深度学习·MAFT
MAFT
- two stage zero shot 语义分割的改进方法
*两阶段zero shot方法回顾
- 一个提议器生成提议区域,与原图像叠加起来。然后输入到CLIP的图像encoder部分,得到class token,与每一个文本类别的class token进行相似度计算,取最高值。

动机
+ 实验:对不同的提议,冻结的CLIP会产生相似的预测结果

方法
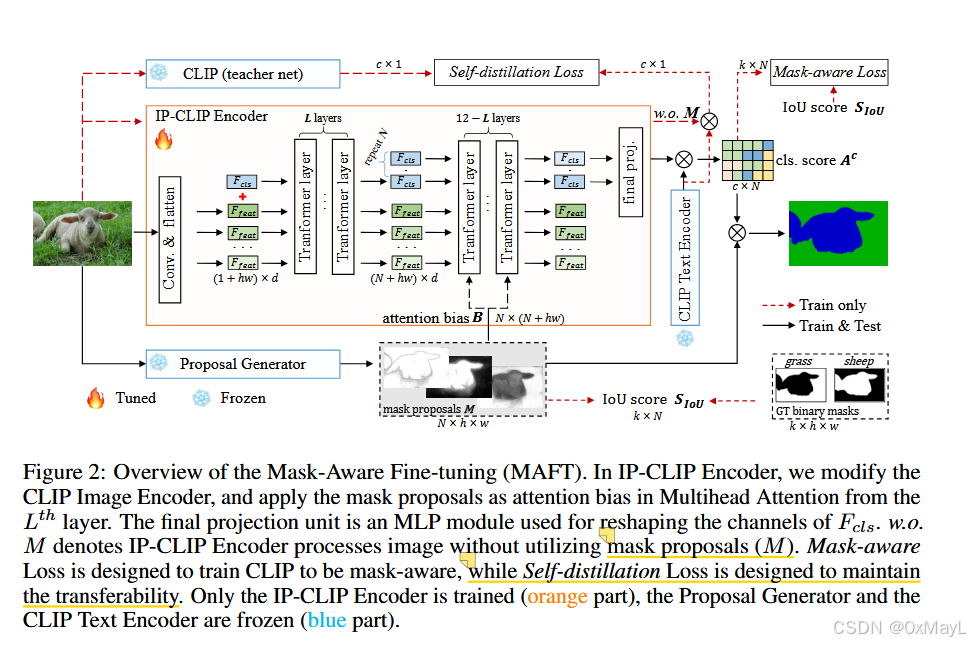
IP-CLIP encoder
动机
IP-CLIP Encoder aims to process arbitrary numbers of images and mask proposals simultaneously.
效率上:为每个图片叠加提议生成多个子图像,并使用子图像分类效率低下,本文提出了一种同时处理多个提议的方法。
性能上:子图像之外的区域都为0,导致损失了全局信息。所以也要考虑使用提议时,保留原本的全局信息
设计
- 前L层正常的注意力机制,与CLIP完全一致(1+hw,d),保留全局特征
- 后12-L层,class token复制N遍,设计一个注意力掩码,N个class token与对应的提议区域进行注意力操作,保留局部特征,N是提议区域的数量
- 掩码大小:(N,N+hw)


损失函数
动机
- CLIP的分类结果与提议区域的质量有关
- 为了强制将分类概率和提取区域的质量对齐,引入了以下损失。

动机2
为了微调带来的严重过拟合问题,引入以下损失
