强化学习全流程开发:从环境搭建到智能体对弈的DQN与Actor-Critic实现
强化学习是构建AI决策系统的核心方法,近年来DQN、Actor-Critic等算法通过价值函数优化与策略梯度提升,持续推动智能体在确定性环境中的博弈能力突破。
本期推荐的是和鲸社区创作者分享的一个实战项目,完整展示了多种强化学习策略在黑白棋环境中的训练过程与对弈效果,为学习者提供兼具操作性和启发性的参考范式。
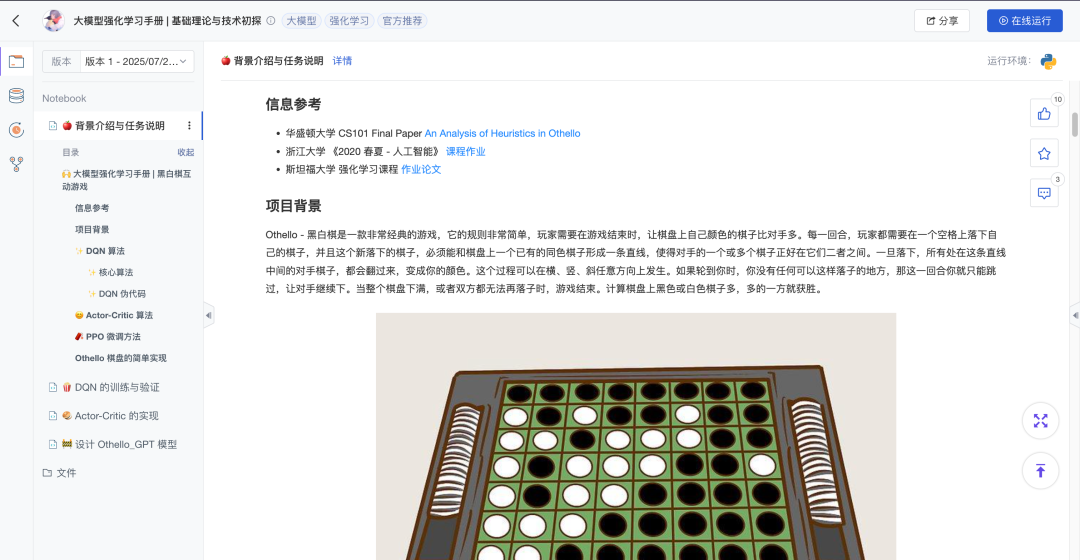
项目信息
项目名称:大模型强化学习手册|基础理论与技术初探
项目简介:这是和鲸社区创作者 @那路 分享的强化学习实战项目,围绕黑白棋(Othello)实现从环境搭建到智能体对弈的全流程。项目已完成DQN和Actor-Critic两大算法的完整实现,并提出轻量化Othello-GPT的未来构想。通过IPywidgets构建可视化界面,支持人机对战与AI自博弈演示。
作者主页:https://www.heywhale.com/u/a4d26d
项目地址:https://www.heywhale.com/u/790d5e
推荐理由
项目构建了统一的黑白棋博弈环境,已实现DQN与Actor-Critic两种算法训练,并保留策略接口便于未来扩展。本项目具备以下推荐价值:
双算法对比:完整实现DQN(含经验回放)与Actor-Critic(策略-价值双网络)
闭环训练系统:覆盖状态编码→模型训练→胜率评估→交互部署全流程
工程化设计:模块化接口便于扩展,可视化界面即时反馈决策过程
项目亮点详览
1、多种强化学习策略实现:
实现了经典的DQN算法,构建完整的状态空间更新、Replay Buffer与epsilon-greedy策略;引入了Actor-Critic结构探索策略梯度优化路径。项目同时探讨了轻量化Othello-GPT的设计思路,为未来融合语言模型与强化学习预留研究方向。
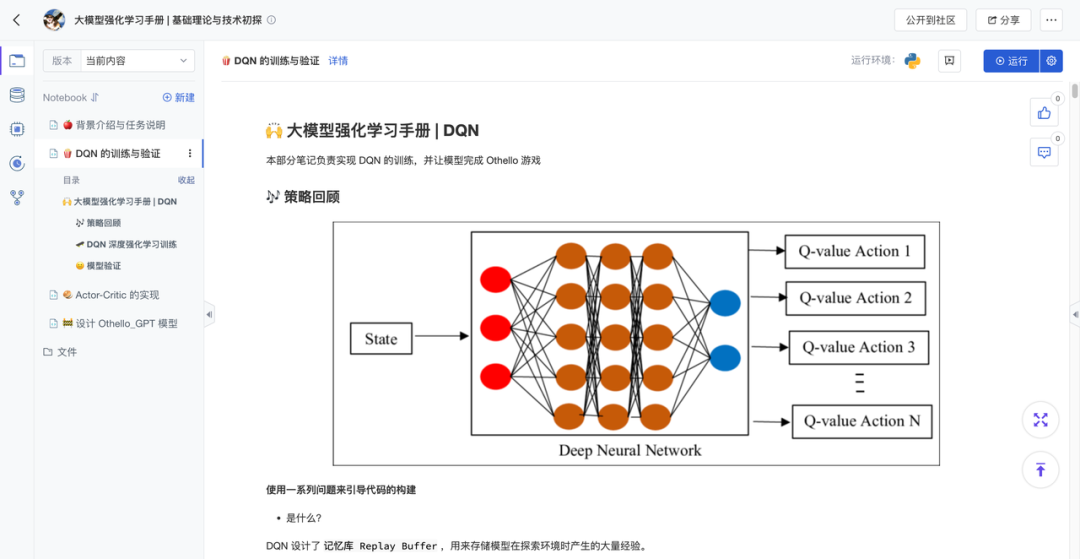

2、统一环境+UI的训练与交互系统
本项目使用Python原生构建Othello游戏逻辑,完整实现落子合法性验证、实时得分统计与终局胜负判定,并可通过标准接口连接训练模块,形成训练-交互-部署的强化学习闭环。作者基于ipywidgets开发了可视化棋盘界面,支持:
双模式切换:人机对战/AI自博弈演示(DQNvs随机)
动态执棋选择:自由切换黑白棋先手
实时状态提示:合法落子点标记、回合提醒、胜率分析

3、预留模型集成空间,支持自定义策略
项目在核心逻辑中提供AI策略调用接口(如get_ai_move()),当前支持Actor-Critic与随机算法的切换。开发者可通过修改该函数接入自定义模型,便于进行算法对比与策略调试等扩展实验。
如果你正想找一个能跑、能学、能改的强化学习实战项目,不妨fork下来试试