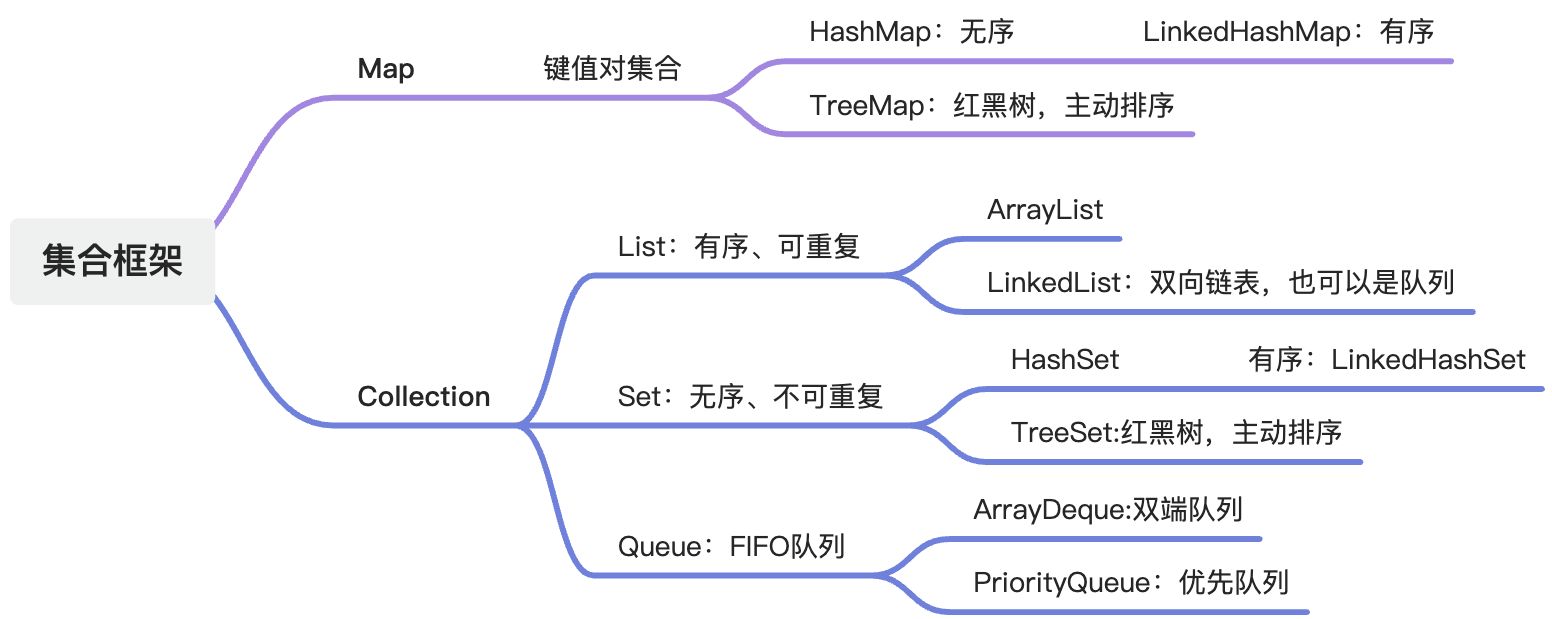
JAVA基础-集合框架
ArrayList常用方法及源码解释
- 有序,可重复集合
- 底层为数组结构,支持随机查询
- 实现了RandomAccess接口,支持索引下标随机访问
- 实现Cloneable接口,重写了clone方法,支持复制,但是clone仅到object[]层,数组内的引用类型没有被clone
- 由于ArrayList扩容机制的原因,不能使用默认的序列化方法,所以内部重写了
writeObject、readObject自动定义自定义序列化方法 - ArrayList内部维护
int modCount:
- 此变量用于使用迭代器遍历时候判断,集合是否被改变,如果改变抛出异常
- 所以ArrayList的所有会对集合元素变更的方法,都用先
modCount++ - 在后续的方法解释中就跳过,不在解释
- 扩容方法:
Object[] grow(int minCapacity)
- 判断是否是首次初始化
- 否:则是将需要新增的容量和原容量/2取最大值,作为新数组容量,返回新数组
- 是:则将插入的数据大小和10取最大值 作为新数组的容量,调用Arrays.copyof()辅助元素到新数组,返回新数组
- 向集合添加元素:
list.add(E);向数组的尾部添加一个元素
- 判断是否需要扩容:需要则调用grow进行扩容
- 将元素放在数据的尾端
- 返回true
list.add(int index ,E);在指定索引位添加元素
- 检查指定索引是否越界
- 判断是否需要扩容:需要则调用grow进行扩容
- 调用System.arraycopy()进行数组复制,将index之后的所有数组元素赋值到index+1之后的位置
- 将新元素放在index的位置
- 返回true
list.addAll(Collection c);向集合的末尾添加另一个集合list.addAll(int index,Collection c);在指定的索引位向集合中添加另一个集合
- 更新集合指定位置的元素:
E e = list.set(int index,E);
- 检查指定索引是否越界
- 获取index位置的oldValue
- 将新元素放在index的位置
- 返回oldValue
- 删除集合中的元素:
fastRemove(Object[] es, int i);
- 判断需要删除的索引为是否超出数组范围:否:则将需要删除的索引位之后的元素向前移动一位
- 将数据末尾设置为null
E e = list.remove(int);删除集合中指定索引位的元素
- 判断需要删除的索引是否越界
- 获取索引位上的oldValue
- 调用fastRemove删除指定索引位元素
- 返回oldValue
Boolean b = list.remove(Object);删除集合中相同元素的元素
- 找到object所对应的索引位,没找到返回false
- 调用fastRemove删除指定索引位元素
- 返回true
- 查找集合中的元素:
int index = list.indexof(Object);从前往后查找指定元素,返回元素的索引位int index = list.lastIndexof(Object);从后往前查找指定元素,返回元素的索引位E e = list.get(index);获取指定索引位的元素,index不能越界
- 二分查找:
@Test
public void test5() {//二分查找List<Integer> list = new ArrayList<>(Arrays.asList(10, 6, 8, 4, 5, 2, 7, 3, 9, 1));//正序list.sort((o1, o2) -> o1 - o2);System.out.println(list);int index = Collections.binarySearch(list, 5);System.out.println(index);//降序Comparator<Integer> comparator = new Comparator<>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}};list.sort(comparator);System.out.println(list);int i = Collections.binarySearch(list, 5, comparator);System.out.println(i);
}linkedList常用方法及源码解释
- 有序,可重复集合
- 底层基于双向链表,插入和删除效率高于ArrayList,并且无需扩容
- 实现了Cloneable接口,支持对象复制
- 同样重写了
