集成学习与随机森林:从原理到实践指南
引言:为什么需要集成学习?
在机器学习领域,"三个臭皮匠,顶个诸葛亮"的谚语被转化为强大的技术范式——集成学习(Ensemble Learning)。这种方法通过组合多个基学习器的预测结果,以获得比单一模型更优越的性能。特别是在Kaggle等数据科学竞赛中,排名靠前的解决方案几乎总是集成方法的成果。
集成学习的理论基础
集成学习的有效性建立在这两个核心原则之上:
偏差-方差权衡(Bias-Variance Tradeoff):
- 单模型往往在低偏差(复杂模型)和低方差(简单模型)间难以平衡
- 集成方法通过组合多个模型,同时降低了偏差和方差
- 公式:E[(y−f^(x))2]=Bias[f^(x)]2+Var[f^(x)]+σ2
误差分解(Error Decomposition):
- 模型总误差 = 偏差 + 方差 + 噪声
- 集成模型减少方差部分:Mσ2(M为模型数量)
- 多模型组合可减少过拟合风险
第一部分:集成学习全景图
1.1 Bagging (Bootstrap Aggregating)
核心思想:
- 多个模型独立训练,投票决定最终结果
- 减少方差,适合高方差模型(如决策树)
算法流程:
- 从原始数据集中有放回抽样(bootstrap)创建多个子集
- 每个子集独立训练一个基学习器
- 分类问题:多数投票;回归问题:平均预测
代表算法:
- 随机森林(Random Forest)
- ExtraTrees
1.2 Boosting
核心思想:
- 按顺序训练多个弱学习器
- 每个新模型聚焦前序模型的错误
算法流程:
- 训练初始弱学习器
- 根据错误样本调整权重
- 训练下一个模型,侧重之前错分的样本
- 组合所有模型的加权预测
代表算法:
- AdaBoost
- Gradient Boosting Machines (GBM)
- XGBoost, LightGBM, CatBoost
1.3 Stacking
核心思想:
- 训练元学习器组合多个基模型的输出
- 在Kaggle竞赛中广泛使用
算法流程:
- 训练多个不同的基模型(KNN,SVM,神经网络等)
- 用基模型的预测作为新特征
- 基于新特征训练元学习器
1.4 Voting & Blending
简单但有效的集成策略:
from sklearn.ensemble import VotingClassifier# 定义多个基模型
model1 = LogisticRegression()
model2 = RandomForestClassifier()
model3 = SVC(probability=True)# 组合基模型
ensemble = VotingClassifier(estimators=[('lr', model1), ('rf', model2), ('svc', model3)],voting='soft' # 软投票:使用概率加权
)第二部分:深入解析随机森林
2.1 随机森林的核心思想
随机森林是Bagging的扩展,由多棵决策树组成。它的关键创新在于引入双重随机性:
数据随机性:
- 每棵树在原始数据的有放回采样(Bootstrap)上训练
- 约63.2%样本被选中,其余36.8%形成袋外样本(OOB)
特征随机性:
- 每次分裂随机选择特征子集(通常为总特征数的平方根)
- 打破特征相关性,增强模型多样性
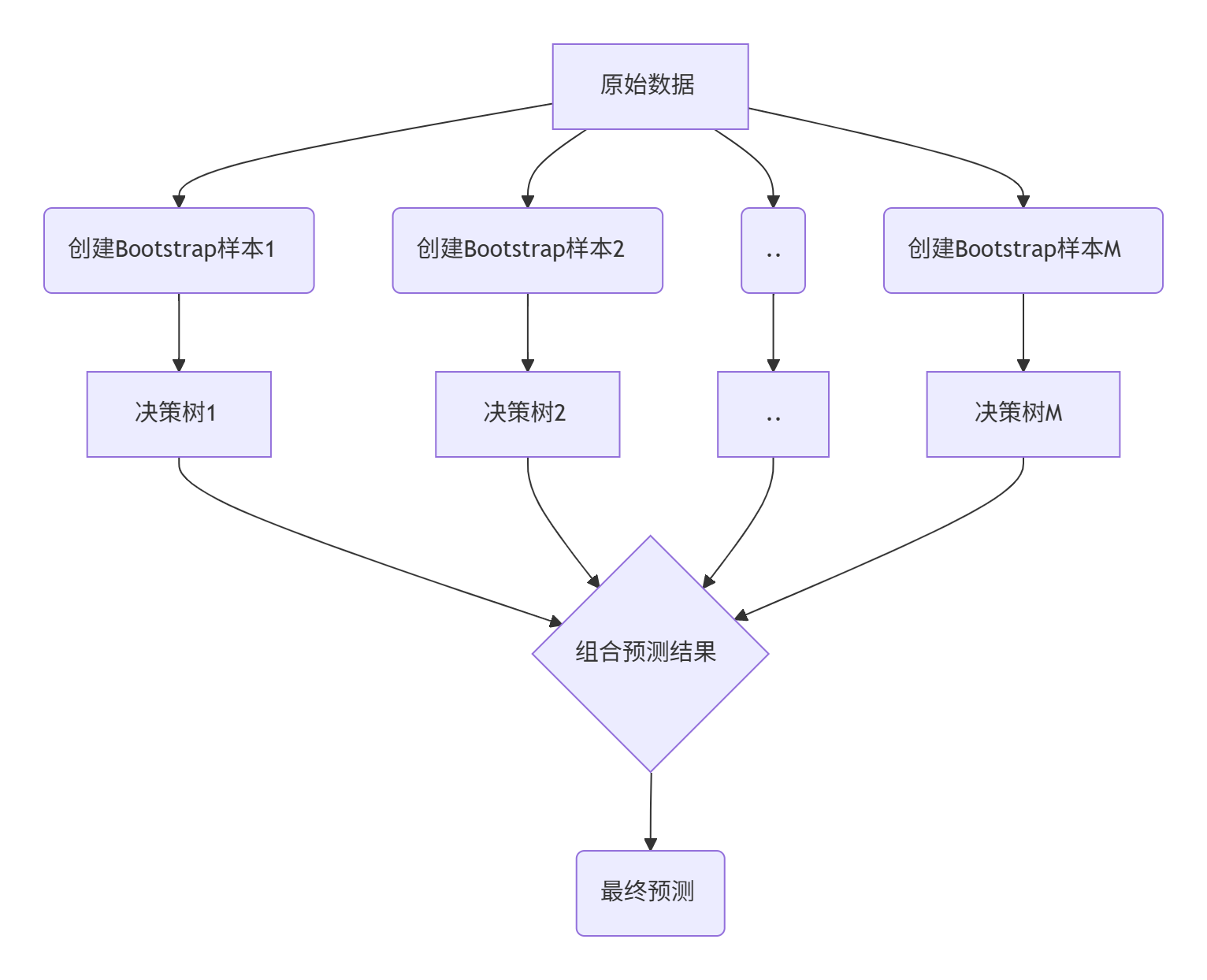
2.2 算法原理详解
随机森林的工作流程:
关键数学基础:
Gini不纯度(分类树分裂标准)
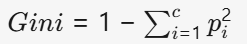
- pi:节点中i类样本的比例
- Gini越小,节点越纯净
袋外估计(OOB Estimate)
- 用未参与训练的36.8%样本验证
- 几乎等同于交叉验证,无需额外划分验证集
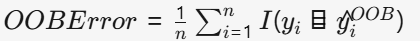
2.3 为什么随机森林如此强大?
| 优势 | 说明 |
|---|---|
| 高准确性 | 多树组合减少过拟合,提高泛化能力 |
| 抗噪声能力 | 随机性使模型对噪声和异常值不敏感 |
| 特征重要性 | 提供直观的特征贡献度评估 |
| 处理高维数据 | 自动特征选择,适用于特征数>样本数的情况 |
| 内置验证机制 | OOB估计提供无偏性能评估 |
