【Kafka系列】第二篇| Kafka 的核心概念、架构设计、底层原理
在大数据和分布式系统飞速发展的今天,消息队列作为高效的通信工具,在系统解耦、异步通信、流量削峰等方面作用显著。
而 Kafka 这款高性能、高吞吐量的分布式消息队列,在日志收集、数据传输、实时计算等场景中应用广泛。
接下来,我就带大家深入了解 Kafka 的概念、架构设计和底层原理。
一、Kafka 的核心概念
Kafka 是 Apache 软件基金会开发的开源流处理平台,本质上是个分布式、分区化、多副本的日志提交服务。简单说,它就像个大消息容器,能接收多个生产者的消息,再分发给多个消费者。
下面这几个核心概念得搞清楚:
-
生产者(Producer):负责把消息发送到 Kafka 集群,还能按策略将消息发到指定分区,实现负载均衡或按业务分类存储。
-
消费者(Consumer):从 Kafka 集群读取消息,可组成消费者组一起消费某个主题的消息,提高处理效率。
-
主题(Topic):消息的分类标识,生产者往特定主题发消息,消费者从特定主题读消息,相当于消息的集合。
-
分区(Partition):为提升吞吐量和并行处理能力,一个主题可分成多个分区。每个分区是有序且不可变的消息序列,消息按发送顺序存储。
-
副本(Replica):为保证数据可靠,每个分区可有多个副本。一个是领导者(Leader),处理生产者和消费者的请求;其他是追随者(Follower),通过复制领导者数据保持同步,领导者故障后,追随者会被选为新领导者。
-
Broker:Kafka 集群的服务器节点,每个 Broker 存储部分主题的分区和副本,它们相互通信协调,维持集群稳定运行。
二、Kafka 的架构设计
Kafka 采用分布式架构,由生产者、消费者、主题、分区、副本和 Broker 等组件构成,各组件协同工作,实现高效消息传递。
(一)整体架构
Kafka 集群由多个 Broker 组成,每个都有唯一标识。主题分成多个分区,分布在不同 Broker 上,每个分区有多个副本,一个是领导者,其余是追随者。生产者把消息发到指定主题的分区领导者,追随者复制领导者数据保持一致。消费者从分区领导者读消息,还能组成消费者组,组内消费者分别消费不同分区消息,实现并行处理。ZooKeeper 和各个 Broker 通信,管理集群元数据。
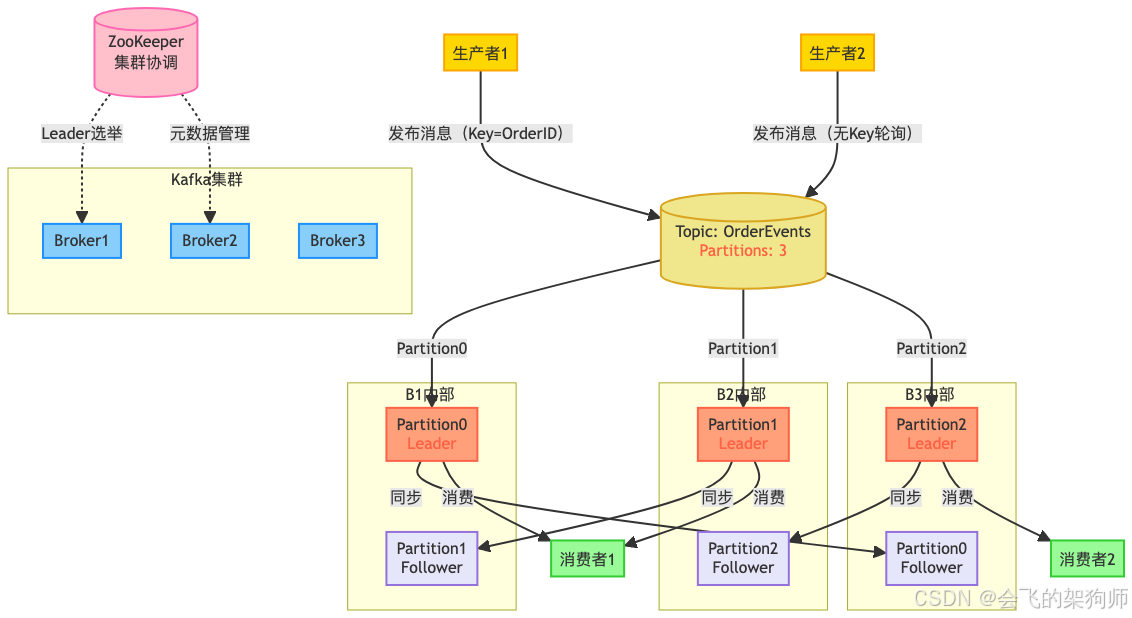
(二)ZooKeeper 在传统架构中的作用
早期 Kafka 架构里,ZooKeeper 作用关键:
-
元数据存储:存着集群的各类元数据,像 Topic 的分区数量、副本分布,Broker 的 IP、端口等。不过从 Kafka 0.9.0.0 版本起,消费者组的偏移量就存在 Kafka 内部的__consumer_offsets 主题,不再存在 ZooKeeper 了。这些元数据很重要,生产者、消费者和 Broker 都要经常读,来决定消息发往哪个分区、从哪开始消费等。
-
控制器选举:集群的 Controller 负责分区创建、删除、副本分配迁移等操作。它的选举靠 ZooKeeper 的临时节点和 Watcher 机制。所有 Broker 都尝试在 ZooKeeper 创建特定临时节点,第一个成功的就是 Controller。其他 Broker 监听这个节点,一旦当前 Controller 所在 Broker 故障,节点消失,其他 Broker 就重新竞争,选出新 Controller。
-
服务发现与集群拓扑管理:新加入的 Broker 能通过 ZooKeeper 快速找到其他节点并注册。ZooKeeper 还监控 Broker 状态,上线或下线时及时更新信息,通过 Watcher 机制通知其他组件,让它们调整状态。比如某个 Broker 下线,ZooKeeper 告诉 Controller,Controller 就重新分配该 Broker 上的分区副本。
(三)核心组件的作用
-
生产者:按分区策略把消息发到对应分区领导者,策略可以是哈希、轮询或自定义的。还能配置消息确认机制,确保消息可靠发送。
-
消费者与消费者组:消费者订阅主题获取消息,组内每个消费者消费一个或多个分区,且每个分区只被组内一个消费者消费,避免重复消费。消费者通过提交偏移量记录消费位置,重启或重新加入组时,能从上次位置继续消费。
-
主题与分区:主题是消息的逻辑分类,分区是物理存储单元。有了分区,Kafka 能并行读写,提高吞吐量。每个分区的消息都有唯一偏移量,标识其位置。
-
