如何在本地使用 DeepSeek Janus-Pro
概述
了解如何设置 DeepSeek Janus-Pro 项目,构建您自己的 Docker 镜像,并在您的笔记本电脑上本地运行 Janus Web 应用程序。
在本文中,我们将了解 Janus 系列,设置 Janus 项目,构建 Docker 容器以在本地运行模型,并使用各种图像和文本提示测试其功能。
什么是DeepSeek Janus-Series
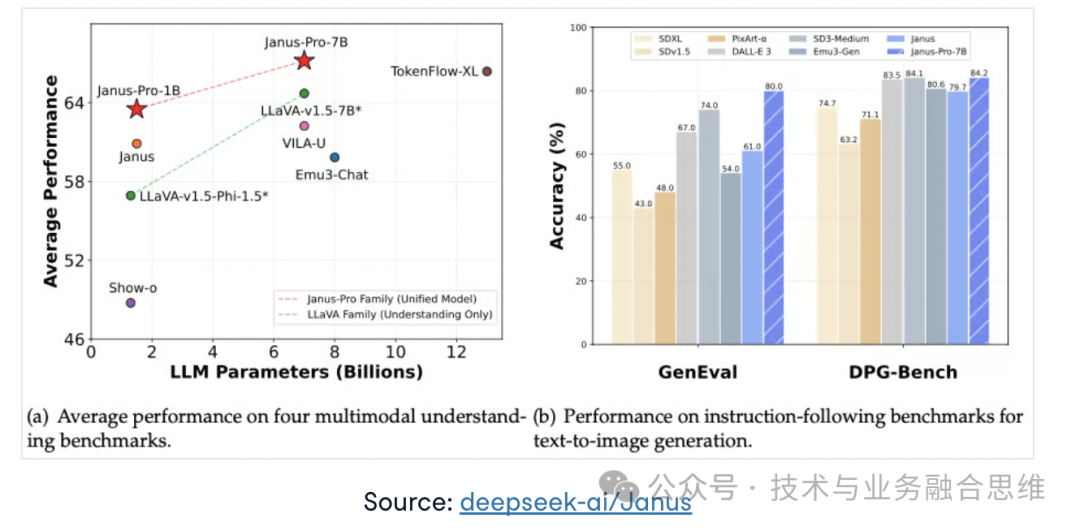
DeepSeek Janus-Series 是一系列新的多模态模型,旨在使用创新框架统一视觉理解和生成任务。该系列包括 Janus、JanusFlow 和高级 Janus-Pro,每个系列都建立在上一次迭代的基础上,在效率、性能和多模式功能方面都有显着改进。
JanusFlow
JanusFlow 将自回归语言建模与修正流相结合,后者是一种最先进的生成建模技术。其极简的设计允许在大型语言模型框架中轻松训练,而无需进行复杂的修改。与专用和统一方法相比,JanusFlow 在基准测试中表现出卓越的性能,有效地突破了视觉语言建模的界限。
Janus-Pro
Janus-Pro 通过引入优化的训练策略、扩展的训练数据集和扩展到更大的模型大小来增强以前的模型。这些进步显著改善了多模态理解和文本到图像的指令跟踪,同时确保了更稳定的文本到图像生成
配置Janus 项目
Janus 是一个相对较新的模型,目前,没有量化版本或本地 AI 应用程序可在笔记本电脑或台式机上轻松使用。
但是,GitHub 上的 Janus 存储库提供了出色的 Gradio Web 应用程序演示,任何人都可以尝试。但是,挑战在于,由于多个软件包冲突,演示经常无法正常工作。
