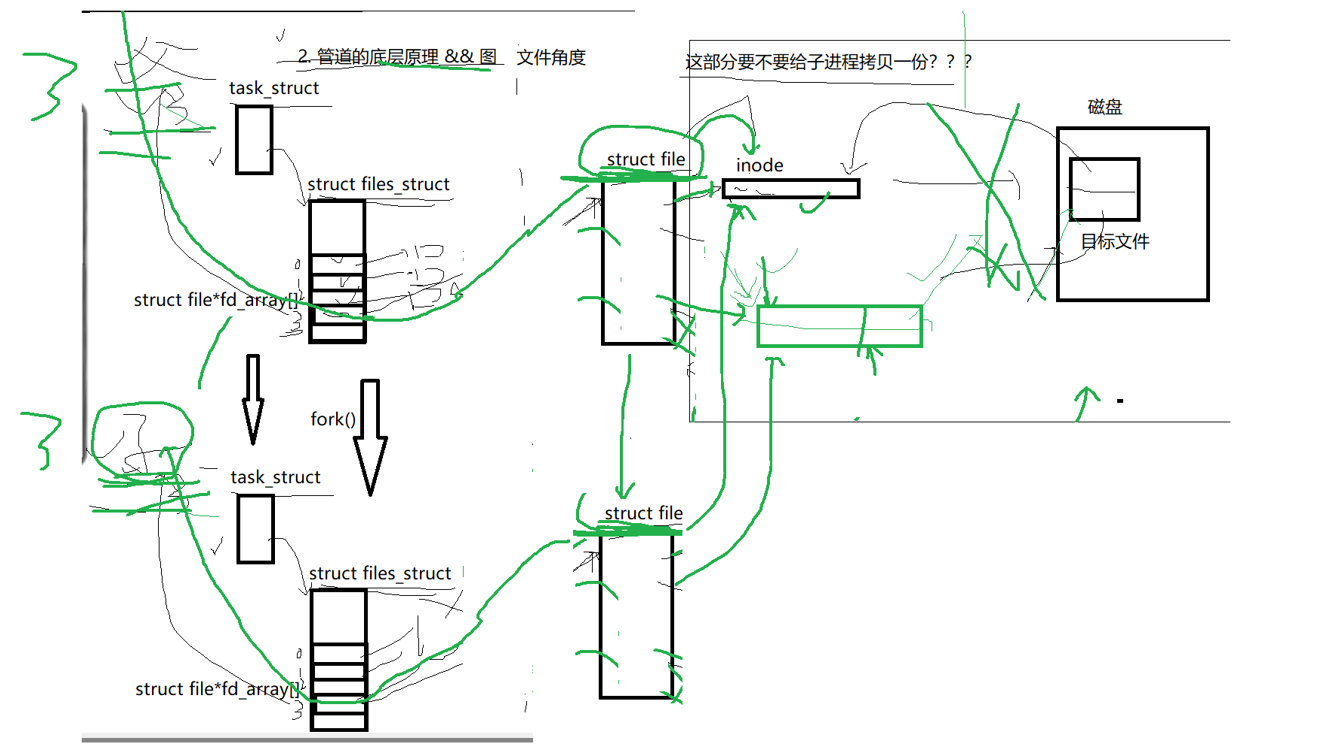
管道的底层原理是:我们知道父进程创建子进程,子进程会把父进程的PCB和struct file自己拷贝一份,所以子进程的也会指向父进程指向的文件,因为这个原因我们父子进程打印都往一个屏幕上打印,因为我们的屏幕文件被共享了,而我们现在父子进程就可以看见同一个文件的文件缓冲区了,文件缓冲区就是一个管道,但是有一个问题是我们上面打开的文件大部分是普通文件,是普通文件就要把文件缓冲区的内容往磁盘里写,但是我们管道创建本质是为了让我们父进程把它的资源交给子进程,不需要往磁盘做IO刷新,而且我们文件的读写位置只有一个,父进程往管道里100个字节,但是子进程读从100开始读,它是读不到数据的,读写共享是不方便我们读取写入的,不方便通信。