DMA伟大的数据搬运工
一、DMA概念描述
嵌入式开发中,DMA是个伟大的数据搬运工,它可以给系统提高2-5倍的运行效率。今天博主不讲枯燥的配置步骤,毕竟每个处理器、每个外设的DMA实现都不尽相同。博主目标是带大家搞懂DMA的本质、它为什么能让系统更快以及什么时候可以使用它。
DMA,全称为: Direct Memory Access,即直接存储器访问。 DMA 传输方式无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件为 RAM 与 I/O 设备开辟一条直接传送数据的通路,能使 CPU 的效率大为提高。
看完上面的,会发现感觉没啥作用,现在举一个例子说明,看懂例子后回头看DMA概念,就会恍然大悟。传统上,我们一般会使用CPU做所有事情,比如我现在开发一个系统,我需要使用ADC采集数据,然后通过CAN发送数据,还要做很多逻辑控制,如果系统足够庞大,那么CPU就闲不下来,每次ADC采集完数据,就会触发中断,CPU得赶紧跑去把数据从ADC的寄存器搬到内存,再从内存搬到CAN接收发送出去,发送完后还要进行很多逻辑处理。整个过程,CPU就像个勤勤恳恳的打工人,每个过程都需要走一遍。
问题来了:CPU可是个高智商选手,干这种机械的搬运活儿,简直是大材小用,更别说搬运数据占用了大量CPU时间,留给真正有价值的工作比如数据分析、算法处理的时间就少了。更烦的是,如果数据量大、传输频繁,CPU可能会忙到连喝口水的时间都没有,系统性能直接拉胯。这时候,DMA就登场了。它就像雇了个专职物流小哥,把搬运数据的活儿全包了,让CPU能专心干大事,比如跑算法、优化逻辑。
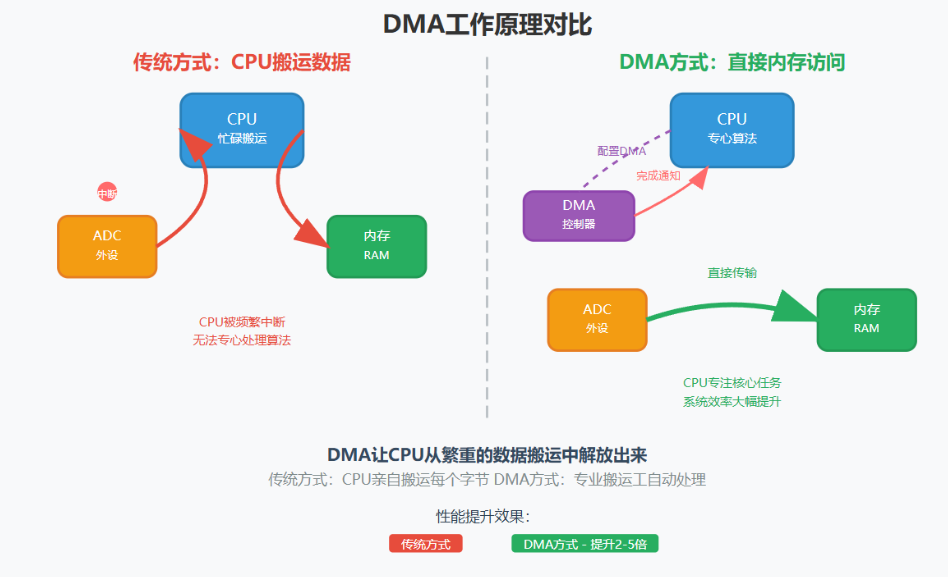
所以DMA的作用就是将搬运数据的活揽在自己身上,等处理完了之后在通知CPU,这样CPU就有更多时间去做高难度的事情,就比如有师傅和徒弟,遇到跑腿的活肯定徒弟跟上。
二、DMA相关配置参数
上文我们知道了DMA的概念之后,接下来该了解如何使用DMA,毕竟我要小弟给我拿东西,我都要交代它一些事项。比如在STM32上,需要设置DMA通道、源地址、目标地址、传输方向、数据宽度、触发条件等等。稍微配错一点,数据可能搬到不知名的地方,或者压根没搬,数据都不知道去哪了。
2.1 DMA 控制器与外设映射
以STM32F207举例,它有2个DMA控制器,每个控制器有8个数据流,每个数据流可以映射到不同的通道。例如,DMA2的数据流7可能用于某个特定外设,比如USART1的TX。(每个数据流同一时间只能服务一个外设。例如,若USART1_TX占用了DMA2_Stream7,则该流不可用于其他外设),具体的对应关系需要查看DMA的映射表格。所以第一步我们应该清除我们需要配置哪一个外设,以及使用哪一个DMA控制器的哪一个数据流。
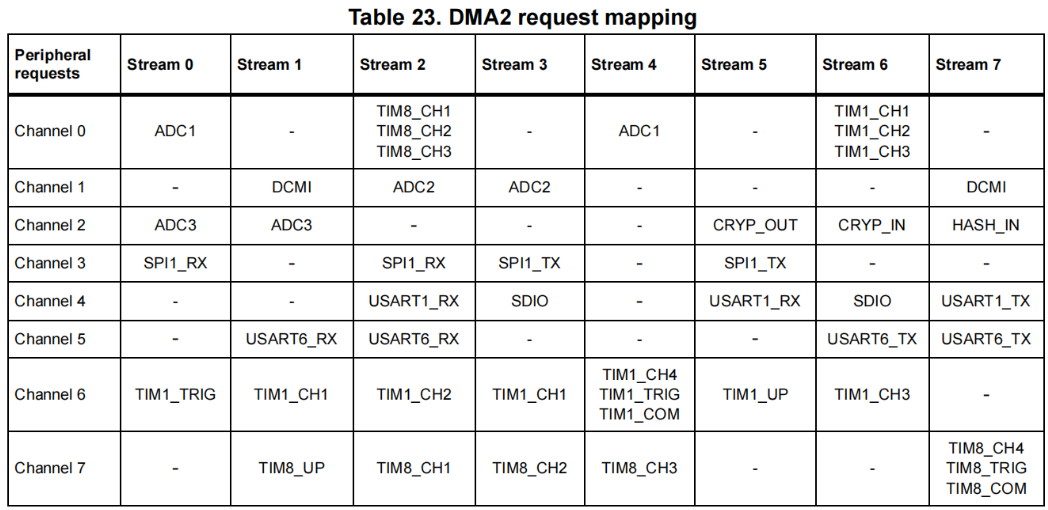
2.2 DMA传输方向
- 内存 → 外设(Memory-to-Peripheral),USART发送,SPI发送...