| 灵活数据类型 | 处理数值、分类特征,无需标准化 |
在真实的信贷风险评估案例中,随机森林将坏账识别率从单决策树的78%提升到92%,同时保持86%的精确率。
第三部分:scikit-learn随机森林API实战
3.1 分类器与回归器
scikit-learn提供两种核心实现:
# 分类任务
from sklearn.ensemble import RandomForestClassifier# 回归任务
from sklearn.ensemble import RandomForestRegressor3.2 参数详解(以RandomForestClassifier为例)
森林规模控制
| 参数 | 类型 | 默认值 | 作用 | 建议 |
|---|---|---|---|---|
n_estimators | int | 100 | 树的数量 | 100-500,性能与计算成本权衡 |
n_jobs | int | None | 并行使用的CPU核心数 | -1:使用所有核心 |
warm_start | bool | False | 增量训练 | 树数量逐步增加时设为True |
示例:
# 创建含200棵树的森林,使用所有CPU核心
rf = RandomForestClassifier(n_estimators=200, n_jobs=-1)树结构控制
| 参数 | 类型 | 默认值 | 作用 | 建议 |
|---|---|---|---|---|
max_depth | int | None | 树的最大深度 | 5-30,限制复杂度防过拟合 |
min_samples_split | int/float | 2 | 节点分裂所需最小样本数 | 10-100或样本比0.1%-1% |
min_samples_leaf | int/float | 1 | 叶节点最少样本数 | 1-20,提高泛化能力 |
min_weight_fraction_leaf | float | 0.0 | 叶节点最小加权样本比例 | 样本权重不均衡时调整 |
max_leaf_nodes | int | None | 最大叶节点数 | 替代max_depth的停止条件 |
min_impurity_decrease | float | 0.0 | 分裂需减少的最小不纯度 | 0.01-0.1 |
示例:
# 限制树深度和节点大小
rf = RandomForestClassifier(max_depth=15,min_samples_split=10,min_samples_leaf=5
)随机性控制
| 参数 | 类型 | 默认值 | 作用 | 建议 |
|---|---|---|---|---|
max_features | int/float/str | 'auto' | 分裂考虑的特征数 | "sqrt"(分类), 1.0(回归), 0.5-0.8 |
bootstrap | bool | True | 使用bootstrap采样 | 保持True以获得随机性 |
oob_score | bool | False | 计算袋外估计 | 模型验证设为True |
random_state | int | None | 随机种子 | 重现结果设定固定值 |
示例:
# 启用OOB评估,限制每分裂的特征数
rf = RandomForestClassifier(max_features=0.6,oob_score=True,random_state=42
)特殊场景处理
| 参数 | 类型 | 默认值 | 作用 |
|---|---|---|---|
class_weight | dict/str | None | 类别权重 |
ccp_alpha | float | 0.0 | 最小复杂度裁剪 |
max_samples | int/float | None | bootstrap样本数 |
3.3 模型评估与特征重要性
训练与评估
# 拟合模型
rf.fit(X_train, y_train)# 基本评估
train_acc = rf.score(X_train, y_train)
test_acc = rf.score(X_test, y_test)# OOB评估(若启用)
oob_acc = rf.oob_score_特征重要性分析
