【Linux】特效爆满的Vim的配置方法 and make/Makefile原理

一、软件包管理器
1、Linux下安装软件的常见方式:
1)源代码安装——不推荐。
2)rpm包安装——不推荐。
3)包管理器安装——推荐
2、安装软件命令
# Centos$ sudo yum install -y lrzsz# Ubuntu$ sudo apt install -y lrzsz3、卸载软件命令
# Centossudo yum remove [-y] lrzsz# Ubuntusudo apt remove [-y] lrzsz任何评估一款操作系统的好坏?操作系统被设计出来之后,最重要的事情是什么?
答:操作系统形成使用圈子就会被更多的人使用,为了让更多的人使用就必须让圈子更完善;有人愿意在特定的os上编写特定的软件适应不同的群体,并且在各种圈子完善社区、文档、论坛、资料。
二、编辑器 Vim
IDE在Linux下的开发工具是独立的!写代码——编辑器vim,编译代码——gcc/g++,调试——gdb/cgbd,构建工具——makefile/make/cmake。
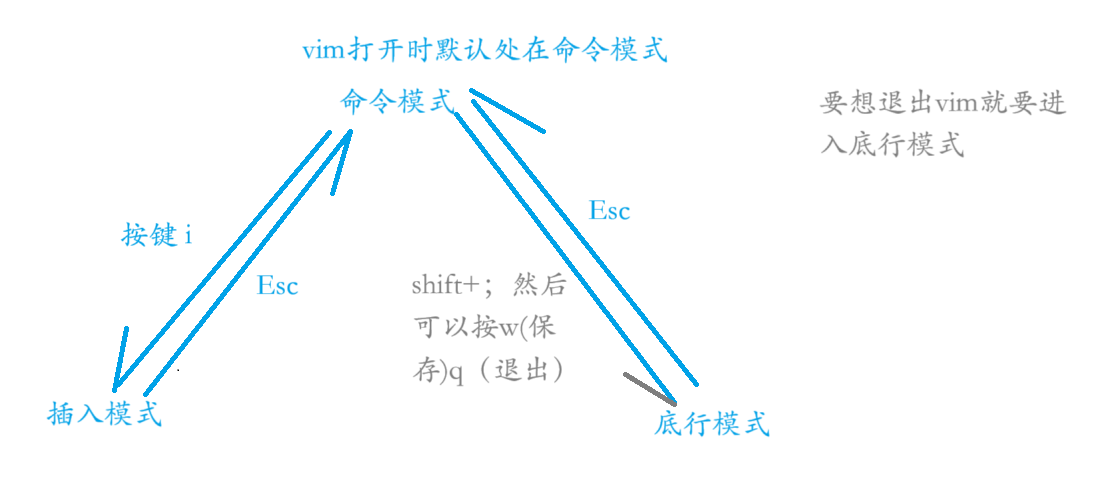
进入vim的指令:vim + 文件。进入vim之后要写内容按键盘 i 键。
vimd的多模式:命令模式、插入模式、底行模式。
底行模式:set nu,是给内容加上行号,如:
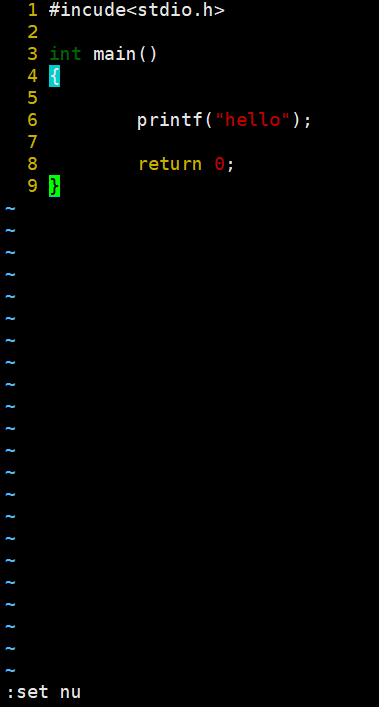
注意:如果想去掉行号在底行模式输入:nonu。
命令模式下:
shift+g:光标进入文本末端。
gg:光标进入文本的开始。
n+shift+g:光标进入来到文本n行。
shift+4:光标进入到当前行的末尾。
shift+6:光标来到当前行的开始。
h:光标往左移动。
j:光标往下移动。
k:光标往上移动。
l:光标往右移动。
w:按照单词向右移动。注意:可以加上数字。
b:按照单词向左移动。注意:可以加上数字。
yy:复制当前行的内容。n+yy复制前n行内容。
p:粘贴。n+p可以粘贴n次。
dd:删除当前行。n+dd删除前n行内容。
u:撤销操作。
ctrl+r:对u的撤销。
注意:任意模式下都可以进行撤销操作,退出vim就不能撤销了。
shift+~:对光标的字母进行大小写切换。
r:替换光标所在位置的一个字符,n+r替换n个字符。
shift+r:进入替换模式,忽视原来文本内容,可重新编写。注意:进入替换模式之后要退出来就要按Esc键。
x:删除光标所在字符,向右删除。
shift+x:向左删除光标所在字符。
批量化注释:①ctrl+v,②hjkl选择区域,③shift+i,④//,⑤Esc。
批量化去注释:①ctrl+v,②hjkl选择区域,③d,④Esc。
底行模式下:
w!:保存。
q!:退出。
wq!:强制保存并退出。
注意:如果vim打开文件,突然终端退出,vim会形成临时文件,默认在当前路径的下一个.swp临时ls -al。
:/key+n:匹配搜索。
:!cmp:不退出vim,直接对代码进行编译运行。
:%s/dst/src/g:把文本内容所有的dst替换成src。
:vs:分屏操作。ctrl+www,选中哪一个分屏。