为了解决这个问题,在这个项目中,我们将修改原始代码,构建我们自己的 Docker 镜像,并使用 Docker Desktop 应用程序在本地运行容器
安装 Docker Desktop
要开始使用,请从 Docker 官方网站下载并安装最新版本的 Docker Desktop。
如果您使用的是 Windows,则还需要安装适用于 Linux 的 Windows 子系统 (WSL)。打开终端并运行以下命令以安装 WSL:
wsl --install克隆 Janus 存储库
接下来,从 GitHub 克隆 Janus 存储库并导航到项目目录:
git clone https://github.com/deepseek-ai/Janus.gitcd Janus
修改 demo 代码
切换到 demo 文件夹,然后在您的首选代码编辑器中打开文件app_januspro.py。进行以下更改:
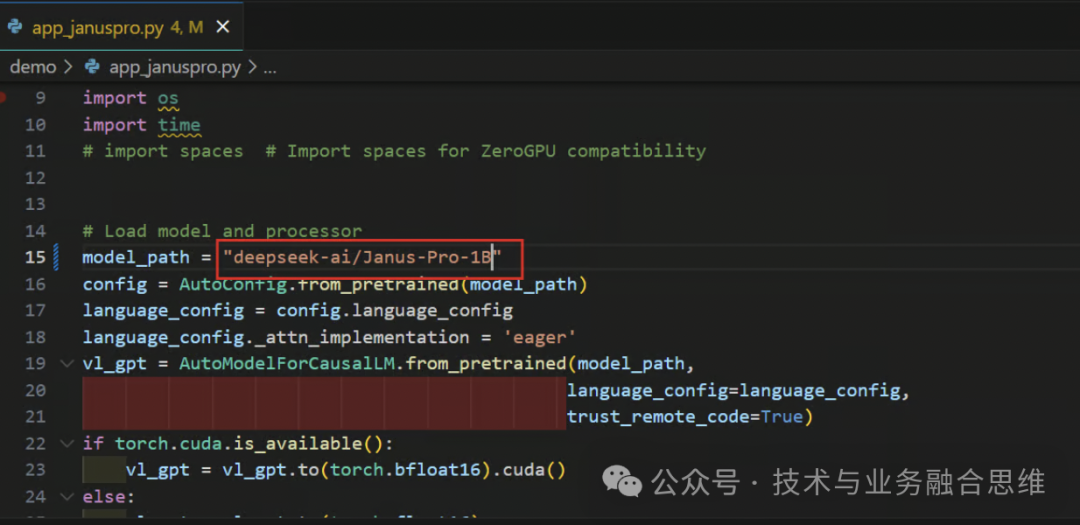
更改模型名称:将 deepseek-ai/Janus-Pro-7B 替换为 deepseek/Janus-Pro-1B。
这将加载模型的较轻版本,其大小仅为 4.1 GB,使其更适合本地使用。
更新脚本的最后一行:将 demo.queue 函数修改为以下内容:
demo.queue(concurrency_count=1, max_size=10).launch(server_name="0.0.0.0", server_port=7860)
创建 Docker 镜像
要容器化应用程序,请在项目的根目录中创建一个 Dockerfile。对 Dockerfile 使用以下内容:
# Use the PyTorch base imageFROM pytorch/pytorch:latest# Set the working directory inside the containerWORKDIR /app# Copy the current directory into the containerCOPY . /app# Install necessary Python packagesRUN pip install -e .[gradio]# Set the entrypoint for the container to launch your Gradio appCMD ["python", "demo/app_januspro.py"]
构建和运行 Docker 镜像
Dockerfile 准备就绪后,我们将构建 Docker 镜像并运行容器。
在终端中键入以下命令以创建 Docker 映像。此命令将使用位于根文件夹中的 Dockerfile,并为映像分配名称 janus:
docker build -t janus . 测试 Janus Pro 模型
该 Web 应用程序具有干净的界面,一切似乎都运行顺利。在本节中,我们将测试 Janus Pro 的多模态理解和文本到图像生成功能。
测试多模态理解
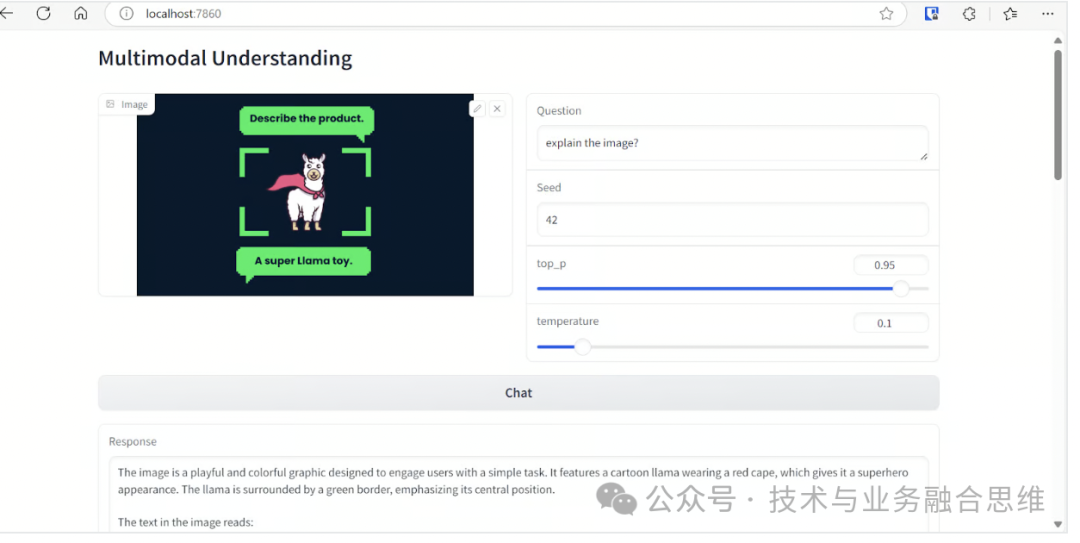
为了评估模型的多模态理解,我们首先从 DataCamp 教程中加载一张图像,并要求模型对其进行解释。结果令人印象深刻 — 即使使用较小的 1B 模型,响应也非常准确和详细。
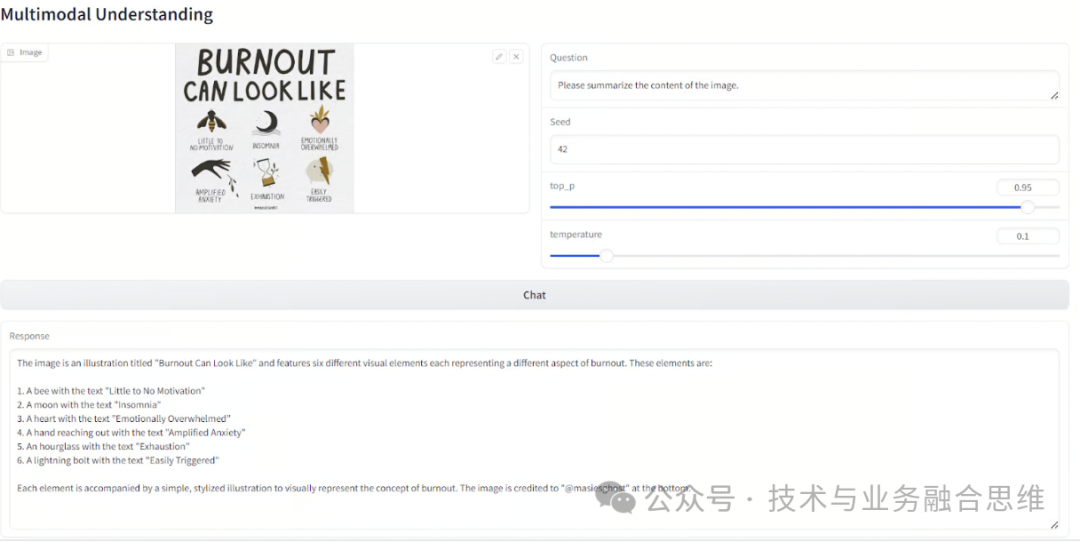
接下来,我们加载另一张图像并要求模型总结信息图的内容。该模型成功地理解了图像中的文本,并提供了高度准确和连贯的响应。这证明了该模型处理和解释视觉和文本元素的强大能力。
