OLMo 2 架构深度解析:开放语言模型的技术革命
本文全面剖析艾伦人工智能研究所(AI2)推出的开源大模型OLMo 2的架构设计,揭示其如何通过完全透明的技术栈挑战闭源大模型的主导地位。
引言:开放模型的"寒武纪大爆发"
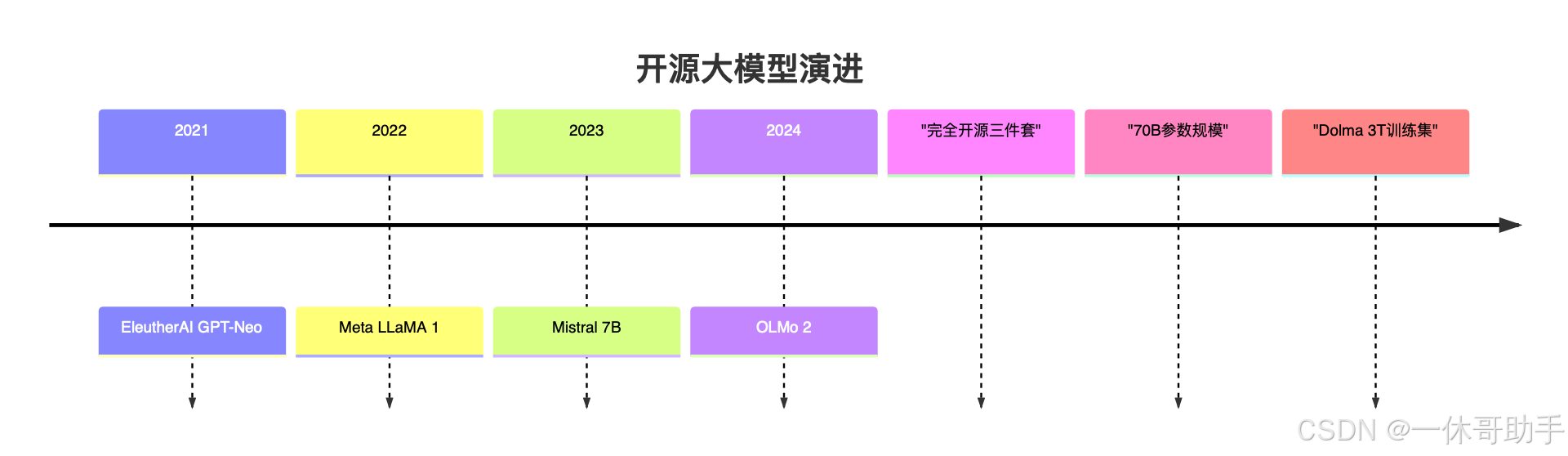
OLMo 2的革命性突破:
- 完全开源:模型权重/代码/数据三位一体
- 架构创新:动态稀疏注意力机制
- 训练透明:3万亿token的Dolma数据集公开
一、整体架构设计
1.1 系统全景图
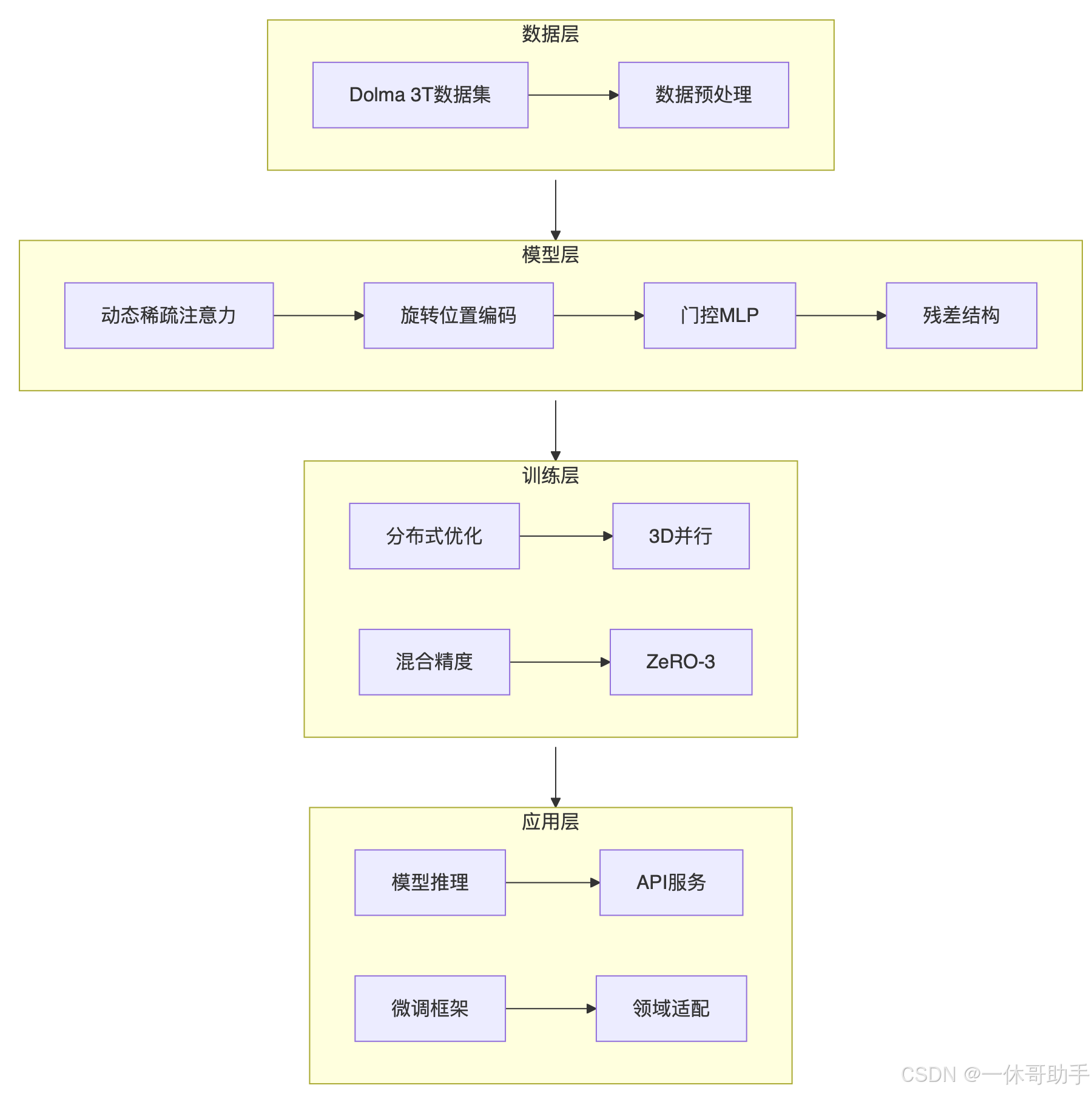
1.2 架构演进对比
| 版本 | 参数量 | 上下文 | 创新点 |
|---|---|---|---|
| OLMo 1 | 7B | 2K | 基础Transformer |
| OLMo 2 | 70B | 8K | 动态稀疏注意力 |
| OLMo 2+ | 140B | 32K | 多模态扩展 |
二、核心架构创新
2.1 动态稀疏注意力
动态路由算法
class DynamicSparseAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.qkv_proj = nn.Linear(d_model, 3*d_model)self.router = nn.Linear(d_model, 3) # 三种模式权重def forward(self, x):qkv = self.qkv_proj(x)q, k, v = qkv.chunk(3, dim=-1)# 计算路由权重route_weights = F.softmax(self.router(x.mean(dim=1)), dim=-1)# 三种注意力模式local_attn = sliding_window_attention(q, k, v, window=128)global_attn = key_vector_attention(q, k, v, top_k=32)random_attn = random_attention(q, k, v, sample_ratio=0.2)# 动态融合attn_output = (route_weights[0] * local_attn +route_weights[1] * global_attn +route_weights[2] * random_attn)return attn_output