Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline

标题:跟踪任何异常对象:一种细粒度的视频异常检测流水线
原文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Huang_Track_Any_Anomalous_ObjectA_Granular_Video_Anomaly_Detection_Pipeline_CVPR_2025_paper.pdf
发表:CVPR-2025
摘要
视频异常检测(VAD)在诸如监控和自动驾驶等场景中至关重要,因为及时检测意外活动是必要的。尽管现有方法主要集中在通过识别异常帧或对象来检测视频中的异常对象,但它们往往忽视了更细致的分析,例如异常像素,这限制了它们捕捉更广泛异常的能力。为了解决这一挑战,我们提出了一个创新的VAD框架,称为跟踪任何异常对象(TAO),它引入了一个细粒度的视频异常检测框架,首次将多个细粒度的异常对象检测集成到统一框架中。与每时每刻对每个像素分配异常分数的方法不同,我们的方法将问题转化为对异常对象的像素级跟踪。通过将异常分数与后续任务如图像分割和视频跟踪联系起来,我们的方法消除了阈值选择的需求,并实现了更精确的异常定位,即使在长而具有挑战性的视频序列中也是如此。在广泛的数据库上的实验表明,TAO达到了最先进的性能,为VAD提供了一个实用、细粒度且整体的解决方案。更多信息,请访问项目页面:https://tao-25.github.io/
1. 引言
视频异常检测(VAD)涉及识别监视视频中的不寻常或意外活动,在安全监控(例如检测暴力行为)和自动驾驶(例如识别交通事故)等领域有着重要的应用。当前的VAD研究沿着两个主要方向发展,这些都反映在方法论和评估基准上。
当前的方法存在根本性不足,因为以帧为中心的方法只能识别异常的存在而不能定位具体的区域,而以对象为中心的方法虽然更为精确,但缺乏像素级的准确性。这些局限性在包含重叠异常的复杂场景中尤为明显,其中准确描绘对象边界和形状至关重要。为了应对这一挑战,我们建议增强现有的VAD基准测试,增加像素级异常评估。
然而,在视频中实现精确的像素级跟踪存在重大挑战,特别是在跨帧保持语义和时间一致性方面。传统的监督方法需要大量的标记数据,而这在现有带有像素级注释的数据集中是稀缺的。为了克服这些挑战,我们利用了SAM2,这是一个大规模预训练的分割模型,能够在无需额外微调特定异常数据集的情况下实时处理静态图像和视频流。其能够精确描绘对象轮廓和结构的特点使其在处理涉及重叠异常或遮挡的复杂场景时特别有效。
在此基础上,我们提出了 TAO——一个将基于对象的异常检测算法与 SAM2 相结合的集成框架,从而构建了一个简洁而高效的细粒度视频异常检测系统。对于包含异常帧的视频,我们的基于对象的检测模型会为检测到的异常生成边界框。经过鲁棒性过滤后,这些边界框将作为 SAM2 的提示框,从而生成异常对象的分割掩码。在我们提出的基准上进行评估时,该方法在两个广泛使用的数据集上均取得了最先进的性能,表明它在弥合对象级检测与像素级精确分割之间差距方面的有效性。