副本机制:这是保证数据可靠的关键。分区副本分布在不同 Broker,领导者故障后,从追随者中选新领导者。追随者定期复制领导者消息,保持数据一致。
-
Broker:负责存储分区和副本,处理生产者和消费者的请求。传统模式下,Broker 之间靠 ZooKeeper 协调,ZooKeeper 管理着主题分区、副本分布等元数据。
(四)Kafka 对 ZooKeeper 的依赖移除与 KRaft 模式
随着 Kafka 的广泛应用,ZooKeeper 的问题逐渐显现。运维 ZooKeeper 集群复杂,要额外投入资源,而且它和 Kafka 运维方式不同,对运维人员要求高。大规模集群中,ZooKeeper 处理大量元数据操作可能出现性能瓶颈,影响整个集群。
为解决这些问题,从 Kafka 2.8.0 版本开始,引入了 KRaft(Kafka Raft)模式,逐步移除对 ZooKeeper 的依赖,实现自管理元数据共识。KRaft 用新的仲裁控制器服务取代依赖 ZooKeeper 的控制器,采用基于事件的 Raft 共识协议变体达成元数据一致。
-
架构变化:KRaft 模式下,集群不依赖外部 ZooKeeper,引入专门的 Controller 节点(通过
process.roles配置角色)。这些节点靠 Raft 协议组成仲裁集合,管理元数据。元数据存在 Kafka 内部的__cluster_metadata主题,通过 Raft 协议在 Controller 节点间复制,保证一致性和高可用性。 -
Controller 选举机制:传统模式靠 ZooKeeper 的临时节点和竞争创建机制选举 Controller。KRaft 模式下,配置为
controller角色的节点参与 Raft 选举。候选节点等随机时间后发起选举,获超过半数投票的成为主 Controller,处理元数据写入和同步,其他节点作为追随者同步日志。这种方式更直接高效,减少了外部依赖带来的复杂和故障点。 -
对集群的影响:用了 KRaft 模式,不用单独部署管理 ZooKeeper 集群,简化运维,降低成本。元数据管理集成在 Kafka 内部,避免了和 ZooKeeper 频繁交互的性能瓶颈,处理大规模元数据操作时性能提升,分区创建、删除等操作响应更快,集群扩展性也更好。到 Kafka 4.0 版本,KRaft 模式成为默认设置,标志着 Kafka 在摆脱 ZooKeeper 依赖上迈出重要一步。
三、Kafka 的底层原理
(一)消息存储原理
Kafka 的消息以日志文件存在 Broker 磁盘上。每个分区对应一个目录,里面有多个日志段(Log Segment)文件,由数据文件(.log)和索引文件(.index)组成,分别用于存储消息和快速定位消息。
生产者发消息到分区,会追加到当前活跃的日志段文件末尾。当文件达到一定大小,就创建新的日志段文件。这种分段存储方便消息查找和过期消息删除。
(二)消息传递机制
Kafka 用推拉结合的方式传递消息。生产者主动把消息推到分区领导者,消费者主动从分区领导者拉取消息。这样能根据消费者处理能力调整拉取速度,避免消息积压。
传递过程中,还用了批量发送和压缩技术提高效率。生产者把多个消息打包发送,减少网络传输次数;压缩消息能减小大小,降低带宽消耗。
(三)副本同步机制
Kafka 的副本同步用 ISR(In-Sync Replicas)机制,ISR 是和领导者保持同步的追随者集合。判断追随者是否在 ISR 中,主要看是否在规定时间(replica.lag.time.max.ms)内和领导者通信,以及消息偏移量差距是否在规定范围(新版本更多看时间)。不符合就会被移出 ISR,只有 ISR 中的副本能被选为新领导者,保证数据最新。
生产者发消息到领导者后,领导者写入本地日志,等待 ISR 中的追随者复制成功。达到一定数量(通过 acks 参数配置,比如 acks=all 要求所有 ISR 中的追随者都复制成功)后,领导者才向生产者确认消息发送成功。这种机制在保证可靠性的同时,也提高了效率。
(四)消费者组重平衡机制
当消费者组的消费者数量变化,或者主题分区数量变化时,Kafka 会触发重平衡(Rebalance),重新分配消费者和分区的对应关系,确保每个分区都有消费者消费。
重平衡时,消费者组会暂停消费,直到完成。为减少影响,Kafka 引入消费者组协调器(Coordinator)管理这个过程,还优化算法缩短时间。协调器收集组内消费者信息,按范围分配、轮询分配等策略把分区分给消费者。
总的来说,Kafka 凭借合理的架构设计和底层原理,实现了高性能、高吞吐量、高可靠性的消息传递。深入理解这些,对用好和优化 Kafka 很有帮助。