- 外设 → 内存(Peripheral-to-Memory),USART接收,ADC采样,SPI接收...
- 内存 → 内存(Memory-to-Memory)
举例1:当串口发送数据时,我们一般的处理方式是CPU调用发送函数,然后存放到TDR寄存器中发送,但当有了DMA,我们可以直接指挥它,小弟,现在帮我把发送数据搬运到TDR寄存器中,这就是第一种传输方向,内存到外设
举例2:当接收串口数据时,我们一般的处理方式是,等待触发接收中断,然后触发后CPU马不停蹄的处理接收数据,但我们现在有小弟了,我们就让小弟一直等着,有数据来了给我存放到一个数组中,然后接收完了通知cpu即可,这就是第二种传输方式,外设到内存
举例3:此处省略
2.3 DMA数据宽度
- 外设数据宽度(
PeripheralDataSize):- 8-bit(
DMA_PDATAALIGN_BYTE) - 16-bit(
DMA_PDATAALIGN_HALFWORD) - 32-bit(
DMA_PDATAALIGN_WORD)
- 8-bit(
- 内存数据宽度(
MemoryDataSize):- 需与外设宽度匹配,否则数据错位。
一般来说,串口配置为8位,SPI配置为8位,ADC配置为16位
2.4 地址自增
| 配置项 | 描述 |
|---|---|
PeripheralInc | 外设地址是否递增(通常 不递增,因为外设寄存器固定) |
MemoryInc | 内存地址是否递增(通常 递增,用于连续数据存储) |
2.5 传输长度
NDTR(Number of Data to Transfer):
设置传输的数据量(单位:数据宽度)。
例如:传输 100 个 uint16_t,则 NDTR = 100。
2.6 触发方式
| 触发源 | 描述 | 典型应用 |
|---|---|---|
| 软件触发 | 手动启动 DMA | 内存到内存传输 |
| 硬件触发 | 外设事件触发(如 UART 发送完成) | UART、SPI、ADC 等外设驱动 |
2.7 DMA中断
| 中断类型 | 触发条件 | 常用场景 |
|---|---|---|
| 传输完成(TC, Transfer Complete) | DMA 传输完所有数据 | 处理接收到的数据 |
| 半传输完成(HT, Half Transfer) | 传输一半数据时触发 | 双缓冲模式(Ping-Pong Buffer) |
| 传输错误(TE, Transfer Error) | DMA 传输出错(如访问非法地址) | 错误恢复 |
2.8 总结
上述的一些配置参数不需要背诵,需要理解,当自己配置DMA时,首先会找例程代码或者晚上搜索代码,然后复制下来,自己只需要知道要配置哪一些参数,如何使用即可。
三、实际应用
HAL库配置RS485+DMA+空闲中断收发数据_hal 库dma发送数据-CSDN博客
HAL库配置ADC+DMA_stm32cubemx adc-CSDN博客
四、注意事项
问题1:以串口举例,串口空闲中断判断一帧数据接收完成后,我们常见做法是置标志位,然后处理数据,问题来了,如果处理过程中如果有数据到来,此时会覆盖接收数组,请问有什么好的处理方法?
(1)处理数据过程中可以关闭接收中断,处理完成后再打开接收中断,这样的弊端是,可能会漏掉数据。
(2)处理数据过程中可以关闭接收中断,将接收数组赋值到临时变量,再打开接收中断,由于cpu处理速度较快,所以基本不会漏掉数据,但这样的弊端是,占用栈空间大小
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 双缓冲(Ping-Pong Buffer) | 高速数据流(如Modbus、CAN) | 无数据丢失,实时性好 | 内存占用稍高 |
| 环形缓冲区(Ring Buffer) | 不定长数据(如GPS、日志) | 内存利用率高,适合持续数据流 | 需处理缓冲区满的情况 |
| DMA+空闲中断+双缓冲 | 低功耗MCU(如STM32) | 极低CPU占用,高可靠性 | 依赖硬件支持 |
注意:环形缓冲区的目的就是充分利用内存,当设置空间是10,然后再接收到6个数据后进入了处理函数,此时可以不关闭接收中断,数据可以不被覆盖,继续接收,然后处理函数只需要处理接收的6个数据即可,但问题在于,环形缓冲区满了之后的处理方式,是丢弃还是覆盖
问题2:接收数组的大小如何定义?
(1)以串口举例,波特率为115200bit/s,然后换算成字节就是1S可以发送14400字节,如果10ms处理一次数据,那么10ms以内最多接收144字节的数据,即数组大于144即可