本文的贡献如下:
- 我们提出了一种新的测试标准,将像素级与对象级的评估统一起来,解决了在包含多个或重叠异常的复杂场景中现有指标的局限性。
- 我们提出了 TAO——一个将基于对象的异常检测与视觉基础模型的分割能力相结合的简洁框架,使得无需额外微调即可实现异常对象的精确像素级跟踪。
- 通过在 UCSD Ped2 和 ShanghaiTech Campus 数据集上的大量实验,我们证明了该方法在传统指标和我们提出的基准下均达到了最先进的性能。
相关工作
视频异常检测
视频异常检测(VAD)由于异常数据的稀有性和异常事件类型的多样性而面临重大挑战,这阻碍了现有模型在不同场景中的泛化能力。传统的VAD方法可以大致分为以帧为中心和以对象为中心的方法。以帧为中心的方法分析整个帧或序列,通常利用重构或预测误差来识别异常。这些方法特别适合于检测如火灾或烟雾等全局事件。然而,它们在处理局部异常时表现不佳,并且容易受到帧内正常区域的干扰,限制了其在复杂场景中的精度。以对象为中心的方法专注于帧内的特定对象,通过使用预训练的对象检测模型提取边界框并评估其异常性。这种针对性的方法更适合于检测与个体或对象相关的异常,例如人类跌倒或车辆事故。通过专注于特定区域并减少冗余信息,以对象为中心的方法在复杂、多对象环境中实现了更高的准确性和鲁棒性。基于这些基础,我们的方法首次集成了大规模预训练模型用于VAD中的像素级细粒度检测。这一进步使得精确的异常定位成为可能,弥合了帧级分析与对象级检测之间的差距,并显著提高了整体检测性能。
视觉基础模型
近年来,大规模预训练语言模型(LLMs)和视觉-语言模型(VLMs)在推进视频异常检测方面展现了显著潜力。诸如BLIP-2[26]、LLaVA[29]、LAVAD[59]、VadCLIP[51]、VideoChatGPT[35]和Video-LLaMA[61]等模型通过整合视觉和语言信息极大地改进了对复杂视觉任务的理解。同时,提示技术在大规模视觉模型中得到了广泛应用,使图像分割等任务取得了实质性进展。基于这些进展,Segment Anything Model 2(SAM2)[42]进一步提升了分割性能,特别是对于基于视频的应用程序。SAM2集成了提示技术,不仅可以以高精度分割静态对象,还可以捕捉视频上下文中的动态、复杂对象。这一功能使得SAM2能够提供更细致的分割和增强的定位准确性,在视频异常检测中解决了现实世界的多样性和复杂性带来的挑战。这项工作利用了SAM2先进的视频分割能力,解决了细粒度视频异常检测的挑战,实现了在复杂场景中的精确和稳健的异常识别。
方法
预备知识
