分布式面经
cap理论
CAP定理:在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
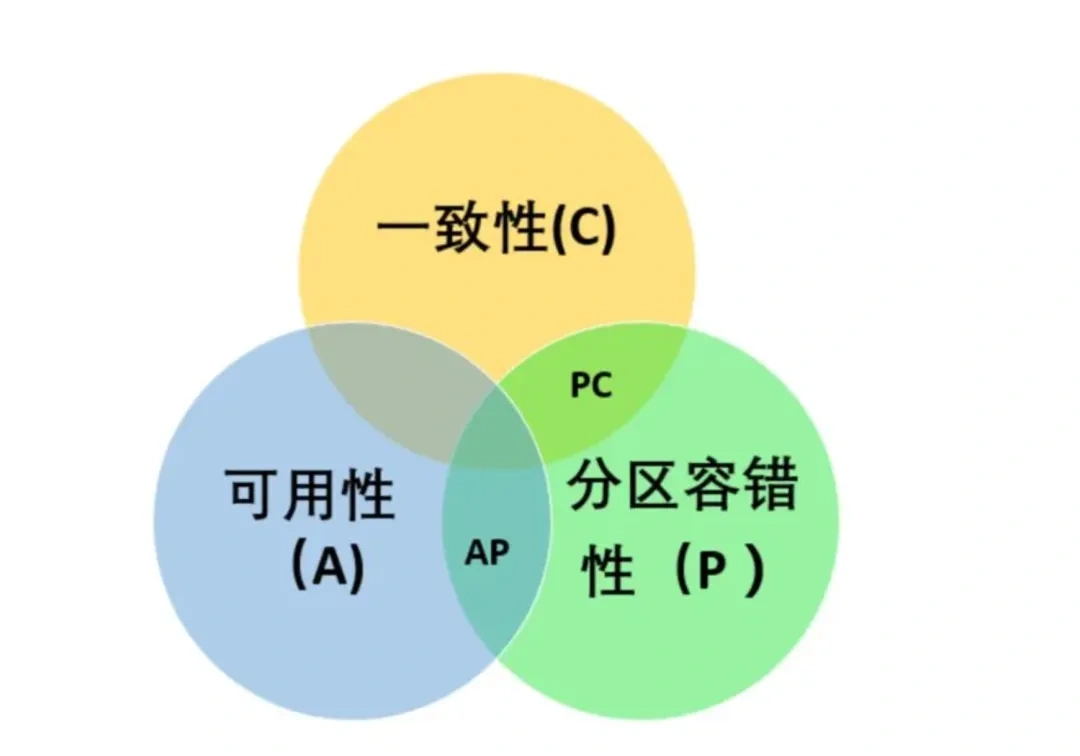
- 一致性(C):在分布式系统中的所有数据备份,在同一个时刻是否同样的值(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求(对数据更新具备高可用性)。
- 分区容错性(P):以实际效果而言,分区相当于对通信的时限要求,系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
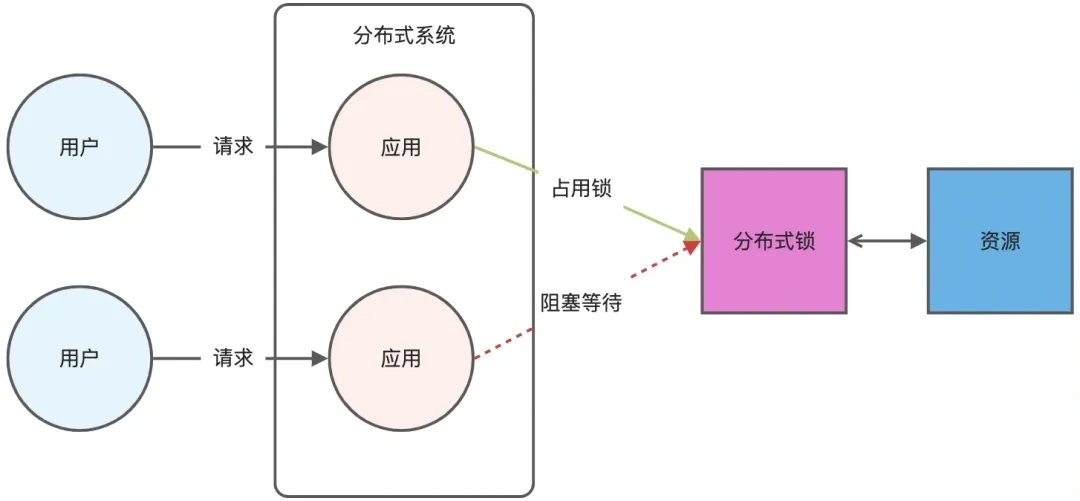
用redis怎么实现分布式锁?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。
Redis的SET命令中NX参数可以实现key不存在才插入,所以可以用它来实现分布式锁:
- 如果key不存在,则显示插入成功,可以用来表示加锁成功。
- 如果key存在,则显示插入失败,可以用来表示加锁失败。
基于Redis节点实现分布式锁时,对于加锁操作,需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,使用SET命令带上NX选项来实现加锁。
