Linux线程学习
目录
- 线程跟进程的区别
- 线程控制
- 创建线程
- 获取线程自身ID
- 线程终止
- 通过reurn方式
- 通过exit()
- 通过pthread_exit函数
- 通过pthread_cancel函数
- 线程等待
- 线程分离
- 线程互斥
- 初始化互斥量,两种方法:
- 互斥量销毁
- 互斥量加锁和解锁
- 简单上手使用锁改进售票系统
- 线程缺点
前言: 我写的关于进程学习的文章
线程跟进程的区别
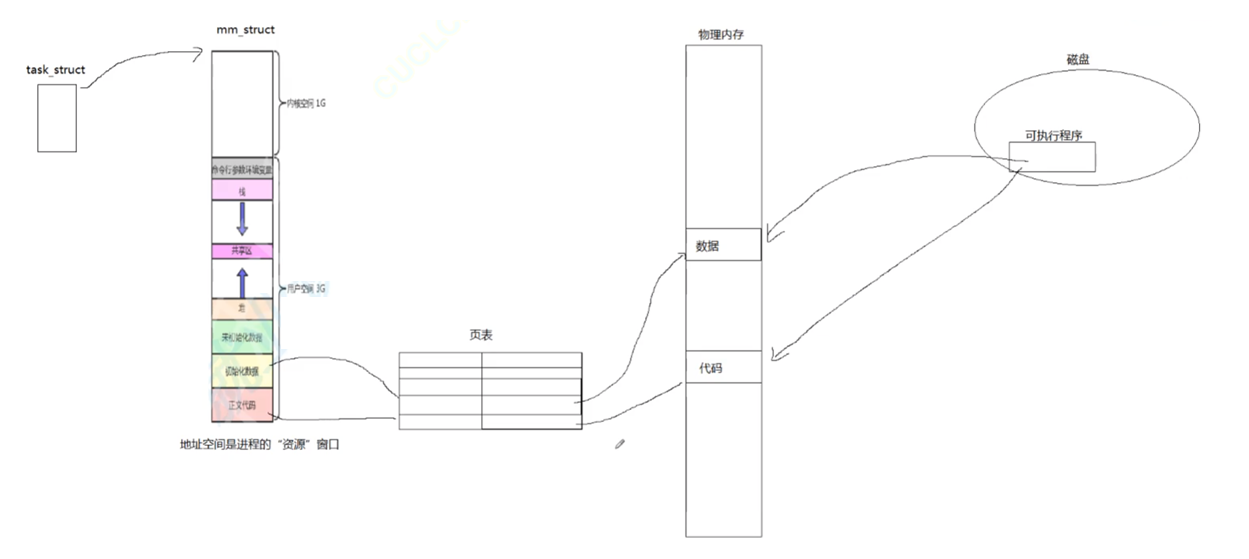
对于线程,要创建PCB,进程地址空间,页表,并且代码和数据要分开存放
能不能有一种更简便的方式呢?
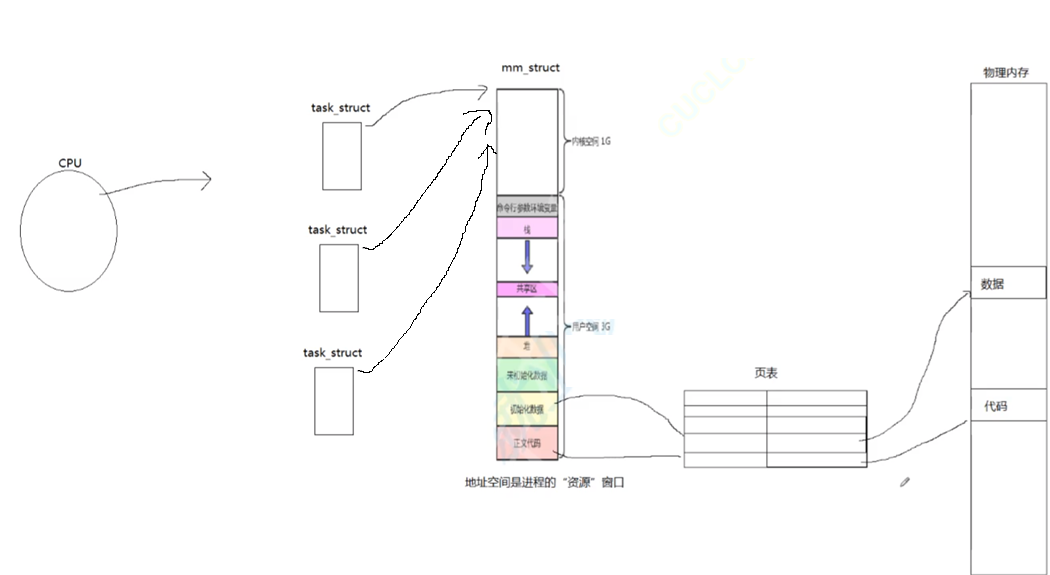
本质是两个指针指向同一个数据结构对象
那么可不可以通过技术手段把代码部分拆分成多份,比如有三个函数,之前是一个进程运行,现在三个“进程”一人跑一个,把堆区、栈区等想办法让三个“进程”共享,不该共享的分成每人各一份。
CPU执行时,只会执行一个进程的一部分代码,访问该进程的一部分数据,执行任务部分的一部分,这种比传统进程更轻的概念叫线程。
创建一个线程的成本只需要参与资源分配,不需要像进程一样创建各种结构,所以线程是比进程更轻量化的一种执行流
线程在进程的地址空间中运行,那么引出线程的另一个概念:线程是在进程内部执行的一种执行流
线程(TCB)与线程(PCB)所需要的属性(pid,优先级)都是差不多的,没必要再新建一个结构,那么那PCB充当TCB,就可以把调度需要的管理,算法,代码等复用。
操作系统对于线程的概念是:线程是比进程更轻量化的一种执行流