测试文本到图像的生成
向下滚动应用程序,您将找到 “Text-to-Image Generation” 部分。在这里,您可以输入您选择的提示,然后单击“生成图像”按钮。该模型将生成图像的五个变体,这可能需要几分钟才能完成。
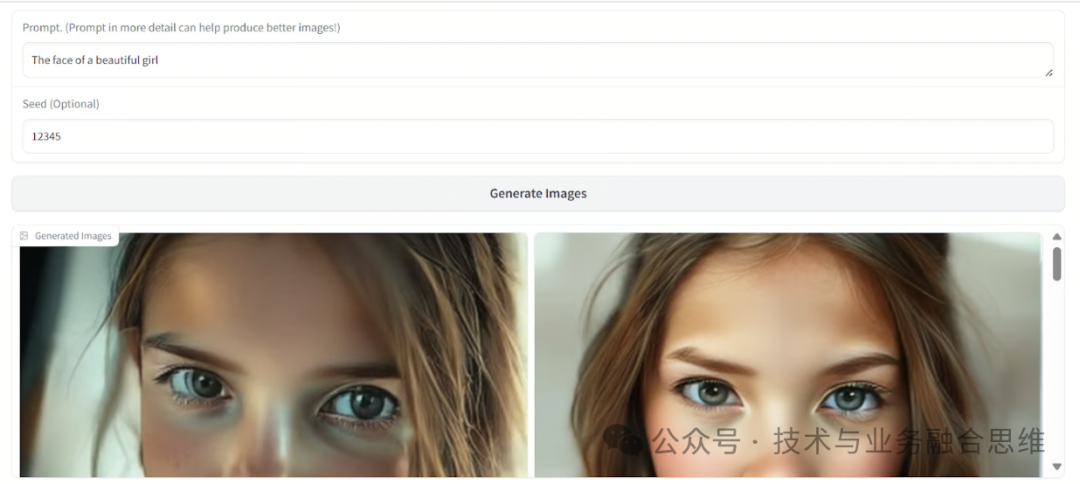
结果非常出色,产生的输出在质量和细节方面可与 Stable Diffusion XL 相媲美。
让我们尝试另一个提示:
Prompt: 提示:
“这幅图像的特点是一只设计复杂的眼睛,以圆形为背景,装饰着华丽的漩涡图案,唤起了现实主义和超现实主义。引人注目的是醒目的鲜艳蓝色虹膜,周围环绕着从瞳孔向外辐射的细腻静脉,营造出深度和强度。睫毛又长又黑,在周围的皮肤上投下微妙的阴影,看起来光滑但略带纹理,仿佛随着时间的推移而老化或风化。
眼睛上方是一个石头状的结构,类似于古典建筑的一部分,为构图增添了神秘和永恒的优雅。这种建筑元素与周围的有机曲线形成鲜明而和谐的对比。眼睛下方是另一个让人想起巴洛克艺术的装饰图案,进一步增强了每个精心制作的细节所蕴含的整体永恒感
总体而言,氛围散发着一种神秘的光环,与暗示永恒的元素无缝交织在一起,通过现实纹理和超现实艺术的并置实现。每个组件——从勾勒出眼睛的复杂设计到上方看起来古老的石头——都为创造一个充满神秘魅力的视觉迷人画面做出了独特的贡献。“
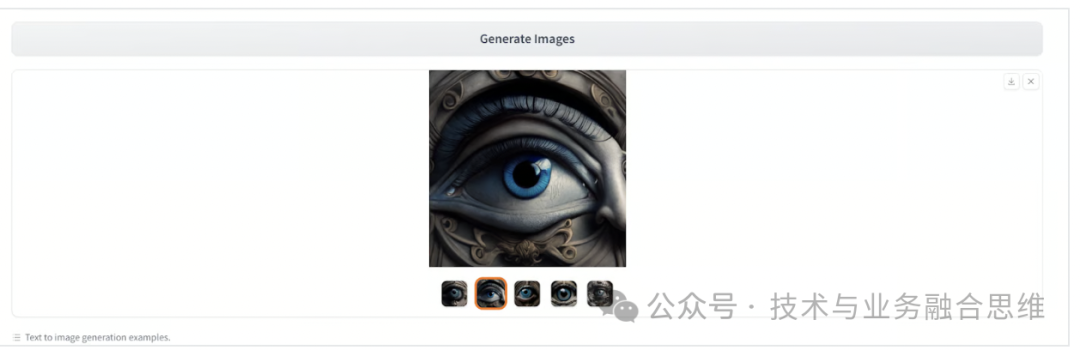
结果再次令人震惊。生成的图像捕捉了提示中描述的复杂细节和超现实艺术元素。
推荐阅读
2025 年最佳 AI 代理:工具、框架和平台比较-CSDN博客
什么是AI Agent