数据结构---循环队列(补充 应用实例)、哈希表(哈希存储、哈希冲突、解决方法、举例实现)
循环队列
1、函数封装部分
1)创建循环队列
/*创建循环队列*/
Seqque_t *create_seqque()
{Seqque_t *psq = malloc(sizeof(Seqque_t));if (NULL == psq){printf("malloc error\n");return NULL;}psq->head = 0;psq->tail = 0;psq->pbase = malloc(sizeof(Data_type_t) * SEQQUE_MAX_LEN);if (NULL == psq->pbase){printf("malloc error\n");return NULL;}return psq;
}2)循环队列---判满、判空
/*判满*/
int is_full_seqque(Seqque_t *psq)
{if ((psq->tail+1)%SEQQUE_MAX_LEN == psq->head){return 1;}return 0;
}
/*判空*/
int is_empty_seqque(Seqque_t *psq)
{if (psq->head == psq->tail){return 1;}return 0;
}3)循环队列---插入数据
/*数据插入*/
int push_seqque(Seqque_t *psq, Data_type_t data)
{if (is_full_seqque(psq)){printf("seqque is full\n");return -1;}psq->pbase[psq->tail] = data;psq->tail = (psq->tail+1) % SEQQUE_MAX_LEN;return 0;
}4)循环队列---遍历
/*遍历*/
void seqque_for_each(Seqque_t *psq)
{for (int i = psq->head; i != psq->tail; i = (i+1)%SEQQUE_MAX_LEN){printf("%d ", psq->pbase[i]);}printf("\n");
}5)循环队列---删除数据
/*删除*/
int pop_seqque(Seqque_t *psq)
{if(is_empty_seqque(psq)) {printf("seqque is empty!");return -1;}int ret = psq -> pbase[psq -> head];psq -> head = ( psq -> head + 1 ) % SEQQUE_MAX_LEN;return ret;
}6)循环队列---获取头数据
/*获取头数据*/
int get_seqque(Seqque_t *psq, Data_type_t *data)
{if(is_empty_seqque(psq)){return -1;}if(psq->pbase == NULL){return -1;}*data = psq -> pbase[psq -> head];return 0;
}7)循环队列---销毁
/*销毁*/
void destroy_seqque(Seqque_t **ppsq)
{free((*ppsq) -> pbase);free(*ppsq);*ppsq = NULL;
}
上述封装函数需包含的头文件
#include "seqque.h"
#include <stdio.h>
#include <stdlib.h>2、声明部分(头文件)
#ifndef __SEQQUE_H__
#define __SEQQUE_H__#define SEQQUE_MAX_LEN 10typedef int Data_type_t;typedef struct seqque
{Data_type_t *pbase;int head;int tail;
}Seqque_t;extern Seqque_t *create_seqque();
extern int is_full_seqque(Seqque_t *psq);
extern int is_empty_seqque(Seqque_t *psq);
extern int push_seqque(Seqque_t *psq, Data_type_t data);
extern void seqque_for_each(Seqque_t *psq);
extern int pop_seqque(Seqque_t *psq);
extern int get_seqque(Seqque_t *psq, Data_type_t *data);
extern void destroy_seqque(Seqque_t **ppsq);#endif3、主函数运行格式
#include <stdio.h>
#include "seqque.h"int main(void)