实际操作系统,对于线程,有不同的实现方法,只要满足了线程的概念,那么实现出来的就是线程
我们上面说的PCB充当TCB,就是Linux的实现方法
操作系统难学的原因也是在于,书本只给出了概念,却没有具体的执行方案,当有了一种执行方案,就便于理解了。
PCB充当TCB,那么CPU看到的只有PCB,怎么区分谁是进程,谁是线程?
不需要区分,就像快递员不会看你的快递,他的任务只是送快递
对于CPU来说,它的任务就是根据这个PCB,找到进程地址空间,进而找到对应的代码数据,执行即可。
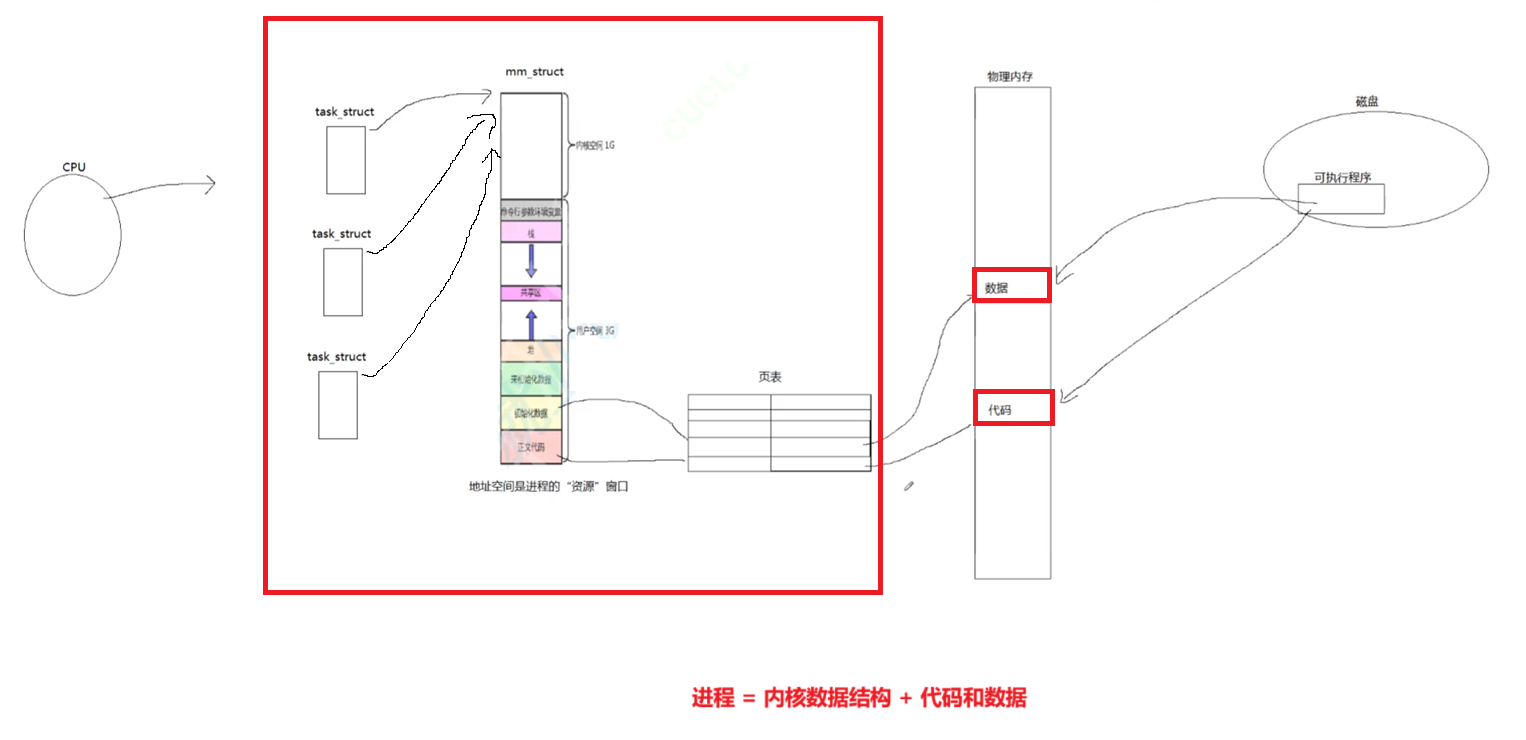
创建进程时,默认一份PCB,一份地址空间,一份页表,代码数据,统称为进程。
线程就不需要申请这么多资源,只需要创建新的PCB
概念:进程是承担系统资源的基本实体
系统每创建一个进程就分配系统的一部分资源,往后线程的创建只是分配进程内部的资源
对于在我进程的博客中,同样是进程=内核数据结构+代码数据,不过那是一个内部只有一个执行流的进程
而在今天线程的学习中,这个进程就可以说是内部有多个执行流的进程了
总结:左边大框就是进程,每一个PCB就是一个轻量级进程,也就是线程的概念——线程是CPU调度的基本单位
理解了线程和进程的区别,那么线程之间怎么区分?
看的是LWP,类似于PID,当LWP=PID,就意味着这是最先的线程

线程控制
创建线程
功能:创建一个新的线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *
(*start_routine)(void*), void *arg)
参数:thread:返回线程IDattr:设置线程的属性,attr为NULL表示使用默认属性start_routine:是个函数地址,线程启动后要执行的函数arg:传给线程启动函数的参数返回值:成功返回0;失败返回错误码
注意:pthread_ create函数会产生一个线程ID,存放在第一个参数指向的地址中。所以第一个参数thread是输出型参数。
pthread_t 其实只是一个无符号长整型

start_routine 函数是线程启动后要执行的函数,这个函数的返回值类型必须是 void* , 因为使用 void* 作为返回类型,可以让线程函数返回任意类型的数据(通过指针转换)
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>// 新线程
void *ThreadRoutine(void *arg)
{//const char *threadname = (const char *)arg;std:string name = static_cast<const char*>(arg);//类型转换while (true){std::cout << "new thread is running ,thread name:" << name << std::endl;sleep(1);}
}int main()
{// 已经有进程了pthread_t tid;pthread_create(&tid, nullptr, ThreadRoutine, (void *)"thread 1");// 主线程while (true)std::cout << "main thread,sub thread:" << tid<< std::endl;sleep(1);}return 0;
}
主线程能打印出新线程的id,那怎么打印出主线程的id?