在提出的视频异常检测(VAD)基准中,一个视频片段表示为序列 {f1,f2,...,fNf}⊆C\{f_1, f_2,..., f_{N_f}\} \subseteq C{f1,f2,...,fNf}⊆C,其中 CCC 是所有可能视频片段的集合,NfN_fNf 表示总帧数。每一帧 fif_ifi 表达为 fi=[pi,1,pi,2,...,pi,Ni]f_i=[p_{i,1}, p_{i,2},..., p_{i,N_i}]fi=[pi,1,pi,2,...,pi,Ni],其中 NiN_iNi 是该帧中的总像素数,pi,j∈Pp_{i,j} \in Ppi,j∈P 表示第 jjj 个像素,PPP 是可能的像素值集合。每个像素 pi,jp_{i,j}pi,j 被分类为“正常”或“异常”。
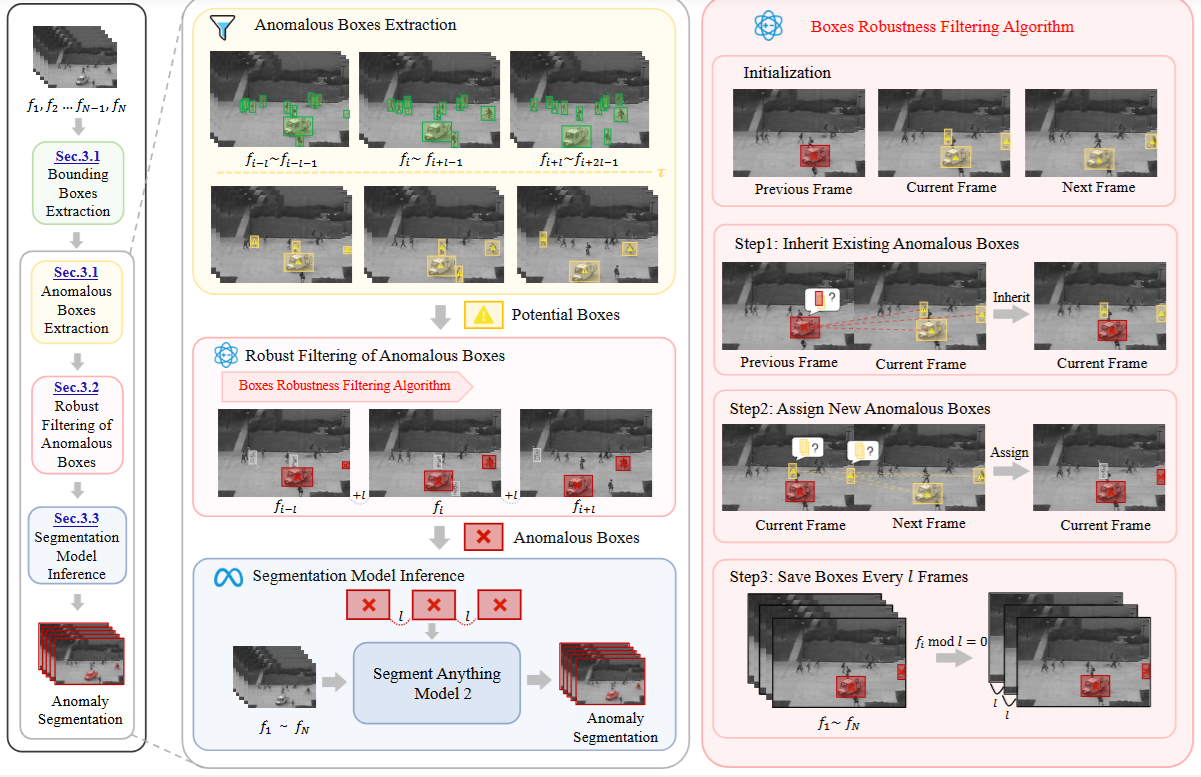
图2. 我们提出的TAO的流程。我们首先生成边界框以识别每帧中的对象。接下来,我们使用以对象为中心的视频异常检测算法对这些框进行评分,以提取潜在的异常框。为了确保鲁棒性,我们应用过滤以消除冗余框。最后,将过滤后的框和原始帧输入到基于提示的分割模型中,以生成像素级异常分割掩码。
概述
为了实现视频中的精确异常定位,我们设计了一个流线型的管道用于视频异常检测中的像素级分割。我们的管道包括四个阶段:边界框提取、异常框提取、稳健过滤和分割推理。过程从生成边界框开始以识别感兴趣的对象。然后,使用以对象为中心的视频异常检测算法对这些框进行评分以提取潜在的异常框。接下来是一个基于跟踪的过滤步骤,以消除冗余框并保留只有稳健的框。最后,过滤后的框和原始帧被输入到基于提示的分割模型中,以生成像素级异常分割掩码。管道如图2所示。
3.1 异常框提取
边界框提取。为了在视频异常检测中实现精确的像素级分割,使用预训练的对象检测算法为帧中的对象生成边界框,作为引导分割模型的潜在提示。对于给定的输入帧 fff,对象检测模型 DDD 输出 mmm 个边界框 b1,b2,...,bmb_1, b_2,..., b_mb1,b2,...,bm,每个边界框都配有一个类别标签 y1,y2,...,ymy_1, y_2,..., y_my1,y2,...,ym:
{(b1,y1),(b2,y2),...,(bm,ym)}=D(f)\{(b_1, y_1), (b_2, y_2),..., (b_m, y_m)\} = D(f) {(b1,y1),(b2,y2),...,(bm,ym)}=D(f)
在每一帧中提取对象边界框后,以对象为中心的VAD算法计算其边界框 bib_ibi 内每个对象的异常分数 sis_isi。该分数源自诸如姿势、速度和深度等特征,并可以正式表示为:
si=A(bi)s_i = A(b_i) si=A(bi)
其中 AAA 表示用于对象中心视频异常检测算法中的评分函数。为了隔离异常对象,我们根据异常分数阈值过滤边界框。具体来说,我们只保留异常分数超过预定义阈值 τ\tauτ 的边界框,如以下表达式所示:
Banomaly={bi∣si>τ}B_{anomaly} = \{b_i | s_i > \tau\} Banomaly={bi∣si>τ}
其中 τ\tauτ 表示异常分数阈值,sis_isi 是第 iii 个对象的异常分数,bib_ibi 是相应的边界框。
