MLIR Bufferization
简介
MLIR中的Bufferization是将tensor语义的ops转换为memref语义的ops。
Bufferization的顶层目标是:
-
使用尽可能少的内存。
-
拷贝尽可能少的内存。
这就意味着要尽可能地做Buffer复用,Bufferization就成了一个类似Register Allocation的算法问题。在实际的Use Case中,对Bufferization还有一些额外的需求,比如重计算和计算一次并拷贝的权衡等。
给定一个产生tensor结果的op,Bufferization需要选择一个memref buffer来存储结果,可选的方法:
-
新分配一个buffer,可行并安全,但是可能不满足性能需求。
-
复用一个已经存在的buffer,要注意不能覆盖掉后续程序还会使用的数据。
Bufferization相关的pass通常放到pass pipeline的最后几步,因为大部分变换pass在tensor语义上更简单(不需要数据流分析和依赖分析),如tile/fuse等。与Bufferization相关的pass如下:
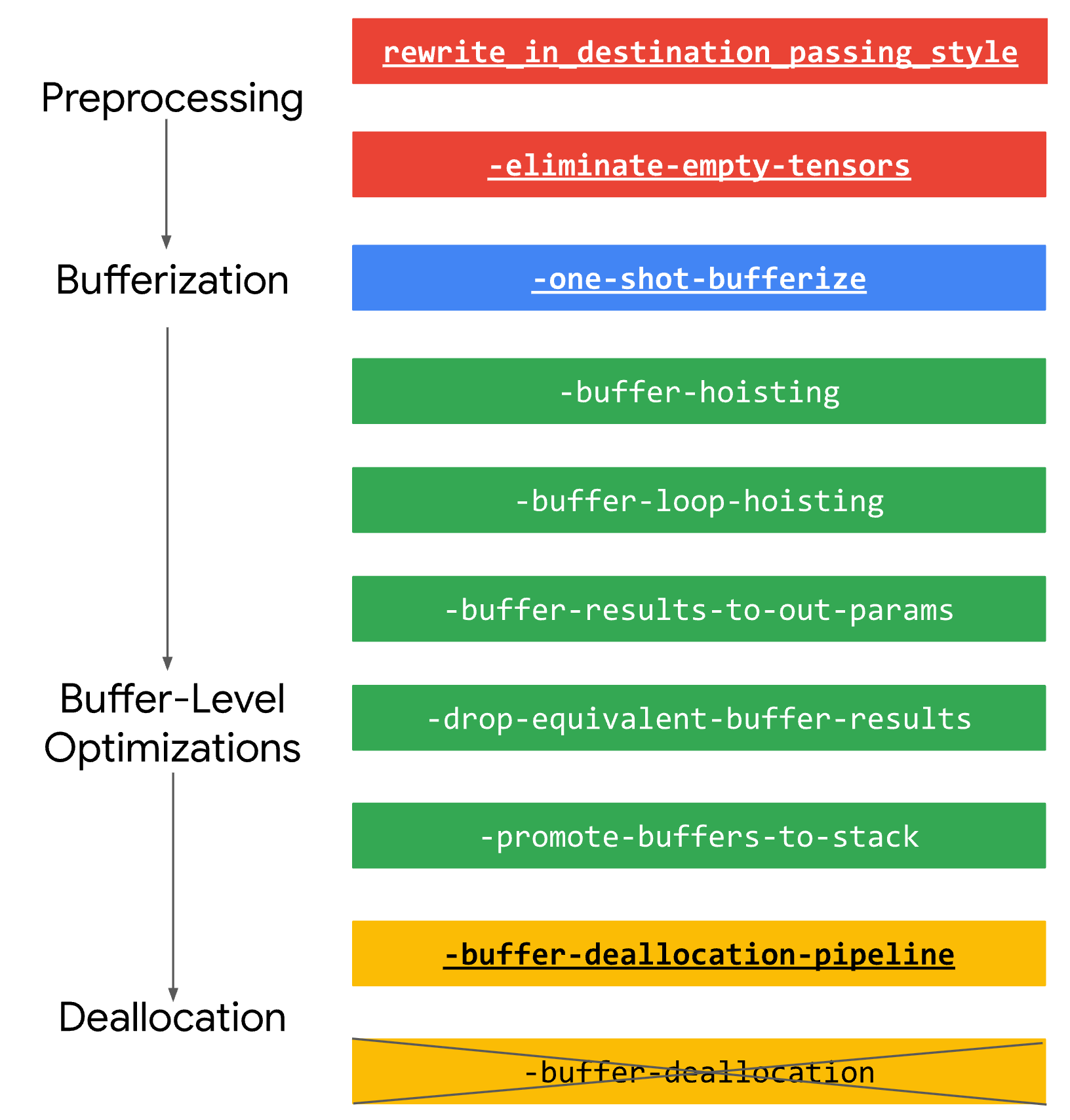
可以看到Bufferization大致分为如下步骤:
- 将IR rewrite成DPS形式
- bufferization变换(tensor -> buffer)
- buffer优化
- 插入释放操作
DPS
DPS(Destination-Passing Style)是指函数或操作不再通过返回值来传递结果,而是将结果直接写入预先分配好的目标位置(即“destination”),示例如下:
// 非 DPS 风格
int func(int x) {return x + 1;
}// DPS 风格
void func(int x, int *result) {*result = x + 1;
}在MLIR中,DSP用于将不可变的 SSA 值转换为可变的缓冲区,以tensor语义的linalg.generic为例:
#map0 = affine_map<(i,j) -> (i)>
#map1 = affine_map<(i,j) -> (i,j)>%result = linalg.generic {indexing_maps = [#map0, #map1],iterator_types = ["parallel", "reduction"]
} ins(%input: tensor<3x4xf32>) outs(%output: tensor<3xf32>) {^bb0(%i: index, %j: index, %in: f32, %out: f32):%sum = arith.addf %out, %in : f32linalg.yield %sum : f32
} -> tensor<3xf32>这里的outs里的%output既提供了初始值,又作为reduce的目的缓冲区,这就成为了缓冲区化算法的可能“锚点”:缓冲区优化算法可以将%output 的内存直接用作 %result 的存储。
总结一下,就是DPS op对每一个tensor result,都有一个对应的tensor operand。Bufferization可以别名化operand和result,实现inplace操作。
Tensor / Buffer Boundary
Bufferization提供了一些helper ops用于连接tensor IR和已有的buffer(如在其他runtime/library申请的buffer):
-
bufferization.to_buffer %t:返回一个tensor的buffer。 -
bufferization.to_tensor %m:返回一个MemRef buffer的tensor。 -
bufferization.materialize_in_destination:tensor需要在指定的buffer上实例化。
如下示例展示了bufferization.materialize_in_destination的用法:
// Batched TOSA matrix multiplication. %A and %B are the
// inputs, %C is the output.