再认识一个新函数
获取线程自身ID
功能:获得线程自身的ID
pthread_t pthread_self(void);
int main()
{// 已经有进程了pthread_t tid;pthread_create(&tid, nullptr, ThreadRoutine, (void *)"thread 1");// 主线程while (true)std::cout << "main thread,sub thread:" << tid<< "main thread id:" << pthread_self() << std::endl;sleep(1);}return 0;
}

如果换成16进制,显示各自的id

thread id本质其实是一个地址
线程终止
通过reurn方式
void *ThreadRoutine(void *arg)
{std:string name = static_cast<const char*>(arg);//类型转换while (true){std::cout << "new thread is running ,thread name:" << name << std::endl;sleep(1);}return nullptr;
}
通过exit()
注意这种方式不仅会终止该线程,其他线程也会被一起终止,所以也叫进程终止。
void *ThreadRoutine(void *arg)
{std:string name = static_cast<const char*>(arg);//类型转换while (true){std::cout << "new thread is running ,thread name:" << name << std::endl;sleep(1);}exit(5);
}
通过pthread_exit函数
功能:线程终止
void pthread_exit(void *value_ptr);参数:value_ptr:value_ptr不要指向一个局部变量。
返回值:无返回值,跟进程一样,线程结束的时候无法返回到它的调用者(自身)
void *ThreadRoutine(void *arg)
{std:string name = static_cast<const char*>(arg);//类型转换while (true){std::cout << "new thread is running ,thread name:" << name << std::endl;sleep(1);}pthread_exit(nullptr);
}
通过pthread_cancel函数
功能:取消一个执行中的线程
原型
int pthread_cancel(pthread_t thread);
参数
thread:线程ID
返回值:成功返回0;失败返回错误码
线程等待
线程退出,没有等待,会导致类似进程的僵尸问题
功能:等待线程结束
原型
int pthread_join(pthread_t thread, void **value_ptr);参数:thread:线程IDvalue_ptr:它指向一个指针,后者指向线程的返回值返回值:成功返回0;失败返回错误码
这种等待是阻塞等待
void *ThreadRoutine(void *arg)
{std:string name = static_cast<const char*>(arg);//类型转换while (true){std::cout << "new thread is running ,thread name:" << name << std::endl;sleep(1);}pthread_exit(10);
}
这是线程执行的函数,那么主线程等待完成后怎么拿到结束线程的退出信息?
主要依靠输出型参数 void **value_ptr

pthread_t tid;
pthread_create(&tid, nullptr, ThreadRoutine, (void *)"thread-1");void *ret = nullptr;
int n = pthread_join(tid, &ret);
std::cout << "main thread join done,"
<< " n: " << n << " thread return: " << (int64_t)ret << std::endl;
难道就不考虑线程出异常无法返回的情况吗?
是的,跟进程异常不同,进程之间是相互独立的。而线程一旦异常,主线程也得挂,所以就没必要接收异常信息,默认不会出异常。
线程分离
我们知道线程等待是阻塞等待,是要一直等的。
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
所以主线程不想等待时,就可以把线程设为分离状态,退出时自动释放资源。
int pthread_detach(pthread_t thread);
返回值为 0:这表明函数调用成功,线程已顺利设置为分离状态。
返回值为非零错误码:这意味着函数调用失败,常见的错误码有以下几种:EINVAL:传入的thread线程 ID 无效。ESRCH:找不到与thread对应的线程。EDEADLK:可能出现了死锁,例如尝试分离当前正在运行的线程。使用案例:
pthread_t tid;
pthread_create(&tid, nullptr, ThreadRoutine, (void *)"thread-1");pthread_detach(tid);
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());
线程互斥
// 操作共享变量会有问题的售票系统代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
void *route(void *arg)
{char *id = (char*)arg;while ( 1 ) {if ( ticket > 0 ) {usleep(1000);printf("%s sells ticket:%d\n", id, ticket);ticket--;} else {break;}}
}
int main( void )
{pthread_t t1, t2, t3, t4;pthread_create(&t1, NULL, route, "thread 1");pthread_create(&t2, NULL, route, "thread 2");pthread_create(&t3, NULL, route, "thread 3");pthread_create(&t4, NULL, route, "thread 4");pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);
}
一次执行结果:
thread 4 sells ticket:100
...