3.2 异常框的稳健过滤

从第3.1节检测到的异常框由于正常和异常框之间的重叠特性而包含许多误报。这种重叠使阈值设置复杂化并导致误分类。这些冗余框通过生成不准确的结果和压倒模型的跟踪能力,显著降低了分割性能,可能会导致后续帧中丢失异常目标。如图3所示,使用潜在异常框作为SAM2提示(红色掩码:真实异常;绿色掩码:冗余结果)在固定间隔内揭示了跟踪错误的影响。虽然模型最初能有效地跟踪异常对象,但跟踪误差随时间积累,导致错误跟踪对象数量增加,最终导致对真实异常的灾难性遗忘,反映在Pixel-F1得分的稳步下降上。
为了增强鲁棒性和解决冗余问题,我们提出了一个名为“边界框稳健过滤”的算法,它利用了真实异常框的时间一致性。与随机出现的冗余框不同,真正的异常框保持对同一目标的一致跟踪。算法详细描述见算法1,分为三个关键步骤。首先,继承步骤计算当前帧 fif_ifi 中每个边界框 bjb_jbj 和前 kkk 帧中的边界框 bpb_pbp 之间的相似性。如果交并比(IoU)超过阈值 hhh 至少 mmm 帧,则 bjb_jbj 继承早期帧中的标签 LpL_pLp,确保对先前识别出的异常进行一致跟踪。其次,分配步骤处理未继承标签的边界框,通过将其与接下来的 kkk 帧中的边界框进行比较。如果IoU超过 hhh 至少 mmm 帧,则分配一个新的标签 Lj=F(bj)L_j=F(b_j)Lj=F(bj),有效地标记新出现的异常。最后,保存步骤每 lll 帧记录一次边界框及其标签,系统地捕捉所有已识别的异常。通过迭代应用这些步骤,“边界框稳健过滤”算法实现了异常对象的稳健跟踪和定位。每个边界框及其标签存储为元组 Tbox=(fi,bj,Lj)T_{box}=(f_i, b_j, L_j)Tbox=(fi,bj,Lj),确保视频帧之间空间和时间的一致性。这种方法减少了冗余并增强了异常检测准确性,为后续分割和分析提供了可靠的基础。
3.3 分割模型推理
使用从第3.2节获得的元组 Tbox=(fi,bj,Lj)T_{box}=(f_i, b_j, L_j)Tbox=(fi,bj,Lj),我们提取每个边界框 bjb_jbj 的中心点。具体而言,给定框 bj=[x1,y1,x2,y2]b_j=[x_1, y_1, x_2, y_2]bj=[x1,y1,x2,y2] 的坐标,计算中心点如下:
cj=(x1+x22,y1+y22)c_j=\left(\frac{x_1+x_2}{2}, \frac{y_1+y_2}{2}\right) cj=(2x1+x2,2y1+y2)
实际上,这些提示不是为每一帧保存的,而是定期收集,特别是每隔 lll 帧收集一次,如第3.2节所述。这保证了高效的存储和处理,同时仍然捕获了准确分割所需的必要信息[23, 25]。对于每个选定的帧,既存储中心点 cjc_jcj 又存储边界框 bjb_jbj 作为提示。而不是单独处理每个帧,我们将来自所有保存帧 {f1,f1+l,f1+2l,...,fNf}\{f_1, f_{1+l}, f_{1+2l},..., f_{N_f}\}{f1,f1+l,f1+2l,...,fNf} 的提示聚合起来,其中 lll 表示保存间隔。聚合后的提示是:
I={(cj,bj,fi)∣i=1,1+l,1+2l,...,Nf}I=\{(c_j, b_j, f_i) | i=1, 1+l, 1+2l,..., N_f\} I={(cj,bj,fi)∣i=1,1+l,1+2l,...,Nf}
其中 III 表示包含中心点、边界框坐标 bjb_jbj 和原始帧 fif_ifi 的提示集合。通过将定期保存的提示信息 III 输入作为基于提示的分割模型 MMM 的SAM2,我们利用其特征传播能力高效地为整个视频生成像素级分割结果。SAM2将来自提示帧的分割结果传播到剩余帧,在整个视频中产生像素级分割:
S=M(I)={S1,S2,...,SNf}S=M(I)=\{S_1, S_2,..., S_{N_f}\} S=M(I)={S1,S2,...,SNf}
其中 Si=[p1,p2,...,pM]S_i=[p_1, p_2,..., p_M]Si=[p1,p2,...,pM] 表示帧 fif_ifi 的分割结果,每个像素 pjp_jpj 要么是“正常”,要么是“异常”。这种方法能够生成完整的分割集 SSS,高效地利用来自提示的上下文信息。
4. 实验

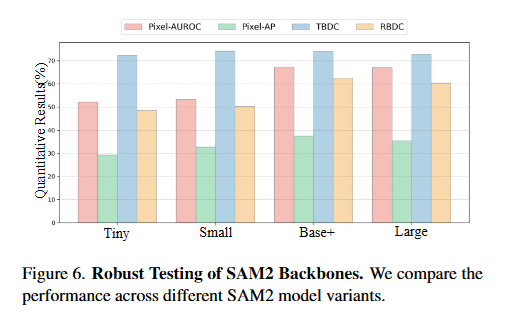
4.1 新的综合VAD基准
基准设计。我们提出了一个新的基准框架,整合了像素级和对象级评估指标来推进VAD模型评估。这种双层次方法解决了使用单一评估指标的局限性。像素级指标通过独立像素评估擅长识别细微的不规则现象,但在捕捉更广泛的空间模式方面存在困难。对象级指标通过评估形状和位置等全局特征补充了这一点,实现了连贯的异常跟踪和识别。通过结合这些互补的观点,我们的框架提供了对细粒度细节和整体异常模式的全面评估,对于实际应用尤其有价值。
基准数据集。UCSD Ped2[47] 包含16个训练视频和12个测试视频(分辨率为240×360像素),由固定俯视摄像头拍摄。训练集包含正常的行人活动,而测试集包括骑自行车者、滑板者和车辆等异常事件。ShanghaiTech Campus[30] 是最大的VAD数据集之一,包含330个训练视频和107个测试视频(分辨率为480×856像素)。虽然训练集展示了正常场景,但测试集包含了抢劫、打斗和在步行区未经授权骑行等各种异常情况。
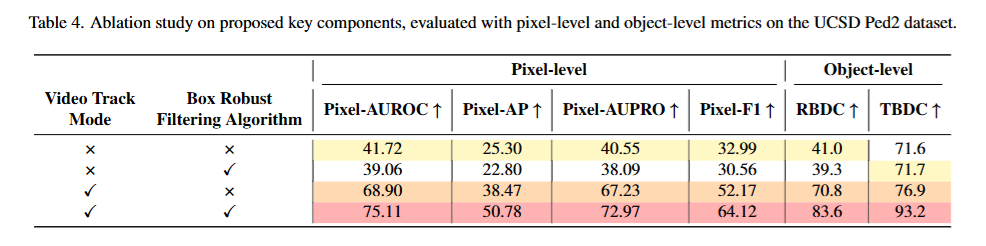
基准指标。对于像素级评估,我们采用了四个指标:Pixel-AUROC衡量不同阈值下正常和异常像素之间的区分能力;Pixel-AP通过平衡假阳性和假阴性来评估检测精度;Pixel-AUPRO通过区域重叠量化分割准确性;Pixel-F1提供了一个综合的精确召回测量。对于对象级评估,我们使用基于区域的检测标准(RBDC)和基于轨迹的检测标准(TBDC)。RBDC使用交并比(IoU)与阈值 α\alphaα 来衡量空间准确性,而TBDC评估跨帧跟踪异常区域的时间一致性。这些指标共同提供了对空间精度和时间一致性的全面评估。