- 锁变量需要设置过期时间,以避免客户端拿到锁后发生异常,导致锁一直无法释放,所以,在SET命令执行时加上EX/PX选项,设置其过期时间。
- 锁变量的值需要能区分来自客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,使用SET命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端。
基于zookeeper实现分布式锁?
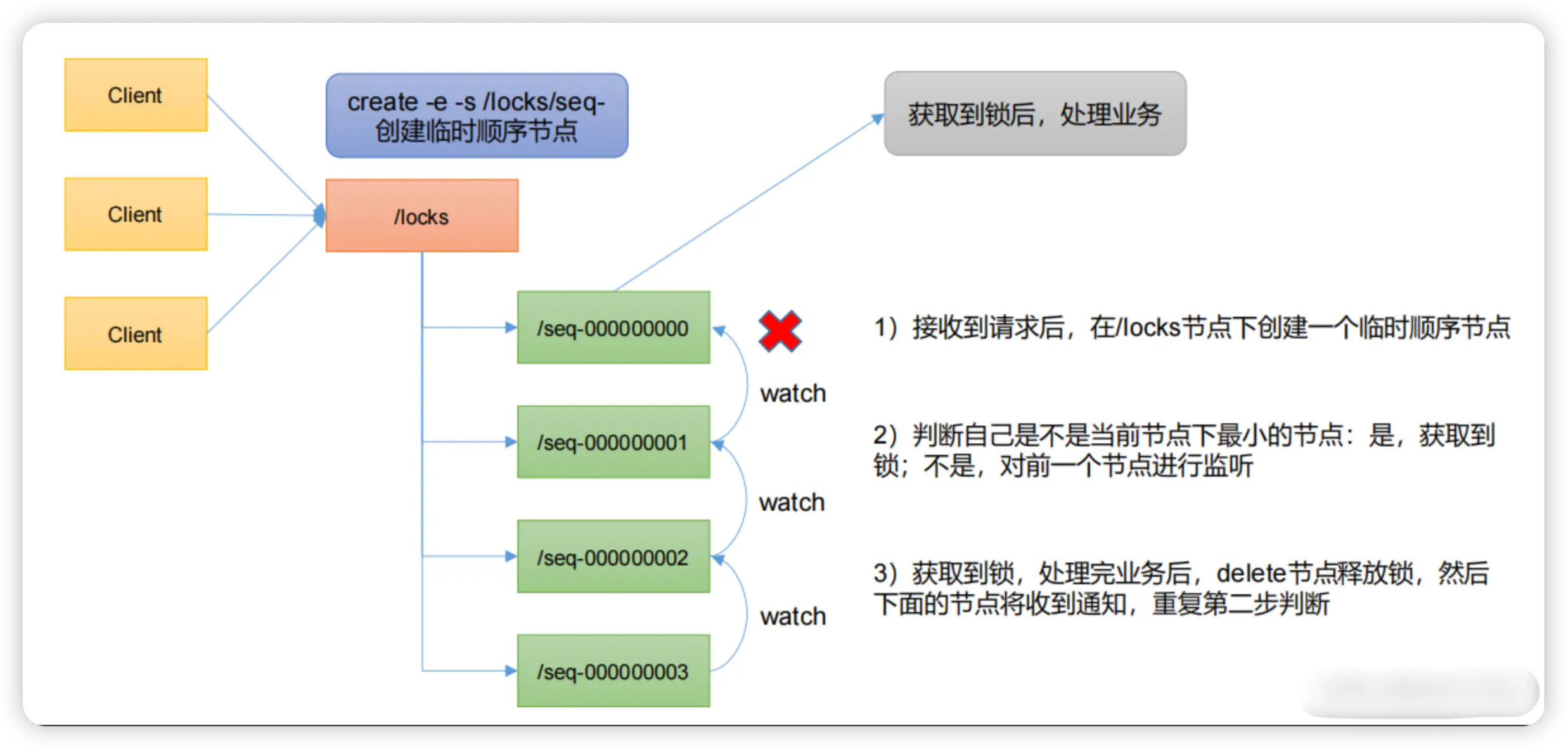
- 首先得有一个持久节点/locks,路径服务于某个使用场景,如果有多个使用场景建议路径不同。
- 请求进来时首先在/locks创建临时有序节点,所有会看到在/locks下面有seq-000000000,seq-00000001等节点。
- 然后判断当前创建的节点是不是/locks路径下面最小的节点,如果是,获取锁,不是,阻塞线程,同时设置监听器,监听前一个节点。
- 获取到锁以后,开始处理业务逻辑,最后delete当前节点,表示释放锁。
- 后一个节点就会收到通知,唤起线程,重复上面的判断。
zookeeper实现的分布式锁是强一致性的,因为它顶层的ZAB协议(原子广播协议),天然满足CP,但是这也意味着性能的下降。
分布式事务的解决方案
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 2PC | 强一致性 | 低 | 中 | 传统数据库、XA协议 |