writeObject、readObject自定义序列化方法,序列化时候,仅有item,没有next和prev,节省空间,在反序列化的时候,重新构建 - linkedList不但实现了List接口,还实现了Deque接口,所以具有集合的能力同时具有双端队列能力
transient int size = 0;//链表长度transient Node<E> first;//链表的首节点,首节点的first.prev = nulltransient Node<E> last;//链表的尾节点,尾节点的last.prev = nullprivate static class Node<E> {E item; //当前节点Node<E> next;//下一节点Node<E> prev;//上一节点Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}//同ArrayList相同,在使用迭代器的时候判断集合是否被修改,被修改的抛出异常
protected transient int modCount = 0;- 添加元素
private void linkFirst(E e);添加首节点
- 获取当前首节点first为f
- 创建新的Node节点,prev为null,item为e,next为f
- 将first指向新节点
- 如果f==null,则将last节点也指向新Node节点
- 反之,则原first节点的前驱节点设置为新Node节点
- size++
- modCount++
void linkLast(E e);添加尾节点
- 获取当前尾节点last为l
- 创建新的Node节点,prev为l,item为e,next为null
- 将last指向新Node
- 如果l==null,则将fist也指向当前新Node
- 反之则,l的next指向新Node
- size++
- modCount++
public boolean addAll(int index, Collection<? extends E> c);如果index<size ,则将新的集合添加到index之前,如果index == size 则将新集合添加在链表末尾
- 检查index是否超出链表范围
- 如果index == size,则插入位的前驱为last节点
- 如果index < size,则插入位的前驱为index节点的前驱,
- 利用循环将新集合插入链表
- 如果index == size,则last节点为新增集合的尾节点
- 如果index < size,则新增集合的尾节点后驱节点为index节点,idex节点的前驱节点为新增集合的尾节点
- size += newNum
- modCount++
public boolean addAll(Collection<? extends E> c);将新集合添加在链表末尾
- 调用addAll(size,c);
- 集合方法:
add、addFirst、addLast都是基于上述3个方法做了方法增强 - 入队列方法:
offer、offerFirst、offerLas基于上述集合方法做了方法增强 - 入栈方法:
push基于addFirst
- 集合方法:
- 删除元素:
E unlink(Node<E> x);移除链表的中元素
- 获取x的item、next、prev
- 如果prev==null,则说明为x为头结点,将first = next
- 反之,x非头节点,prev.next = next
- 如果next==null,则说明x为尾节点,将last = prev
- 反之,x非尾结点,next.prev = prev
- 将x节点的item、next、prev设置为null,解引用,方便GC,
- size--
- modCount++
private E unlinkFirst(Node<E> f);移除首节点
- 获取f节点的item、next
- 将first节点指向next
- 如果next==null,说明链表仅一个节点,则last=null
- 反之,next.prev=null
- size--
- modCount++
private E unlinkLast(Node<E> l);移除尾节点
- 获取l节点的item、prev
- 将last节点指向prev
- 如果prev==null,则first=null
- 反之则,prev.prev=null
- size--
- modCount++
- 集合方法:
remove、removeFirst、removeLast都基于上述的三个方法做了方法增强 - 出队方法:
poll、pollFirst、pollLast也都基于上述的三个方法做了方法增强 - 出栈方法:
pop基于removeFirst
- 集合方法:
- 修改元素:
public E set(int index, E element);将指定索引位的node.item设置为element