4.2 实施细节
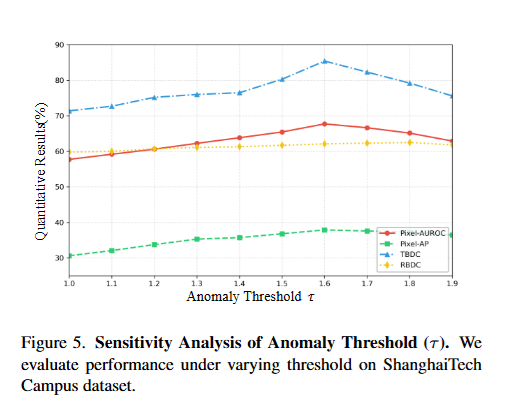
我们的框架基于SAM2[42],利用对象级异常检测算法[43]提取异常边界框作为分割提示。我们采用SAM2作为基于提示的分割模型,它将这些提示与原始帧结合以实现精确的异常分割。我们的实现采用了部分微调策略,其中仅对象级VAD算法在目标数据集上进行微调,而SAM2保留其预训练权重用于推理。在边界框阈值过滤阶段,我们根据姿势和深度特征分配异常分数,对于UCSD Ped2设置阈值 τ=1.5\tau=1.5τ=1.5,对于ShanghaiTech Campus设置阈值 τ=1.6\tau=1.6τ=1.6。随后的稳健性过滤阶段使用了跟踪窗口 k=5k=5k=5,帧匹配阈值 m=3m=3m=3,以及框重叠阈值 h=0.2h=0.2h=0.2,保存间隔分别为UCSD Ped2的 l=5l=5l=5 和ShanghaiTech Campus的 l=15l=15l=15。对于分割,我们在NVIDIA RTX 4090 GPU上使用带有hiera base-plus权重的SAM2。为了确保鲁棒评估,合并了同一异常的重叠框,并对分割概率图进行了统一二值化处理。对于对象级指标,我们从分割极值坐标中推导出边界框。给定异常像素 P=(x1,y1),(x2,y2),...,(xN,yN)P=(x_1, y_1), (x_2, y_2),..., (x_N, y_N)P=(x1,y1),(x2,y2),...,(xN,yN),计算框坐标如下:
xmin=min(xi,yi)∈Pxi,xmax=max(xi,yi)∈Pxi,ymin=min(xi,yi)∈Pyi,ymax=max(xi,yi)∈Pyix_{min}=\min_{(x_i,y_i)\in P} x_i,\quad x_{max}=\max_{(x_i,y_i)\in P} x_i,\quad y_{min}=\min_{(x_i,y_i)\in P} y_i,\quad y_{max}=\max_{(x_i,y_i)\in P} y_i xmin=(xi,yi)∈Pminxi,xmax=(xi,yi)∈Pmaxxi,ymin=(xi,yi)∈Pminyi,ymax=(xi,yi)∈Pmaxyi
最终得到的边界框 (xmin,ymin,xmax,ymax)(x_{min}, y_{min}, x_{max}, y_{max})(xmin,ymin,xmax,ymax) 用于计算RBDC和TBDC指标,从而在对象级别提供稳健的空间评估。
4.3 对比异常检测模型
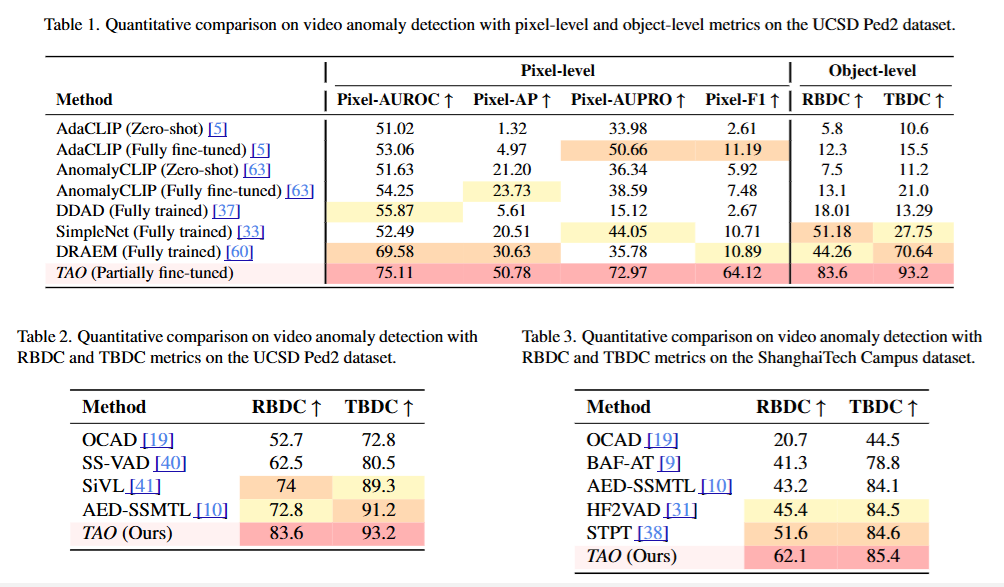