func.func @test_matmul(%A: memref<1x17x19xf32>,%B: memref<1x19x29xf32>,%C: memref<1x17x29xf32>) {%A_tensor = bufferization.to_tensor %A restrict : memref<1x17x19xf32> to tensor<1x17x19xf32>%B_tensor = bufferization.to_tensor %B restrict : memref<1x19x29xf32> to tensor<1x19x29xf32>%0 = tosa.matmul %A_tensor, %B_tensor: (tensor<1x17x19xf32>, tensor<1x19x29xf32>) ->tensor<1x17x29xf32>bufferization.materialize_in_destination%0 in restrict writable %C: (tensor<1x17x29xf32>, memref<1x17x29xf32>) -> ()return
}这里的restrict关键字类似C中的restrict, 表明没有其他的to_tensor或materialize_in_destination op关联到这个MemRef op和它的别名。这样bufferization就只需要关注转换后的tensor IR部分。
One-Shot Bufferize
-one-shot-bufferize pass会完成所有tensor语义的op(需要实现BufferizableOpInterface接口,如上面的linalg.generic)分析,并完成One-shot bufferize。
默认的,函数边界不可以被bufferized,这个主要是由于函数可能存在递归调用。
当One-Shot Bufferize遇到non-bufferizable的tensor时,会插入一个to_buffer的op,并决定Memref的类型。默认的,会选择动态memref类型,示例如下:
// bufferize前
%0 = "my_dialect.unbufferizable_op(%t) : (tensor<?x?xf32>) -> (tensor<?x?xf32>)
%1 = tensor.extract %0[%idx1, %idx2] : tensor<?xf32>// bufferize后
%0 = "my_dialect.unbufferizable_op(%t) : (tensor<?x?xf32>) -> (tensor<?x?xf32>)
%0_m = bufferization.to_buffer %0 : memref<?x?xf32, strided<[?, ?], offset: ?>>
%1 = memref.load %0_m[%idx1, %idx2] : memref<?x?xf32, strided<[?, ?], offset: ?>>
One-Shot Bufferize会尝试尽可能地推导出精确地memref类型,如果整个IR都是bufferizable的,那么就不需要使用动态Memref类型。但也存在例外场景,示例如下:
// bufferize前
%casted = tensor.cast %input : tensor<*xf32> to tensor<?x?xf32>// bufferize后
%casted_m = memref.cast %input_m : memref<*xf32> to memref<?x?xf32, strided<[?, ?], offset: ?>>扩展One-Shot Bufferize
用户自定义op可以通过实现BufferizableOpInterface接口而被bufferize:
-
bufferizesToMemoryRead: 返回true如果opOperand的buffer被这个op读取。 -
bufferizesToMemoryWrite: 返回true如果opOperand的buffer被这个op读取。 -
getAliasingOpResult: 返回可能与给定opOperand共享同一缓冲区的opResult。 -
bufferRelation:-
返回
BufferRelation::Equivalent如果给定的OpResult的memref是OpOperand memref的别名 (如in-place)。 -
否则返回
BufferRelation::Unknown。
-
-
bufferize: 使用给定的rewriter重写这个op。可以使用bufferization::replaceOpWithBufferizedValues替换引用该op值的地方。
参考资料:
Bufferization - MLIR