- 检查索引是否越界
- 获取index索引位的oldItem
- 将index索引位的item设置为element
- 返回oldItem
- 查询元素:
Node<E> node(int index);获取指定index位置的结点
- 判断index是否在链表的前半段:是则从首节点遍历到index的位置
- 否,则说明index在后半段,则从尾节点遍历到index的位置
- 返回index对应node
public E get(int index);基于node,返回node.itempublic E getFirst();返回fist.item,如果first==null,则抛异常public E getLast();返回last.item,如果last==null,则抛异常public E peek();返回first.item,如果first==null,则返回nullpublic E peekFirst();返回first.item,如果first==null,则返回nullpublic E peekLast();返回last.item,如果last==null,则返回null
HashMap的常用方法及源码解释
- 无序的键值对集合,支持null值,null键,键唯一
- 底层基于Node<K,V>[] tabel,
final Node<K,V>[] resize();扩容方法
- 计算新容量和新的扩容阈值:
- 未初始化,则新容量为16,扩容阈值为16*0.75
- 反之:如果数组容量大于2^30,则不在扩容,返回旧数组。反之新容量为oldCap*2,阈值为oldThr*2
- 使用新容量创建Node数组
- 迁移元素
final void treeify(Node<K,V>[] tab);将TreeNode链表转换为红黑树
- 遍历当前链表,获取链表节点
- 若树为空,则将第一节点设置为根节点
- 否则,根据节点Hash值和key的比较结果,找出插入的位置并插入节点
- 插入后通过调整树的结构以维持红黑树的平衡
- 最后确保根节点位于桶的最前面
final void treeifyBin(Node<K,V>[] tab, int hash);链表转红黑树
- 如果tab==null或者数组长度小于64,则调用
resize()方法扩容 - 反之:则循环桶的Node链表,转化为TreeNode链,然后调用
hd.treeify(tab)(hd:TreeNode的头节点),转换为红黑树
- 如果tab==null或者数组长度小于64,则调用
final TreeNode<K,V> putTreeVal(HashMap<K,V> map,Node<K,V>[] tab,int h,K k,V v);用于在红黑树插入键值对
- 从根节点开始遍历红黑树,确定元素要插入的位置
- 然后将新节点插入红黑树
- 最后确保根节点在桶的第一个节点
- 添加方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict);向键值对集合中插入元素,如果返回null,则元素无重复,反之,则元素重复被覆盖
- 检查map是否初始化,则调用
resize()方法初始化Node数组,并返回初始化后的数组长度,通常为16 - 如果通过
i=(n-1) & hash计算出桶的位置的node==null,则调用newNode(hash,key,value,null)创键新节点,然后i位置指向nowNode - 反之:
- 检查map是否初始化,则调用
- 如果i的位置的node.hash==hash并且node.key也等于key,则当前插入元素已存在,newNode指向node
- 反之如果i位置的node是TreeNode(红黑树),则调用
putTreeVal(this,tab,hash,value)返回newNode - 反之则循环i位置的node链表,调用
newNode(hash,key,value,null)在链表尾部添加新节点,同时判断是否8的阈值,调用treeifyBin(tab, hash)将链表转化为红黑树,超过如果链表存在相同值,则不创建newNode
- 如果重复插入,则新value覆盖,返回旧value
- ++modCount
- 判断是否需要扩容,需要则调用
resize()进行扩容 - 返回null
HashMap<String, String> map = new HashMap<>();map.put("1", "1");
map.put("2", "2");
// 有时只需要键
for (String key : map.keySet()) {System.out.println("Key: " + key);
}// 有时只需要值
for (String value : map.values()) {System.out.println("Value: " + value);