| 3PC | 强一致性 | 中低 | 高 | 需减少阻塞的强一致场景 |
| TCC | 最终一致性 | 高 | 高 | 高并发业务(支付、库存) |
| Saga | 最终一致性 | 中 | 高 | 长事务、跨服务流程 |
| 消息队列 | 最终一致性 | 高 | 中 | 事件驱动架构 |
| 本地消息表 | 最终一致性 | 中 | 低 | 异步通知(订单 - 积分) |
| 协议名称 | 阶段划分/核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 两阶段提交协议(2PC) | 准备阶段:协调者发准备请求,参与者执行操作反馈结果;提交阶段:若全就绪,协调者发提交请求执行提交,否则发回滚请求 | 实现简单,保证事务强一致性 | 单点故障(协调者故障影响流程);性能低(多次消息交互增加延迟、资源锁致资源长时间占用,降低并发) | 对数据一致性要求高、并发度低场景,如金融系统转账业务 |
| 三阶段提交协议(3PC) | 在2PC基础上,准备阶段拆为询问阶段(协调者询问参与者能否执行事务 )和准备阶段,形成询问、准备、提交三个阶段,后续阶段同2PC | 降低参与者阻塞时间,提升并发性能;引入超时机制,一定程度解决单点故障问题 | 无法完全避免数据不一致,极端网络情况可能部分提交部分回滚 | 对并发性能有要求、对数据一致性要求相对较低场景 |