所以我们的解决方法是如果是管道,我们把我们的管道文件也拷贝一份给子进程,并且这个文件不往磁盘做IO,这样我们就解决了我们的读写位置重叠,和我们的往磁盘写入的问题。
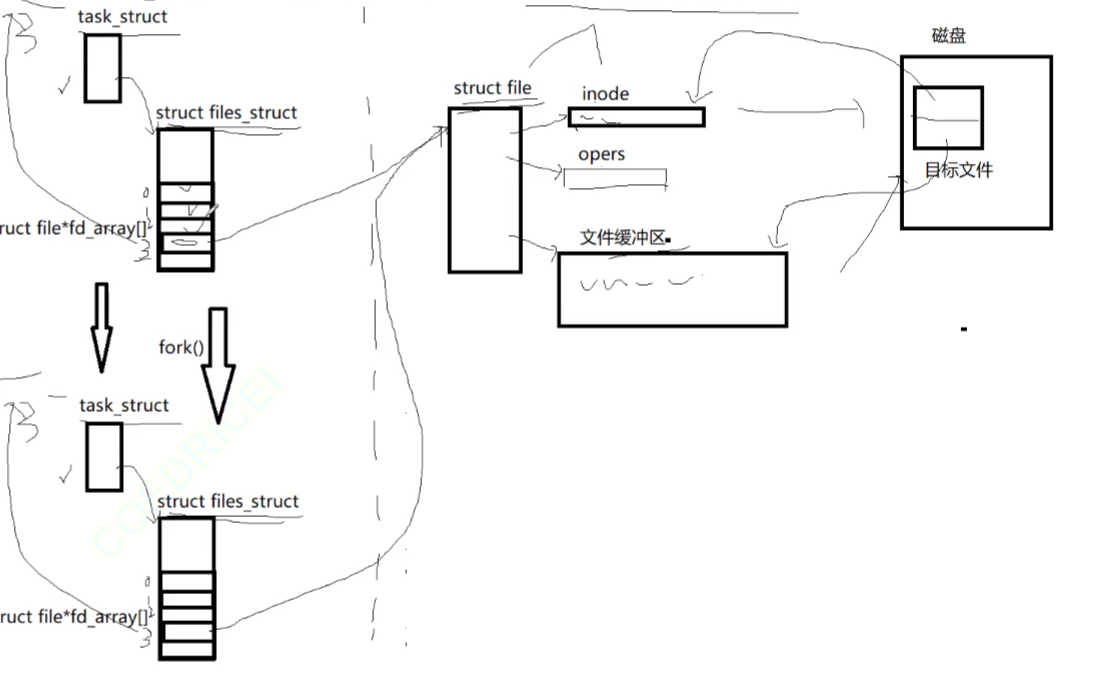
这个图反映了我们的读写位置是一样的问题

管道的原理就是把我们的file原来不需要拷贝,然后我们多拷贝一份,就解决了我们的读写位置一样的问题,它们的pos就不一样了。
但是我们的文件缓冲区,文件inode和文件的操作表都是一样的。
至于怎么做到pos不共享但是缓冲区共享,还是因为我们复制了一份我们的file