{Seqque_t *psq = create_seqque();if (NULL == psq){return -1;}for (int i = 0; i < 10; i++){push_seqque(psq, i);}seqque_for_each(psq);int t = pop_seqque(psq);if(t != -1){printf("出队元素:%d\n", t);}//push_seqque(psq, 11);push_seqque(psq, 12);seqque_for_each(psq);Data_type_t data;t = get_seqque(psq, &data);if(t == 0){printf("%d\n", data);}destroy_seqque(&psq);return 0;
}哈希表(散列表)
哈希表(散列表)用来提高数据的查找效率。
1、哈希存储
1)概念
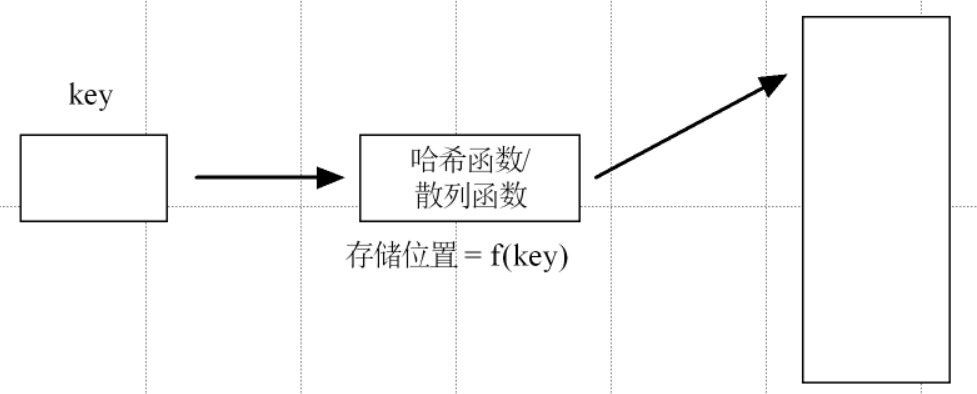
将要存储的数据的关键字和存储位置之间,建立起对应的关系,这个关系称之为哈希函数。存储数据时,通过对应的哈希函数可以将数据映射到指定的存储位置;查找时,仍可通过该函数找到数据的存储位置。
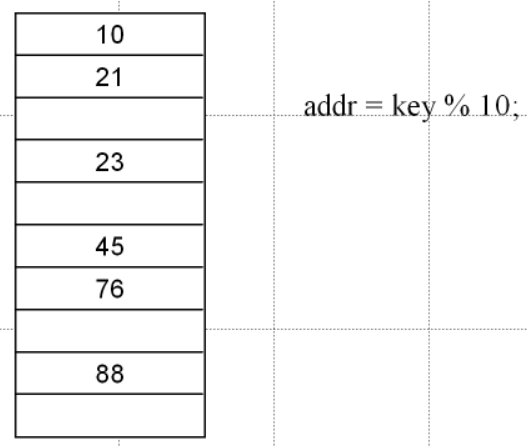
例如,对于存储 “ 21,45,76,88,10,23 ” 几个数字,可以通过关系式 “ key % 10 ” 来存储他们的地址,如下图:
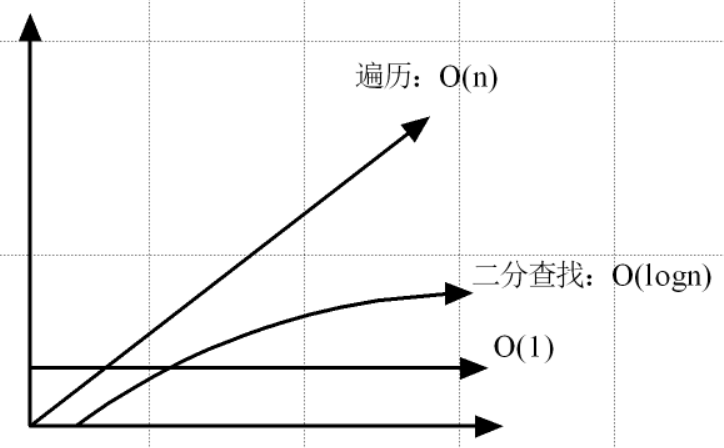
2)时间复杂度
遍历(O(n))、二分查找(O(logn)以2为底n的对数)、哈希表( O(1) ) 。
3)结构图
2、哈希冲突 / 哈希矛盾
1)概念
哈希冲突是指两个不同的关键字(键值)经过哈希函数计算后,得到了相同的哈希地址,使不同的关键字被映射到同一地址,导致多个关键字争夺同一个哈希地址,如果不能妥善处理,会使哈希表的查询、插入效率大幅降低(最坏的情况下可能退化为线性查找)。
2)解决方法
(1) 开放地址法
当两个不同的键通过哈希函数计算得到相同的哈希地址,开放地址法会在哈希表中寻找其他空闲位置来存储冲突的键值。存储的是数据。
基本思路:通过哈希函数计算初始地址后,若该地址已被占用(发生冲突),按照探测序列规则依次检查哈希表中的其他地址,直至找到一个空闲位置并插入,如找到空间底部也没有空闲位置,则从头开始查找。
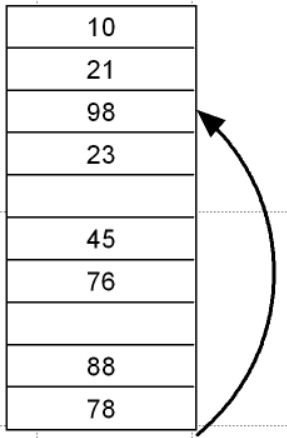
(2) 链地址法
当不同的键值通过哈希函数计算出相同的哈希地址,链地址法会将这些冲突的键值对存储在同一个哈希地址对应的链表(或其他链式结构)。存储的是地址。
基本思路:哈希表的每层是一个数组,每个数组元素对应链表的头结点,插入键值对时,先通过哈希函数计算哈希地址,找到对应的链表头结点,若该头结点对应的链表为空,则直接插入键值,若不为空(发生冲突),则将键值对添加到链表的末尾或头部;查找和删除时,先通过哈希函数定位头结点,再遍历该链表,找到目标键值进行操作。
优点:a. 删除操作简单:直接从链表中移除对应结点,无需特殊标志;
b. 不会产生“ 聚集效应 ”:冲突仅影响单个链表;
c. 链表可以动态增长,对表容量敏感度低。
缺点:a. 额外空间开销大:需要存储链表指针,内存利用率略低与开放地址法;
b. 若链表过长,查找效率会降低:最坏的情况会退化为 O(n)。
3)链地址法的举例实现
A. 函数封装部分
(1) 链地址法---设计哈希函数的封装
/*设计哈希函数*/
int hash_function(char key)
{if (key >= 'a' && key <= 'z'){return key-'a';}else if (key >= 'A' && key <= 'Z'){return key-'A';}else{return HASH_TABLE_MAX_SIZE-1;}
}(2) 链地址法---插入数据函数的封装
/*插入数据*/
int insert_hash_table(HSNode_t **hash_table, Data_type_t data)
{int addr = hash_function(data.name[0]);//hash_table[addr]; //---->pheadHSNode_t *pnode = malloc(sizeof(HSNode_t));if(NULL == pnode){printf("malloc error!");}pnode -> data = data;pnode -> pnext = NULL;if(NULL == hash_table[addr]){hash_table[addr] = pnode;}else{if(strcmp(pnode -> data.name, hash_table[addr] -> data.name) <= 0){pnode -> pnext = hash_table[addr];hash_table[addr] = pnode;}else{HSNode_t *p = hash_table[addr];while(p -> pnext != NULL && strcmp(p -> pnext -> data.name, pnode -> data.name) < 0){ p = p -> pnext;}pnode -> pnext = p -> pnext;p -> pnext = pnode;}}return 0;