| TCC | 拆分为Try(预留业务资源)、Confirm(确认资源完成业务操作 )、Cancel(失败时释放资源回滚操作 )三个阶段 | 可按业务场景定制开发,性能较高,减少资源占用时间 | 开发成本高(需实现三个方法,处理异常和补偿逻辑,实现复杂度大) | 对性能要求高、业务逻辑复杂场景,如电商系统订单处理、库存管理 |
| Saga | 将长事务拆为多个短事务,每个短事务有对应补偿事务;某短事务失败,按相反顺序执行补偿事务回滚系统状态 | 性能较高(短事务可并行执行减少时间 );对业务侵入性小(只需实现补偿事务 ) | 只能保证最终一致性,部分补偿事务失败可能致系统状态不一致 | 业务流程长、对数据一致性要求为最终一致性场景,如旅游系统订单、航班、酒店预订 |
| 可靠消息最终一致性方案 | 基于消息队列,业务系统执行本地事务时将业务操作封装成消息发至消息队列,下游系统消费消息并执行操作 | 实现简单,对业务代码修改小,系统耦合度低,能保证数据最终一致性 | 消息队列可靠性和性能影响大,可能出现消息丢失或延迟,需处理消息幂等性 | 对数据一致性要求为最终一致性、系统耦合度低场景,如电商订单支付、库存扣减 |
| 本地消息表 | 业务与消息存储在同一数据库,利用本地事务保证一致性,后台任务轮询消息表,通过MQ通知下游服务,下游服务消费成功确认消息,失败则重试 | 简单可靠,无外部依赖 | 消息可能重复消费,需幂等设计 | 异步最终一致场景,如订单创建后通知积分服务 |