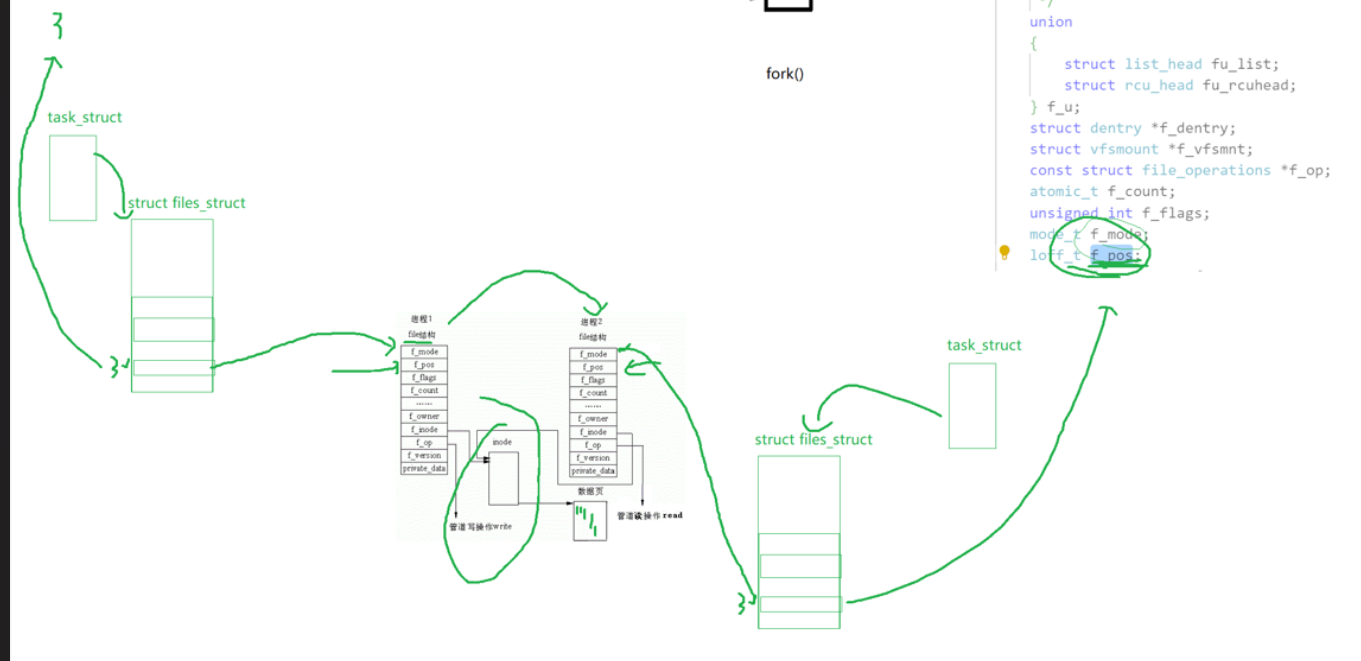
这种文件是不需要打开我们的磁盘文件的,IO磁盘直接被干掉了。
管道的实现是让我们父进程以读写方式打开一个管道,然后子进程会继承,然后父子进程根据需要关闭一个读端和写端,因为我们的管道就是进行单向通信的,天然气管道,暖气管道都是单向的。
所以我们管道也是单向通信即可。
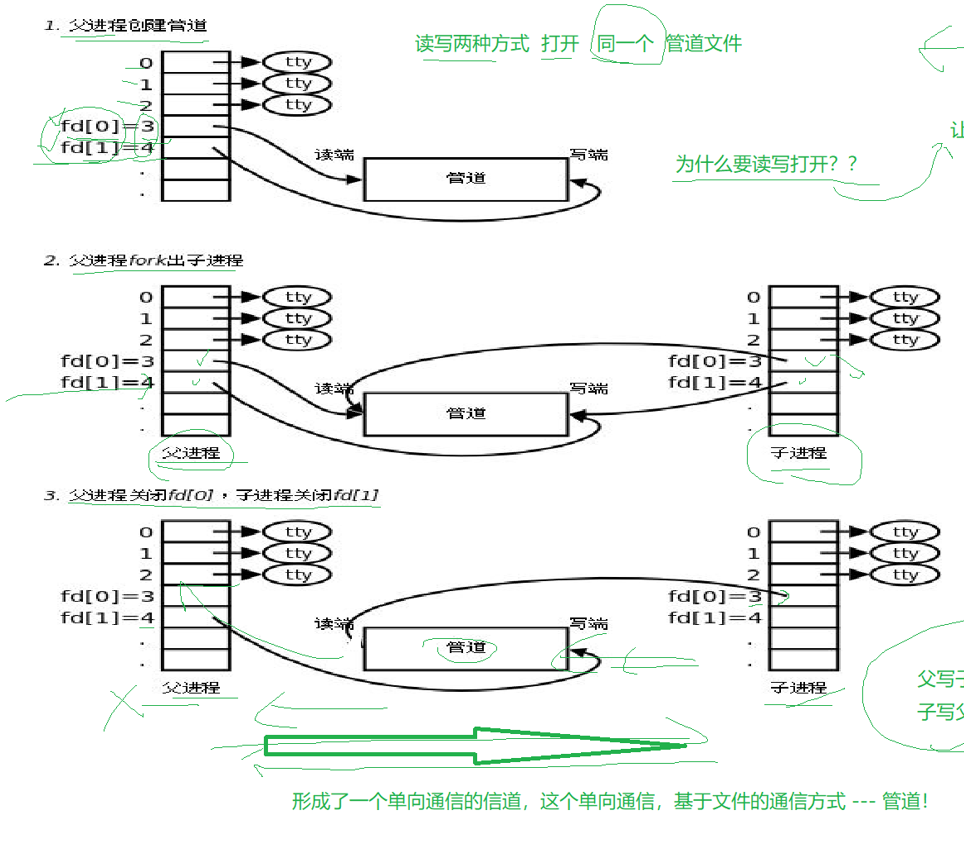
说了这么多,你给我说管道的原理就是让我们不同的进程看到同一个资源,这个管道不和磁盘进行IO,子进程继承的时候会拷贝一份file实现我们的pos的读写分离。那么我们怎么在我们的语言中使用管道进行进程间通信?