鉴于当前视频异常检测模型缺乏像素级分割能力,我们将几种最先进的图像异常检测算法(包括AdaCLIP[5]、AnomalyCLIP[63]、DRAEM[60]、DDAD[37]和SimpleNet[33])作为基准,评估它们在UCSD Ped2数据集上的像素级和对象级指标。选择AdaCLIP和AnomalyCLIP是因为它们具有预训练的视觉-语言架构,这与SAM2的设计紧密相关,并展示了强大的零样本能力。为了确保公平比较,我们在零样本和完全微调设置下评估了AdaCLIP和AnomalyCLIP。相比之下,DRAEM、DDAD和SimpleNet作为完全训练的模型提供了像素级和对象级异常检测的强大基线,代表了多样的方法论方法。对于异常检测,视频流通过每个算法逐帧处理,生成识别潜在异常的热图。通过对这些热图应用阈值来实现像素级分割,允许对异常区域进行精确定位。
如表1所示,实验结果清楚地表明了我们的模型在像素级和对象级异常检测方面的优势。虽然大多数基准模型难以平衡这两个方面,在一方面表现出色而在另一方面表现不佳,但我们的模型在这两方面都取得了成功。
4.3 对比异常检测模型
鉴于当前视频异常检测模型缺乏像素级分割能力,我们对几种最先进的图像异常检测算法进行了基准测试,包括AdaCLIP[5]、AnomalyCLIP[63]、DRAEM[60]、DDAD[37]和SimpleNet[33],以评估它们在UCSD Ped2数据集上的像素级和对象级指标。选择AdaCLIP和AnomalyCLIP是因为它们具有预训练的视觉-语言架构,这与SAM2的设计紧密相关,并展示了强大的零样本能力。为了确保公平比较,我们在零样本和完全微调设置下评估了AdaCLIP和AnomalyCLIP。相比之下,DRAEM、DDAD和SimpleNet作为完全训练的模型提供了像素级和对象级异常检测的强大基线,代表了多样化的技术方法。对于异常检测,视频流通过每个算法逐帧处理,生成热图来识别潜在的异常。通过对这些热图应用阈值实现像素级分割,允许精确定位异常区域。
实验结果清楚地表明了我们的模型在像素级和对象级异常检测方面的优势。虽然大多数基准模型难以平衡这两个方面,在一方面表现出色而在另一方面表现不佳,但我们的模型在这两方面都取得了成功。具体而言,在UCSD Ped2数据集上,我们的模型在Pixel-AUROC、Pixel-AP、Pixel-AUPRO和Pixel-F1等像素级指标以及RBDC和TBDC等对象级指标上均达到了最佳性能。
结论
本文提出了一种新的细粒度视频异常检测框架TAO,该框架首次实现了对多个细粒度异常对象的统一检测。与现有的方法相比,我们的方法不仅能够检测到异常的存在,还能够精确地定位和跟踪这些异常,即使在长而复杂的视频序列中也是如此。通过结合基于提示的分割模型SAM2,我们的方法有效地解决了现有方法中存在的冗余问题,提高了异常检测的准确性和鲁棒性。实验结果表明,TAO在广泛使用的UCSD Ped2和ShanghaiTech Campus数据集上均达到了最先进的性能,证明了其在实际应用中的潜力。
思考:简单,但是可能有效,更适合工业使用吧。