RPC的概念
RPC即远程过程调用,允许程序调用运行在另一台计算机上的程序中的过程或函数,就像调用本地程序中的过程或函数一样,而无需了解底层网络细节。
一个典型的RPC调用过程通常包含一下几个步骤:
- 客户端调用:客户端程序调用本地的一个伪函数(也称为存根,stub),并传入所需的参数,这个伪函数看起来和普通的本地函数一样,但实际上它会负责处理远程调用的相关事宜。
- 请求发送:客户端存根将调用信息(包括函数名、参数等)进行序列化,然后通过网络将请求发送到服务器端。
- 服务器接收于处理:服务器接收到请求后,将请求信息进行反序列化,然后找到对应的函数并执行。
- 结果返回:服务器端将函数的执行结果进行序列化,通过网络发送回客户端。
- 客户端接收结果:客户端接收到服务器返回的结果后,将其反序列化,并将结果返回给调用者。
zookeeper
zookeeper是分布式协调服务,它能很好地支持集群部署,并且具有很好地分布式协调能力,可以让我们在分布式部署的应用之间传递数据,保证顺序一致性(全序广播)而不是强一致性。
- 配置管理:zookeeper可以将配置信息集中存储,当配置发生变更时,能及时通知到各个节点。
- 服务注册与发现:服务提供者在启动时将自己的服务信息注册到zookeeper中,服务消费者通过zookeeper查找并获取服务提供者的信息。当服务提供者发生变化时,zookeeper会实时更新服务列表并通知服务消费者。