thread 4 sells ticket:1
thread 2 sells ticket:0
thread 1 sells ticket:-1
thread 3 sells ticket:-2
像tickets- -这样的操作,对应的汇编指令其实至少有三条:
- 读取数据
- 修改数据
- 写回数据
线程就有可能在执行if逻辑判断之后,还没有执行tickets- -之前就被切换下去了,而多个线程都出现这样的情况时,他们都被重新调度时,重新加载自己的上下文数据时,继续向后执行,但此时ticket已经为0,但线程不知道,它只知道要继续让tickets-1,于是多个线程这样做,就让ticket甚至减到了-2
当线程在执行一个对资源访问的操作时,要么做了这个操作,要么没有做这个操作,只要两种状态,不会出现做了一半这样的状态,我们称这样的操作是原子性的。
(就比如你妈让你写作业,要么给我把作业写完了再出去玩,要么就一个字也别写直接滚出门,就这两种状态,不会出现你写了一半,然后你妈让你出去玩的这种情况,这样的操作就是原子性的)
如果我们想让多个执行流串行的访问临界资源,而不是并发或并行的访问临界资源,这样的线程调度方案就是互斥式的访问临界资源!(串行就是指只要一个线程开始执行这个任务,那么他就不能中断,必须得等这个线程执行完这个任务,你才能切换其他线程执行其他的任务)
所以就有了锁的概念
加锁就意味着一个线程持有锁之后,不管是它被调度还是被切换走了,它都是带着锁的,只要它持有锁,其他线程无法运行临界资源,效率自然会比并行慢
Linux提供的锁叫互斥量。
初始化互斥量,两种方法:
方法1,静态分配:编译期初始化,通过宏定义直接赋值完成。
简单直接,无需手动销毁互斥量(程序退出时自动回收)。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
只能使用默认属性(普通锁、非递归、非进程共享),无法自定义互斥量属性(如递归锁、进程共享等)。
适用于简单场景,不需要特殊属性的互斥量。
方法2,动态分配:
需要手动销毁互斥量
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
参数:mutex:要初始化的互斥量attr:NULL
可通过第二个参数 attr 自定义互斥量属性(需配合 pthread_mutexattr_t 相关函数设置)。
例如:创建递归锁(允许同一线程多次加锁)、跨进程共享的锁(用于多进程同步)等。
灵活性更高,适用于复杂场景。
互斥量销毁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
- 使用 PTHREAD_ MUTEX_ INITIALIZER 初始化的互斥量不需要销毁
- 不要销毁一个已经加锁的互斥量
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁
互斥量加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:成功返回0,失败返回错误号
- 互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功
- 发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_mutex_lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁。
补充:
如果对一个临界区加锁之后,在临界区内部执行时允许线程切换
线程切换后,因为当前线程尚未释放锁,锁仍然被当前线程持有,其他线程只能等待线程执行完临界区后解锁,才能申请加锁。
简单上手使用锁改进售票系统
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include <sched.h>
int ticket = 100;
pthread_mutex_t mutex;void *route(void *arg)
{char *id = (char*)arg;while ( 1 ) {pthread_mutex_lock(&mutex);if ( ticket > 0 ) {usleep(1000);printf("%s sells ticket:%d\n", id, ticket);ticket--;pthread_mutex_unlock(&mutex);} else {pthread_mutex_unlock(&mutex);break;}}
}
int main( void )
{pthread_t t1, t2, t3, t4;pthread_mutex_init(&mutex, NULL);pthread_create(&t1, NULL, route, "thread 1");pthread_create(&t2, NULL, route, "thread 2");pthread_create(&t3, NULL, route, "thread 3");pthread_create(&t4, NULL, route, "thread 4");pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);pthread_mutex_destroy(&mutex);
}
pthread_mutex_t mutex 本质上是一个C语言风格的结构体(struct),它不是面向对象的类,没有成员函数,只能通过 pthread 库提供的函数(如 pthread_mutex_lock、pthread_mutex_unlock 等)操作。
pthread_mutex_t mutex 设置为全局变量而不是仅在 main 函数中定义是因为:
线程的入口函数 route 中需要调用 pthread_mutex_lock 和pthread_mutex_unlock 操作互斥锁
如果 mutex 仅在 main 函数中定义(局部变量),则 route 函数无法直接访问这个锁,导致无法实现线程同步。
如果想把mutex 放在main函数中,就需要pthread_create(&t1, NULL, route, &mutex); // 传递锁的地址,等繁琐些的操作
线程缺点
线程优点很多,但同时也是有缺点的
线程使用时需要小心,错误不好排查
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
进程的多个线程共享 同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
线程共享进程数据,但也拥有自己的一部分数据:
- 线程ID
- 一组寄存器
- 栈
- errno
- 信号屏蔽字
- 调度优先级
强调了解的是线程之间大部分共享,但也有自己独立的数据。
最重要的两点
因为线程是独立被调度的,所以每个线程都要有自己独立的上下文数据,比如进程切换时,会在寄存器产生大量的临时数据,寄存器只有一套,但每一个进程都有属于自己的上下文数据。体现了线程之间的动态切换。
无论是C还是C++,都伴随着大量的函数调用,调用就要形成栈帧形成临时变量,所以每个线程都要有自己独立的栈结构。体现了动态运行的概念。