# 获取特征重要性
importances = rf.feature_importances_# 创建重要性DataFrame
feature_importances = pd.DataFrame({'feature': X_train.columns,'importance': importances
})# 排序并可视化前10名
top_features = feature_importances.sort_values('importance', ascending=False).head(10)plt.figure(figsize=(12, 6))
sns.barplot(x='importance', y='feature', data=top_features, palette='viridis')
plt.title('Top 10 Important Features')
plt.tight_layout()3.4 完整工作流示例
# 导入库
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 创建模拟数据
X, y = make_classification(n_samples=2000, n_features=20, n_informative=15,random_state=42
)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# 创建随机森林模型
rf = RandomForestClassifier(n_estimators=150,max_depth=12,min_samples_split=8,min_samples_leaf=3,max_features='sqrt',oob_score=True,n_jobs=-1,random_state=42
)# 训练模型
rf.fit(X_train, y_train)# 评估性能
train_acc = rf.score(X_train, y_train)
test_acc = rf.score(X_test, y_test)
oob_acc = rf.oob_score_print(f"Train Accuracy: {train_acc:.4f}")
print(f"Test Accuracy: {test_acc:.4f}")
print(f"OOB Accuracy: {oob_acc:.4f}")# 特征重要性可视化
importances = rf.feature_importances_
feature_names = [f'Feature_{i}' for i in range(X.shape[1])]importance_df = pd.DataFrame({'Feature': feature_names,'Importance': importances
}).sort_values('Importance', ascending=False)plt.figure(figsize=(12, 8))
sns.barplot(x='Importance', y='Feature', data=importance_df.head(10))
plt.title('Top 10 Important Features')
plt.tight_layout()
plt.savefig('feature_importances.png', dpi=300)随机森林的局限与应对策略
| 局限 | 应对策略 |
|---|---|
| 树的数量多时计算开销大 | 使用硬件加速(GPU),增量学习 |
| 特征重要性偏向高基数 | 排列重要性,SHAP值 |
| 外推能力有限 | 结合时间序列模型,特征工程 |
| 规则缺乏平滑性 | 与神经网络集成 |
结语
随机森林作为集成学习中最实用且强大的算法之一,在过去二十年间深刻影响了机器学习的实践应用。通过本技术博客,我们从原理到实践详细解析了这一算法:
- 探讨了集成学习的理论基础和方法分类
- 深入分析了随机森林的双重随机机制和数学原理
- 详细介绍了scikit-learn API的每个参数和实用技巧
- 提供了高级调优策略和最佳实践指南
- 展示了实际应用场景和未来发展方向
随机森林的独特优势在于其强大的预测性能、内在的特征选择机制以及天然的抗过拟合能力。随着算法不断创新改进,它仍将在未来的机器学习生态系统中扮演重要角色。