- 分布式锁:zookeeper可以通过创建临时顺序节点实现分布式锁。当一个客户端需要获取锁时,它会在zookeeper中创建一个临时顺序节点,然后检查自己创建的节点是否是序号最小的节点,如果是,则表示获取到了锁;如果不是,则等待前一个节点释放锁。
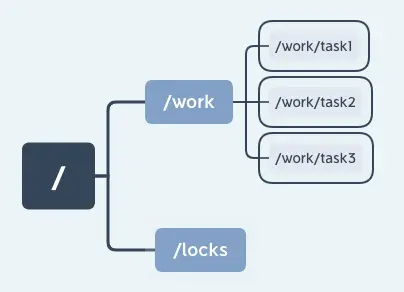
每个 Znode 可以存储数据,也可以有子节点。Znode 有不同的类型,包括持久节点(PERSISTENT)、临时节点(EPHEMERAL)和顺序节点(SEQUENTIAL)。
- 持久节点:一旦创建,除非主动删除,否则会一直存在。
- 临时节点:与客户端会话绑定,当客户端会话结束时,临时节点会自动被删除。
- 顺序节点:在创建时,ZooKeeper 会为其名称添加一个单调递增的序号,保证节点创建的顺序性。
ZooKeeper 使用 ZAB 协议来保证集群中数据的一致性。ZAB 协议基于主从架构,有一个领导者(Leader)和多个跟随者(Follower)。
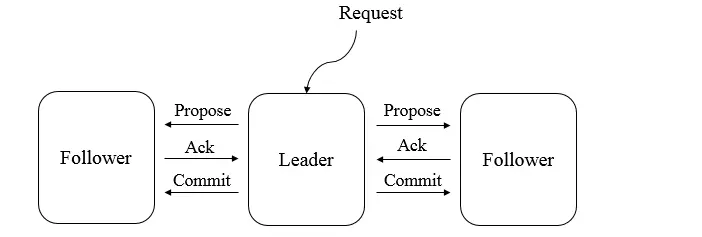
- 消息广播:当客户端发起写请求时,请求先会到达领导者。领导者将写操作封装成一个事务提案,并广播给所有跟随者。跟随者收到提案后,将其写入本地日志,并向领导者发送确认消息。当领导者收到超过半数跟随者的确认消息后,会发送提交消息给所有跟随者,跟随者收到提交消息后,将事务应用到本地状态机。
