3- Python 网络爬虫 — 如何抓取动态加载数据?Ajax 原理与实战全解析
目录
1、什么是 Ajax?
1.1 Ajax 的核心特点:
1.2 与传统网页的区别:
2、Ajax 数据的分析方法
2.1 工具准备:浏览器开发者工具
2.2 关键步骤:定位 Ajax 请求
2.2.1 步骤 1:触发动态加载行为
2.2.2 步骤 2:筛选 XHR/JS 请求
2.2.3 步骤 3:分析请求详情
2.2.4 步骤 4:验证数据关联性
2.3 常见 Ajax 数据特征
3、Ajax 分析与爬取实战
3.1 目标站点说明
3.2 分析 Ajax 请求(核心步骤)
3.2.1 准备工具:浏览器开发者工具
3.2.2 分析首页电影列表接口
3. 3.3 分析电影详情接口
3.3 Python 爬取实战(分步骤讲解)
3.3.1 环境准备
3.3.2 爬取首页电影列表(分页)
3.3.3 爬取电影详情(通过电影 ID)
3.4 完整代码(整合列表 + 详情)
3.5 演示效果
4、关键技巧与反爬应对
4.1 动态参数处理
4.2 应对反爬(通用方法)
在网络爬虫中,我们常会遇到这样的场景:打开网页后,滚动鼠标或点击按钮,页面内容会动态更新(如加载更多商品、刷新评论),但浏览器地址栏的 URL 却没有变化。这种 “无刷新更新内容” 的背后,往往是 Ajax 技术 在起作用。对于爬虫来说,直接爬取网页 HTML 可能无法获取这些动态加载的数据,因此需要专门的 Ajax 数据抓取方法。
1、什么是 Ajax?
Ajax(Asynchronous JavaScript and XML,异步 JavaScript 和 XML)是一种在无需重新加载整个网页的情况下,能够局部更新网页内容的技术。它允许网页通过后台与服务器进行数据交换,在不干扰用户操作的情况下动态更新页面。
1.1 Ajax 的核心特点:
- 异步通信:网页与服务器交换数据时,不阻塞用户操作(无需等待页面刷新);
- 局部更新:只更新页面需要变化的部分,而非整个页面;
- 数据格式:早期以 XML 为主,现在几乎都使用 JSON(轻量、易解析)。
1.2 与传统网页的区别:
- 传统网页:加载数据时需刷新整个页面,URL 会变化,数据直接嵌入 HTML 源码;
- Ajax 加载:数据通过后台请求获取,URL 不变,数据以 JSON 等格式返回,再由 JavaScript 渲染到页面。
2、Ajax 数据的分析方法
要抓取 Ajax 数据,核心是找到动态加载数据的后台请求(API 接口),而非直接解析网页 HTML。以下是具体分析步骤:
2.1 工具准备:浏览器开发者工具
几乎所有现代浏览器(Chrome、Edge、Firefox)都内置了开发者工具,用于分析网络请求。以 Chrome 为例,打开方式:
- 快捷键:
F12或Ctrl+Shift+I(Windows)/Cmd+Opt+I(Mac); - 菜单路径:右键页面 → “检查” → 切换到 Network 面板。
2.2 关键步骤:定位 Ajax 请求
2.2.1 步骤 1:触发动态加载行为
在网页上执行触发数据加载的操作(如滚动页面、点击 “加载更多”、切换分页),此时开发者工具的 Network 面板会记录所有网络请求。
2.2.2 步骤 2:筛选 XHR/JS 请求
Ajax 请求通常属于 “XHR”(XMLHttpRequest)或 “Fetch” 类型(现代网站常用 Fetch API 替代 XHR)。在 Network 面板的筛选栏中选择 XHR/JS,可快速过滤出动态数据请求(排除 CSS、图片等无关资源)。
2.2.3 步骤 3:分析请求详情
点击一个筛选出的请求,查看其详细信息:
- Request URL:请求的接口地址(核心,爬虫需要请求这个 URL);
- Method:请求方法(通常是 GET 或 POST);
- Headers:请求头(包含 User-Agent、Referer、Cookie 等,爬虫需模拟这些信息以防反爬);
- Query String Parameters(GET 请求)或 Form Data(POST 请求):请求参数(如页码、分类 ID 等,决定返回的数据内容);
- Response:服务器返回的响应数据(通常是 JSON 格式,包含我们需要抓取的内容)。
2.2.4 步骤 4:验证数据关联性