}
(3) 链地址法---遍历函数的封装
/*遍历*/
void hash_for_each(HSNode_t **hash_table)
{int i;for(i = 0; i < HASH_TABLE_MAX_SIZE; ++i){HSNode_t *ptmp = hash_table[i];while(ptmp != NULL){printf("%s %s\n", ptmp -> data.name, ptmp -> data.tel);ptmp = ptmp -> pnext; }printf("\n");}
}(4) 链地址法---查找数据函数的封装
/*查找数据*/
HSNode_t *find_hash(HSNode_t **hash_table, char *name)
{int addr = hash_function(name[0]);HSNode_t *ptmp = hash_table[addr];while(ptmp != NULL){if(strcmp(name, ptmp -> data.name) == 0){return ptmp;}ptmp = ptmp -> pnext;}return NULL;
}(5) 链地址法---销毁函数的封装
/*销毁*/
void destory_hash(HSNode_t **hash_table)
{int i;for(i =0; i < HASH_TABLE_MAX_SIZE; ++i){HSNode_t *ptmp = hash_table[i];while(hash_table[i] != NULL){hash_table[i] = ptmp -> pnext;free(ptmp);ptmp = hash_table[i];} }
}
上述函数封装时所用到的头文件
#include "hash.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>B. 声明部分(头文件)
#ifndef __HASH_H__
#define __HASH_H__#define HASH_TABLE_MAX_SIZE 27typedef struct per
{char name[32];char tel[32];
}Data_type_t;typedef struct node
{Data_type_t data;struct node *pnext;
}HSNode_t;extern int insert_hash_table(HSNode_t **hash_table, Data_type_t data);
extern void hash_for_each(HSNode_t **hash_table);
extern HSNode_t *find_hash(HSNode_t **hash_table, char *name);
extern void destory_hash(HSNode_t **hash_table);
#endifC. 主函数运行格式
#include <stdio.h>
#include "hash.h"int main(void)
{Data_type_t pers[5] = {{"zhangsan", "110"}, {"lisi", "120"},{"wanger", "119"}, {"Zhaowu", "122"},{"maliu", "10086"}};HSNode_t *hash_table[HASH_TABLE_MAX_SIZE] = {NULL}; insert_hash_table(hash_table, pers[0]);insert_hash_table(hash_table, pers[1]);insert_hash_table(hash_table, pers[2]);insert_hash_table(hash_table, pers[3]);insert_hash_table(hash_table, pers[4]);hash_for_each(hash_table);HSNode_t *ret = find_hash(hash_table, "zhangsan");if(ret == NULL){return -1;}else{printf("%s %s\n", ret -> data.name, ret ->data.tel);}destory_hash(hash_table);return 0;
}【END】