- 崩溃恢复:当领导者出现故障时,ZooKeeper会进入崩溃恢复阶段。在这个阶段,集群会选举出新的领导者,并确保在新领导者产生之前,不会处理新的写请求。选举过程基于节点的事务ID和节点ID等信息,保证新选举出的领导者包含了所有已提交的事务。
限流算法
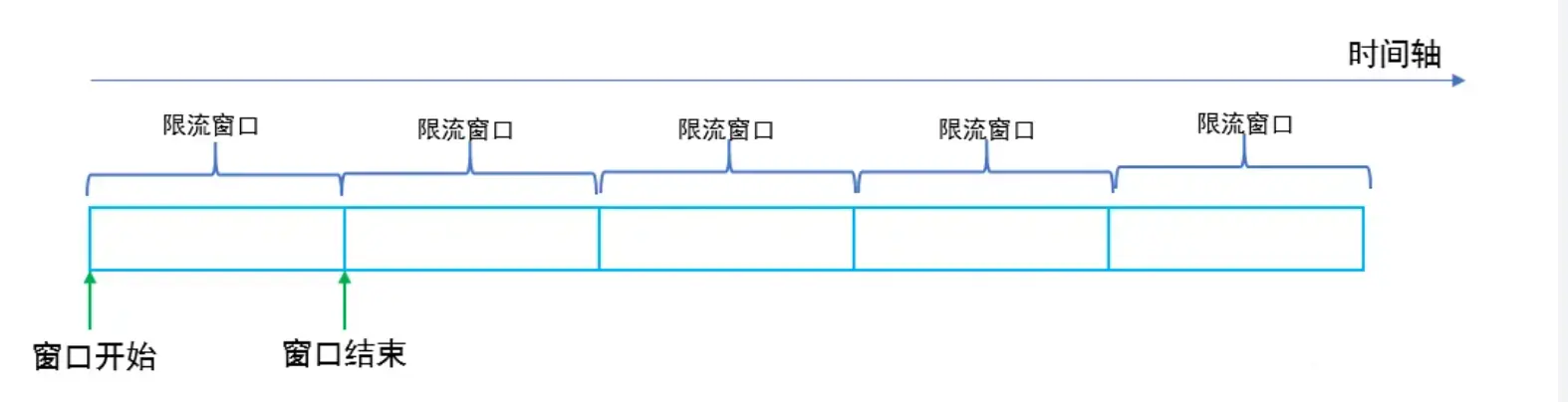
固定窗口限流算法
固定窗口限流算法就是对一段固定时间窗口内的请求进行计数,如果请求数超过了阈值,则舍弃该请求;如果没有达到设定的阈值,则接收该请求,且计数加1.当窗口结束时,重置计数器为0。
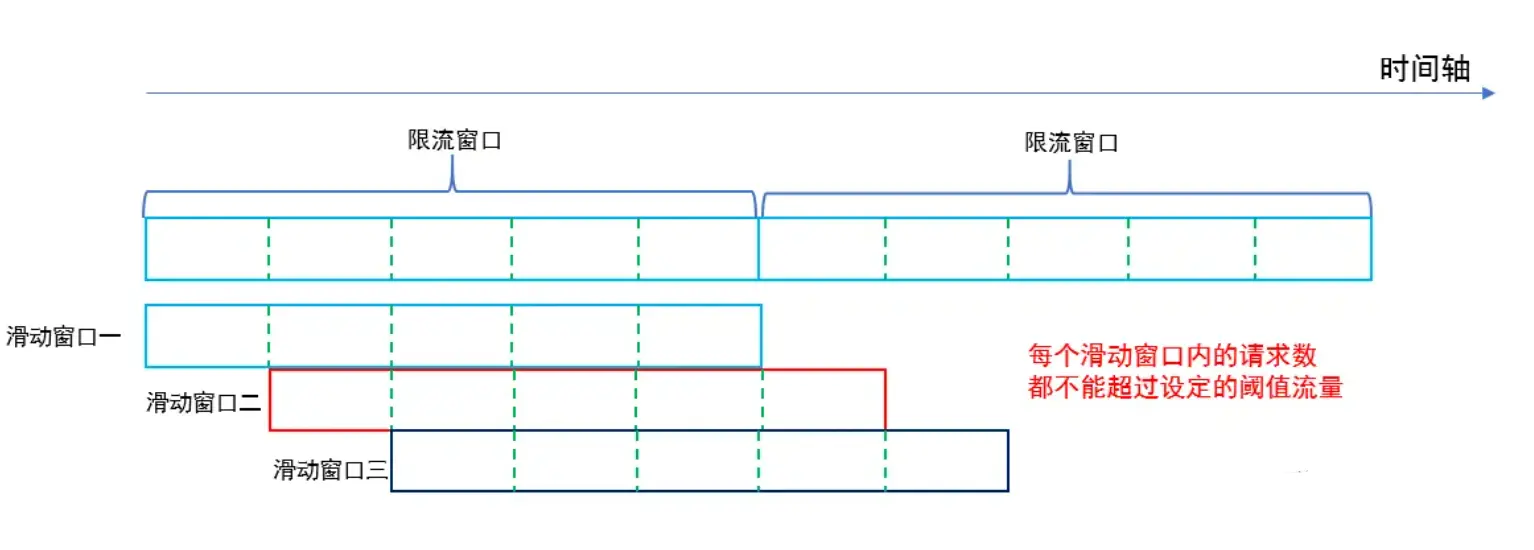
滑动窗口限流算法
将限流窗口内部切分成一些更小的时间片,然后在时间轴上滑动,每次滑动,滑动一个小时间片,就形成一个新的限流窗口,即滑动窗口。然后在这个滑动窗口内执行固定窗口算法即可。
滑动窗口可以避免固定窗口出现的两倍请求问题,因为一个短时间内出现的所有请求必然在一个滑动窗口中。
漏桶限流算法
加了一层漏斗算法限流后,就能够保证请求以恒定的速率流出。在系统看来,请求永远是以平滑的传输速率过来,从而起到了保护系统的作用。

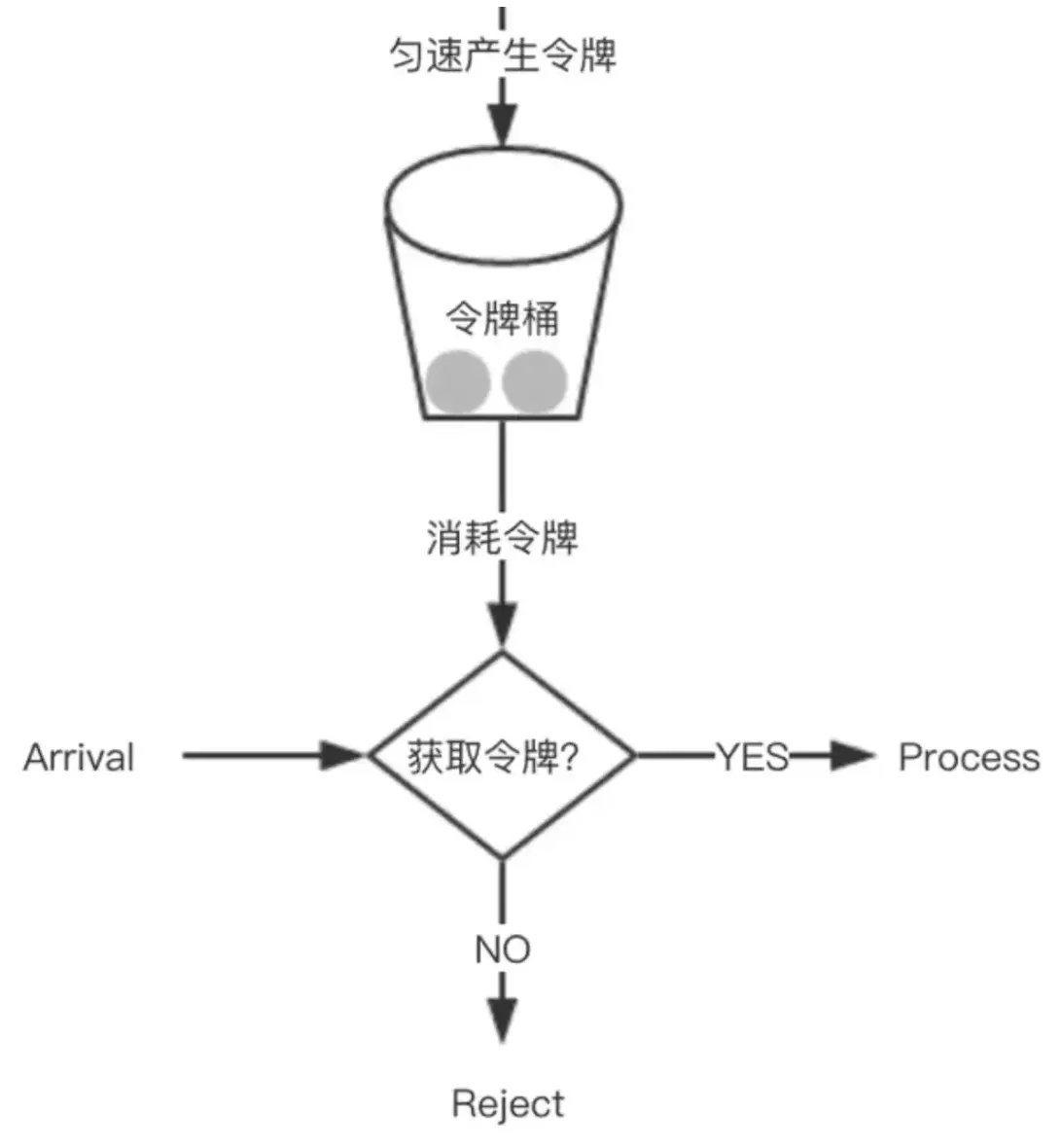
令牌桶限流算法
模拟一个特定大小的桶,然后向桶中以特定速度放入令牌(token),请求到达后,必须从桶中取出一个令牌才能继续处理。如果桶中没有令牌了,那么请求就被限流。如果桶中的令牌放满了,令牌桶也会溢出。