检查 Response 中的数据是否与网页上显示的内容一致(如商品价格、评论内容),确认该请求就是我们需要的目标接口。
2.3 常见 Ajax 数据特征
- 页面内容动态更新时,URL 不变;
- 响应数据格式多为 JSON(可在 Response 面板中看到清晰的键值对结构);
- 请求参数可能包含分页信息(如
page=1、offset=0)、时间戳(timestamp=1620000000)或签名(sign=xxx,用于反爬)。
3、Ajax 分析与爬取实战
3.1 目标站点说明
https://spa1.scrape.center/ 是一个单页应用(SPA),页面内容(如电影列表、电影详情)通过 Ajax 动态加载,适合练习分析和爬取动态数据。
特点:
- 首页电影列表:滚动或翻页时,通过 Ajax 加载新数据;
- 电影详情页:点击电影封面后,动态请求详情接口;
- 无明显反爬(适合学习),但需分析请求参数和接口规律。
3.2 分析 Ajax 请求(核心步骤)
3.2.1 准备工具:浏览器开发者工具
打开 Chrome/Edge 浏览器,按 F12 或 Ctrl+Shift+I 打开开发者工具,切换到 Network → XHR/JS(筛选 Ajax 请求)。
3.2.2 分析首页电影列表接口
- 触发请求:访问
https://spa1.scrape.center/,滚动页面或点击页码,观察Network面板。 - 定位目标请求:
- 发现请求如
https://spa1.scrape.center/api/movie/?limit=10&offset=0(第一页)、offset=10(第二页)… - 参数说明:
limit=10:每页返回 10 条数据;offset=N:偏移量(N=0第一页,N=10第二页…);
- 响应内容:JSON 格式,包含电影
name、cover、rate、id等信息。
- 发现请求如
3. 3.3 分析电影详情接口
点击某部电影封面(如《霸王别姬》),观察到新请求:
https://spa1.scrape.center/api/movie/1/(1是电影 ID,不同电影 ID 不同)- 响应内容:JSON 格式,包含电影简介、导演、演员、时长等详细信息。
3.3 Python 爬取实战(分步骤讲解)
3.3.1 环境准备
pip install requests # 用于发送 HTTP 请求
3.3.2 爬取首页电影列表(分页)
import requests# 基础配置
BASE_URL = "https://spa1.scrape.center/api/movie"
HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}# 爬取多页数据(示例:前 3 页)
for page in range(1, 4): # 爬取第 1~3 页# 计算 offset(offset = (page-1)*limit)offset = (page - 1) * 10params = {"limit": 10,"offset": offset}# 发送 GET 请求response = requests.get(BASE_URL, params=params, headers=HEADERS)# 解析响应(JSON 格式)if response.status_code == 200:data = response.json()movies = data.get("results") # results 是电影列表# 打印电影信息print(f"\n==== 第 {page} 页电影 ====")for movie in movies:print(f"标题:{movie['name']}")print(f"评分:{movie['rate']}")print(f"封面:{movie['cover']}")print(f"ID:{movie['id']}")else:print(f"请求失败,状态码:{response.status_code}")
3.3.3 爬取电影详情(通过电影 ID)
基于上一步获取的 movie['id'],请求详情接口:
# 基于上一步的 movies 数据,遍历请求详情
for movie in movies:movie_id = movie["id"]detail_url = f"{BASE_URL}/{movie_id}" # 拼接详情 URL# 发送请求detail_response = requests.get(detail_url, headers=HEADERS)if detail_response.status_code == 200:detail_data = detail_response.json()print(f"\n==== {movie['name']} 详情 ====")print(f"简介:{detail_data['intro']}")print(f"导演:{detail_data['directors'][0]['name']}") # 导演是列表,取第一个print(f"演员:{', '.join([actor['name'] for actor in detail_data['actors']])}")else:print(f"电影 {movie['name']} 详情请求失败")
3.4 完整代码(整合列表 + 详情)
"""
文件名: 2.py
作者: 墨尘
日期: 2025/8/8
项目名: pythonProject
备注: 爬取spa1.scrape.center的电影数据,支持多页爬取、数据本地保存,适配接口实际返回结构
"""
# 导入所需库
import requests # 用于发送HTTP请求
import json # 用于处理JSON数据
import os # 用于文件路径操作
import warnings # 用于忽略警告信息
import argparse # 用于解析命令行参数
from tqdm import tqdm # 用于显示进度条
from datetime import datetime # 用于生成时间戳# 忽略SSL证书验证警告(测试环境专用,生产环境不建议使用)
# 原因:目标网站证书可能过期或不被信任,临时跳过验证以继续测试
warnings.filterwarnings("ignore", category=requests.packages.urllib3.exceptions.InsecureRequestWarning
)# 基础配置
BASE_URL = "https://spa1.scrape.center/api/movie" # 电影列表接口基础URL
HEADERS = {# 模拟浏览器请求头,避免被网站识别为爬虫"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36","Accept": "application/json, text/plain, */*", # 声明接受JSON格式响应"Referer": "https://spa1.scrape.center/", # 模拟从目标网站跳转过来的请求"X-Requested-With": "XMLHttpRequest" # 标识为Ajax请求,符合网站接口预期
}def init_output_dir(output_dir):"""初始化数据保存目录(如果目录不存在则创建):param output_dir: 目标目录路径:return: 目录路径(确保已存在)"""# 判断目录是否存在,不存在则创建if not os.path.exists(output_dir):os.makedirs(output_dir)return output_dirdef fetch_movie_list(page):"""获取指定页码的电影列表数据:param page: 页码(从1开始):return: 电影列表(字典组成的列表,失败则返回空列表)"""# 计算偏移量:第1页offset=0,第2页offset=10(每页10条数据)offset = (page - 1) * 10# 请求参数:limit控制每页条数,offset控制分页偏移params = {"limit": 10, "offset": offset}try:# 发送GET请求获取电影列表response = requests.get(BASE_URL, # 请求URLparams=params, # URL参数(拼接在URL后面的?limit=10&offset=0)headers=HEADERS, # 请求头(模拟浏览器)verify=False, # 跳过SSL证书验证(解决证书过期问题)timeout=10 # 超时时间(10秒内无响应则放弃))# 检查请求是否成功(状态码200),非200则抛出异常response.raise_for_status()# 解析JSON响应为字典data = response.json()# 返回结果中的电影列表(默认返回空列表以防键不存在)return data.get("results", [])except Exception as e:# 捕获所有异常(网络错误、解析错误等)并提示print(f"第{page}页列表获取失败:{str(e)}")return []def fetch_movie_detail(movie_id):"""获取单部电影的详细信息:param movie_id: 电影ID(从列表接口获取):return: 电影详情字典(失败则返回None)"""# 拼接详情页接口URL(如https://spa1.scrape.center/api/movie/1)detail_url = f"{BASE_URL}/{movie_id}"try:# 发送GET请求获取电影详情response = requests.get(detail_url, # 详情页URLheaders=HEADERS, # 同列表请求头(保持一致性)verify=False, # 跳过SSL验证timeout=10 # 超时时间)# 检查请求状态response.raise_for_status()# 解析JSON响应detail = response.json()# 提取电影信息(根据接口实际返回结构定制,关键修复点)movie_info = {"id": detail.get("id", movie_id), # 电影ID(默认用传入的ID)"name": detail.get("name", "未知标题"), # 电影名称"alias": detail.get("alias", "无别名"), # 电影别名(如英文名)"cover": detail.get("cover", "无封面链接"), # 封面图片URL"score": detail.get("score", "暂无评分"), # 评分# 电影类型(接口返回字符串列表,如["剧情", "爱情"])"types": detail.get("categories", []),# 制作地区(接口返回字符串列表,如["中国内地", "中国香港"])"regions": detail.get("regions", []),# 上映时间(接口字段为published_at)"release_date": detail.get("published_at", "未知上映时间"),# 电影时长(单位:分钟,接口字段为minute)"length": detail.get("minute", "未知时长"),# 导演列表(接口返回字典列表,提取name字段)"directors": [d.get("name", "未知导演") for d in detail.get("directors", [])],# 演员列表(取前5位,格式为"演员名(角色名)")"actors": [f"{a.get('name')}({a.get('role', '未知角色')})" for a in detail.get("actors", [])[:5]],"intro": detail.get("intro", "无简介") # 电影简介}return movie_infoexcept Exception as e:# 捕获异常并提示print(f"电影ID:{movie_id} 详情获取失败:{str(e)}")return Nonedef save_data(data, output_dir):"""将爬取的电影数据保存到本地JSON文件:param data: 要保存的数据(列表或字典):param output_dir: 保存目录"""# 生成时间戳(如20250808_153045),确保文件名唯一timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")# 拼接文件路径(目录+文件名)filepath = os.path.join(output_dir, f"movies_{timestamp}.json")# 