}// 有时需要键值对
for (Map.Entry<String, String> entry : map.entrySet()) {System.out.println(entry.getKey() + ":" + entry.getValue());
}
for(String key : map.keySet()){//效率低于map.entrySet()的遍历,// 因为每次调用get()方法都会重新计算hashCode(),而map.entrySet()的遍历中,hashCode()只计算一次System.out.println( key + ":" + map.get(key));
}LinkedHashMap的常用方法和源码解释
- 有序的键值对集合,支持null值null键,键唯一
- LinkedHashMap继承自HashMap,没有重写HashMap的put方法,仅重写了newNode方法
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}
}
//在每次调用put方法新建节点的时候,同时维护双向链表的顺序,保证插入顺序
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<>(hash, key, value, e);linkNodeLast(p);return p;
}
//双向链表头
transient LinkedHashMap.Entry<K,V> head;
//双向链表尾
transient LinkedHashMap.Entry<K,V> tail;
//false(默认):维持插入顺序模式
//true:访问顺序模式
final boolean accessOrder;
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;tail = p;if (last == null)head = p;else {p.before = last;last.after = p;}
}- 插入顺序模式(accessOrder=false):元素按照插入的顺序排列、每次访问元素不会改变顺序
- 用途:FIFO模式
@Test
public void test8() {LinkedHashMap<String, String> lm = new LinkedHashMap<>(16, 0.75f,false);lm.put("1", "1");lm.put("2", "2");lm.put("3", "3");lm.put("4", "4");lm.get("1");lm.get("2");System.out.println(lm.entrySet());
}[1=1, 2=2, 3=3, 4=4]
- 访问顺序模式(accessOrder=true):元素按照插入的顺序排列、每次访问的元素放在链表的尾部
- 用途:LRU模式
@Test
public void test9() {LinkedHashMap<String, String> lm = new LinkedHashMap<>(16, 0.75f,true);lm.put("1", "1");lm.put("2", "2");lm.put("3", "3");lm.put("4", "4");lm.get("1");lm.get("2");System.out.println(lm.entrySet());
}[3=3, 4=4, 1=1, 2=2]
- LinkedHashMap的三个回调函数:
void afterNodeAccess(Node<K,V> p) { }访问顺序模式调用,将p移动到链表尾部void afterNodeInsertion(boolean evict) { }在插入节点后调用,用于实现自动删除头节点,是否删除判断基于removeEldestEntry方法void afterNodeRemoval(Node<K,V> p) { }在删除节点后被调用,用于维护双向链表之间的关系
- afterNodeInsertion的实例
@Test
public void test9() {Map<String, String> mlm = new MyLinkedHashMap<>();mlm.put("1", "1");mlm.put("2", "2");mlm.put("3", "3");mlm.put("4", "4");mlm.put("5","5");System.out.println(mlm.entrySet());// [1=1, 2=2, 3=3, 4=4, 5=5]mlm.put("6","6");System.out.println(mlm.entrySet());// [2=2, 3=3, 4=4, 5=5, 6=6]mlm.put("7","7");System.out.println(mlm.entrySet());// [3=3, 4=4, 5=5, 6=6, 7=7]mlm.get("3");mlm.put("8","8");System.out.println(mlm.entrySet());// [5=5, 6=6, 7=7, 3=3, 8=8]