下面我们进行实现一下,首先我们的调用是pipe,参数是piprfd,这个是我们的输出型参数。
/ 父进程先创建管道,让子进程去复制int pipefd[2] = {0};int n = pipe(pipefd);
创建好读写管道之后让我们的父子进程关闭对应的管道就可以进行进程间通信了。
然后我们再来介绍一下管道的特性:匿名管道用于具有血缘关系的进程之间。它是单向通信的,这个好理解,我们想一下生活中的管道基本都是单向通信的,还有是管道的生命周期随进程,这个也好理解,管道本质也是一个文件,只不过它是为了通信而创立的,进程没了,也就不需要通信了,它自然就没了,操作系统不会让废弃的管道占用资源,管道也自带同步机制,比如我们的管道里如果没有东西了,read会阻塞,如果我们管道被写满了数据,就不会再进行写入了,如果我们的写端关闭,我们的read会返回0,表示读到文件结尾了,如果读端关闭,写端正常,我们的操作系统会杀掉进程,因为我们的读端不读数据,你再往管道里面写数据就没有意义了。
我们再来提一个原子性的概念,我们学过化学,知道最小的就是原子构成的,所以原子在我们的计算机中说人话就是这个操作不可以被打断,很多人还是不怎么理解,我们打个比方,我们的a++,这操作其实要分很多步骤去完成,我先得吧我们的a从内存搞到CPU,然后CPU对a再进行加法操作,然后再把我们的结果写回到我们的内存,才完成了一次++,所以它的++动作就不是原子性的了,它是可以被打断的,比如刚把我们的a加载到内存准备++,这个时候我们的线程被切走了,不就没完成动作了吗?然而我们的原子性就是一下就完成,不可以被打断的,就是原子性操作。
而我们的管道当写入字节少于一定大小的话,写入就是原子性的。
通过我们管道的这些特性比如我们的阻塞特性,管道没数据,读端会阻塞,管道写满了就不会再写入了,我们可以让父进程来控制它的子进程。
我们父进程可以用什么时候写入数据来控制子进程来执行自己的任务,我父进程不往里面写,你就读不到数据,你读不到数据,你就会阻塞在那里。
还有就是我们父进程和子进程规定,写入4字节整数,整数不同,表示的任务不同。
我们可以采用轮询或者随机数的形式给不同的子进程进行写入,避免有的进程很忙,有的进程很闲。不准偷懒!!!
#include <sys/types.h>
#include <unistd.h>
#include <unistd.h>
#include <unistd.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
#include <cstdio>
#include <string>
#include <vector>
#include"Task.hpp"
#include <string>
#include <vector>
#include <functional>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <ctime>
#include "Task.hpp"
// typedef std::function<void (int fd)> func_t;
using callback_t = std::function<void(int fd)>;//返回值,参数
class channel
{
public:channel(int wfd, string name, pid_t id): _wfd(wfd), _name(name), _id(id){}~channel(){}int Fd() { return _wfd; }std::string Name() { return _name; }pid_t Target() { return _id; }void Close() { close(_wfd); }void Wait(){pid_t rid = waitpid(_id, nullptr, 0);}
private:int _wfd; // 父进程写入的文件描述符pid_t _id; // 子进程的idstring _name; // 子进程的名字
};class processpool
{
public:processpool(int num) : _num(num){}~processpool(){}bool initpocesspool(callback_t cb){for (int i = 0; i < _num; i++){// 父进程先创建管道,让子进程去复制int pipefd[2] = {0};int n = pipe(pipefd);pid_t id = fork();if (id < 0)return false;if (id == 0) // 这个函数逻辑只有子进程进来,父进程不进来{// 子进程// 要读取,关闭写入close(pipefd[1]);// 子进程要干什么事情啊cb(pipefd[0]);exit(0);}else{// 父进程完成对子进程的描述+组织// 父进程// 要写入,关闭读取close(pipefd[0]);string name = "channel-" + to_string(i);_channels.emplace_back(pipefd[1], name, id);}}return true;}// 轮询控制子进程void processcontrol(){int count=5;int index = 0;while (count--){// 1. 选择一个通道(进程)int who = index;index++;index %= _channels.size();// 2. 选择一个任务,随机int x = index % tasks.size(); // [0, 3]// 3. 任务推送给子进程write(_channels[who].Fd(), &x, sizeof(x));//往哪个文件里写,写的内容的地址,写的内容大小//当任务被写入的时候,子进程要去读sleep(1);}}void WaitSubProcesses(){for(auto e:_channels){e.Close();}for(auto e:_channels){e.Wait();}}