写入文件(UTF-8编码避免中文乱码,indent=2格式化JSON)with open(filepath, "w", encoding="utf-8") as f:json.dump(data, f, ensure_ascii=False, indent=2)# 提示保存路径print(f"\n数据已保存至:{filepath}")def main(args):"""主函数:协调各模块完成爬取流程:param args: 命令行参数(包含页数、输出目录等)"""# 初始化输出目录output_dir = init_output_dir(args.output)# 存储所有电影详情的列表all_movies = []# 提示开始爬取print(f"开始爬取 {args.pages} 页电影数据...")try:# 遍历要爬取的页码(用tqdm显示进度条)for page in tqdm(range(1, args.pages + 1), desc="爬取进度"):# 获取当前页的电影列表movie_list = fetch_movie_list(page)# 如果列表为空,跳过当前页if not movie_list:continue# 遍历当前页的每部电影,获取详情for movie in movie_list:# 从列表项中提取电影IDmovie_id = movie.get("id")# 如果ID不存在,跳过该电影if not movie_id:continue# 获取电影详情detail = fetch_movie_detail(movie_id)# 如果详情获取成功,添加到总列表if detail:all_movies.append(detail)# 如果开启详细日志模式,打印已获取的电影标题if args.verbose:print(f"已获取:《{detail['name']}》")except KeyboardInterrupt:# 捕获用户Ctrl+C中断,提示保存已爬取数据print("\n用户中断,正在保存已爬取数据...")# 保存数据(如果有有效数据)if all_movies:save_data(all_movies, output_dir)print(f"共成功获取 {len(all_movies)} 部电影数据")else:print("未获取到有效电影数据")# 程序入口(当脚本直接运行时执行)
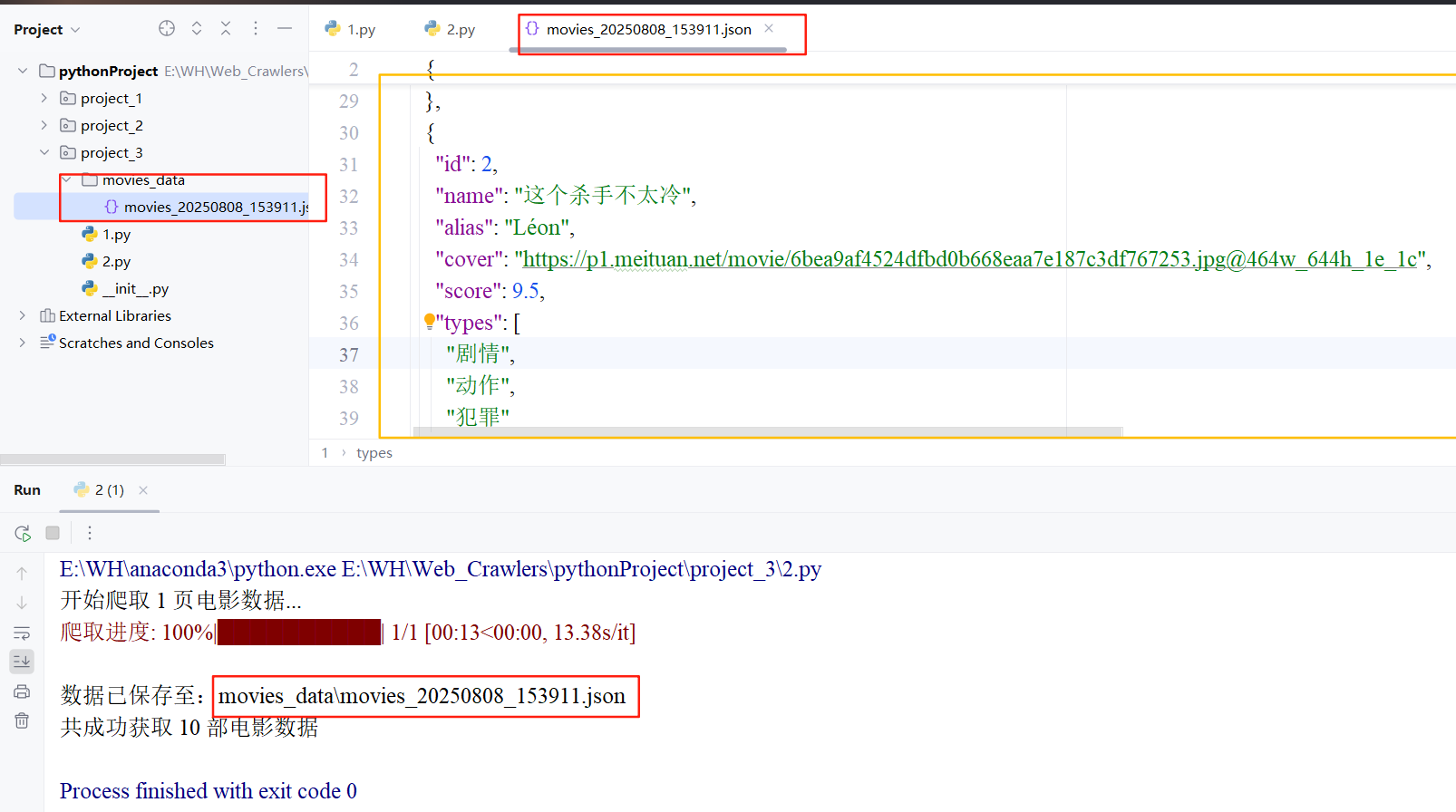
if __name__ == "__main__":# 创建命令行参数解析器parser = argparse.ArgumentParser(description="spa1.scrape.center电影爬虫")# 添加参数:爬取页数(默认1页)parser.add_argument("--pages", type=int, default=1, help="爬取页数(默认1页)")# 添加参数:数据保存目录(默认movies_data)parser.add_argument("--output", type=str, default="movies_data", help="数据保存目录")# 添加参数:详细日志模式(默认关闭,--verbose开启)parser.add_argument("--verbose", action="store_true", help="显示详细爬取日志")# 解析命令行参数args = parser.parse_args()# 调用主函数开始爬取main(args)3.5 演示效果
4、关键技巧与反爬应对
4.1 动态参数处理
若接口包含时间戳(timestamp)、签名(sign)等动态参数:
- 打开
Sources面板(浏览器开发者工具),搜索参数名(如sign),分析 JS 生成逻辑; - 在 Python 中模拟生成(如
int(time.time() * 1000)生成时间戳)。
4.2 应对反爬(通用方法)
- 设置请求头:携带
User-Agent、Referer,模拟真实浏览器; - 控制请求频率:
import time; time.sleep(1)降低请求速度; - 使用代理 IP:若被封 IP,搭配代理池(如
requests+ 代理); - 解析加密响应:若响应是加密的(如
response.text是乱码),需分析解密逻辑(查看 JS 代码)。