}class MyLinkedHashMap<K,V> extends LinkedHashMap<K,V>{private static final int MAX_LENGTH = 5;public MyLinkedHashMap (){super(16,0.75f,true);}//LRU@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > MAX_LENGTH;}}TreeMap实现原理解析
- 主动排序的键值对集合,支持null值,不支持null键
- 基于红黑树实现
private V put(K key, V value, boolean replaceOld);
- 判断根节点是否为空,空则创建根节点,然后返回null
- 反之,从根节点开始遍历,使用比较器判断节点在左子树,还是右子树,找到新节点的位置,插入,然后调用
fixAfterInsertion(e);修复红黑树
- 在使用TreeMap的时候,可以自定义比较器实现comparator接口,也可以使用元素自定义实现的coparable重写的compareTo方法这两种方式定义元素在TreeMap中的顺序
双端队列ArrayDeque
- 既可以作为栈使用,也可以作为队列使用
- 基于循环数组实现,默认初始化容量为17
- 和LinkeList相比性能更优
- 不支持null值
- 作为栈:入栈:push、出栈:pop
- 作为队列:入队:offer、出队:poll
private void grow(int needed);扩容
- 计算新的容量:如果小于64,则扩容200%+2,如果大于则扩容50%
- 新容量检查:如果新容量小于needed或者新容量超过
Integer.MAX_VALUE - 8则调用newCapacity(needed, jump)重新计算 - 数组复制
- 处理循环数组的特殊情况【
tail<head || (tail == head && es[head] != nul)】,然后重新排列元素:将旧数组从head位置到尾部的数据放在新数组的尾部,将原位置置为null
static final int dec(int i, int modulus);循环递减i,,同时防止越界static final int inc(int i, int modulus);循环递增i,同时防止越界public void addFirst(E e);push基于addFirst实现
- dec方法计算head下标,然后将元素添加head下标的位置
- 如果tail==head调用grow扩容
public E pollFirst();pop和poll基于pollFirst()实现
- 移除head下标对应的元素,然后调用inc重新计算head
- 返回旧元素
public void addLast(E e);offer基于addLast实现
- 将元素添加在tail小标的位置,然后调用inc重新计算tail
- 如果tail==head调用grow扩容
PriorityDueue优先级队列
- 主要作用:维护一组数组的排序,使得取出数据可以按照一定的优先级顺序进行
- 同样也需要维护一个比较器(Comparator,或者元素自身实现 Comparable 接口)
- 底层基于数组实现,通过堆的性质来维护元素的顺序
Comparator和Comparable的区别
- 如果一个类实现了Comparable接口,则需要重写compareTo方法定义排序规则
public interface Comparable<T> {
//返回值可能为负数,零或者正数,
//代表的意思是该对象按照排序的规则小于、等于或者大于要比较的对象public int compareTo(T o);
}- Comparator接口相比于Comparable接口相对复杂,核心方法有一个
public interface Comparator<T> {//返回值可能为负数,零或者正数//代表的意思是第一个对象小于、等于或者大于第二个对象。int compare(T o1, T o2);
}- 到底使用哪一个?
- 一个类实现了 Comparable 接口,意味着该类的对象可以直接进行比较(排序),但比较(排序)的 方式只有一种,很单一
- 一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现Comparator 接口)。