private:int _num; // 有多少个子进程vector<channel> _channels; // 将子进程塞进vector,用channel描述,_chanells组织,先描述,再组织
};
#pragma once#include <iostream>
#include <string>
#include <vector>
#include <functional>
// 4种任务
// task_t[4];using task_t = std::function<void()>;void Download()
{std::cout << "我是一个downlowd任务" << std::endl;
}void MySql()
{std::cout << "我是一个 MySQL 任务" << std::endl;
}void Sync()
{std::cout << "我是一个数据刷新同步的任务" << std::endl;
}void Log()
{std::cout << "我是一个日志保存任务" << std::endl;
}std::vector<task_t> tasks;class Init
{
public:Init()//构造函数的初始化666{tasks.push_back(Download);tasks.push_back(MySql);tasks.push_back(Sync);tasks.push_back(Log);}
};Init ginit;//当实例化出对象的时候这个4个任务的插入将同步完成!!!利用了实例化的特性
#include <unistd.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
#include <cstdio>
#include <string>
#include <vector>
#include "processpool.hpp"
int main()
{// 1.chuangjian processpoolprocesspool pp(5);// 2.进行初始化pp.initpocesspool([](int fd){while(true){//这个逻辑只有子进程能进来父进程往下一步走了int code = 0;//std::cout << "子进程阻塞: " << getpid() << std::endl;ssize_t n = read(fd, &code, sizeof(code)); // 阻塞读取// 确保读取到完整数据std::cout << "子进程被唤醒: " << getpid() << std::endl;tasks[code]();
// } else if (n == 0) {
// break; // 父进程关闭管道,子进程退出
// } else {
// perror("read");
// break;
// }if(n == 0){//父进程std::cout << "子进程应该退出了: " << getpid() << std::endl;break;}else{std::cerr << "read fd: " << fd << ", error" << std::endl;break;}}
});//3.进行进程池的控制,控制权在父进程手里pp.processcontrol();// 4. 结束线程池pp.WaitSubProcesses();std::cout << "父进程控制子进程完成,父进程结束" << std::endl;// //创建指定的子进程数// for(int i=0;i<count;i++)// {// //创建管道// int pipefd[2]={0};// int n=pipe(pipefd);// //2.创建子进程// pid_t id=fork();// if(id==0)// {// //子进程// close(pipefd[1]);//子进程关闭写端// exit(0);// }// else// {// close(pipefd[0]);//父进程关闭读端// }// }return 0;
}还有就是我们是否注意过我们的子进程什么时候会退出,是我们的父进程的写端关闭,根据我们的管道特性,写端关闭我们的读端读到0就退出了,但是这个时候我们会有个bug,你看我们父进程创立了一个子进程,它搞了一个读管道,当我们第一次创建进程,它是对的,父进程关闭了它的读端,子进程关闭了它的写端,但是第二次就不太对了,你看我创建子进程子进程会拷贝我的文件描述符表一份,它也会把我第一次创建的指向第一次创建子进程写端的文件也会拷贝过去,这就导致我们关闭写端的时候没有关闭完全,子进程无法读到0,它也无法退出,进程卡bug了,所以我们需要在创建我们子进程的时候顺便把我们上次的写端关掉就好了。
怎么拿到父进程上次的写端,从我们的channel里拿就好了,我们每次创建子进程的时候都遍历一遍我们的_channels就好了,里面就有我们的父进程的写端,让子进程关闭了就好了。
for(auto &e:_channels)close(e.Fd());