注意:当vim退出光标在第n行,再次打开光标还在原来位置。那么我们Linux下可输入vim +文件名+n,直接进入到第n行。在命令模式下退出vim操作:shift+zz。
配置炫酷的vim:
要配置炫酷的vim,原生的配置可能功能不全,可以选择安装插件来完善配置,保证用户是你要配置的用户,接下来:
①安装TagList插件,下载taglist_xx.zip,解压完成,将解压出来的doc的内容放到~/.vim/doc,将解压出来的plugin下的内容拷贝到~/.vim/plugin。
②在~/.vimrc中添加:let Tlist_Show_One_File=1 letTlist_Exit_OnlyWindow=1 let Tlist_Use_Right_Window=1
③安装文件浏览器和窗口管理器插件:WinManager
④下载winmanager.zip,2.X版本以上的
⑤解压winmanager.zip,将解压出来的doc的内容放到~/.vim/doc,将解压出来的plugin下的内容拷贝到~/.xim/plugin
⑥在~/.vimrc中添加 let g:winManagerwindowLayout=‘FileExplorer|TagListnmap wm :WMToggle<cr>
⑦然后重启vim,打开~/XXX.c或~/XXX.cpp,在normal状态下输入"wm",你将看到上图的效果。更具体移步:手把手教你把Vim改装成一个IDE编程环境(图文)_vim 打造成 ide-CSDN博客,其他手册,请执行vimtutor 命令。
三、让普通用户暂时提权的方法
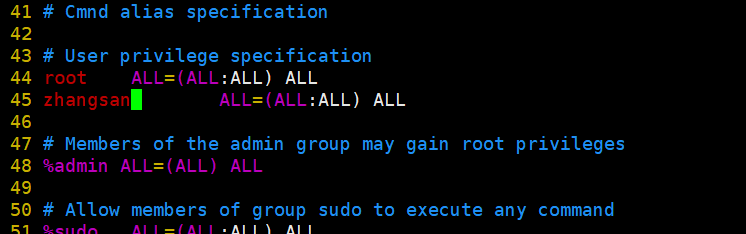
1、进入到root界面
2、指令:ls /etc/sudoers,查看sudoer是否存在。
3、指令:vim /etc/sudoers,进入sudoers
4、yy接着p一下
四、g++/gcc
1)区别
gcc:C编译器。只能用来进行编译C语言。
g++:C++/C语言编译器。
2)四步生成可执行文件
预处理(头文件展开,去注释,宏替换,条件编译):指令:gcc 文件名 -o 编译后行的文件名(可自己写)。由于gcc是一步到位(直接形成可执行文件),所以可以这么做:gcc -E 文件名 -o 预处理之后的文件名.i;
![]()
编译:把C语言变成汇编语言,指令:gcc -S 文件名.i -o 文件名.s
汇编:把汇编语言翻译成二进制文件,指令:gcc -c 文件名.s -o 文件名.o
链接:把二进制文件形成可执行文件,指令:gcc 文件名.o -o 文件名.exe
补充知识:为什么要把C语言翻译成汇编?
答:翻译语言的本质是转成CPU能够识别的指令集;汇编语言是用字母来对二进制指令进行包装;
先有汇编语言还是先有用汇编语言写的汇编编译器?
答:先拿二进制写出一个汇编编译器,再写出汇编语言,然后在拿汇编语言完善汇编编译器,最后再用汇编语言编写软件(如C语言编译器),最终再拿C语言编译器来写汇编编译器(编译器自举),所以先有语言。
.o二进制文件能不能直接运行?
答:不能,原因:如果运行.o文件他会报出错误:可重定位目标二进制文件,因为我们用到的库方法,只有说明,没有定义。
注意:在Linux中静态库是以.a为后缀,动态库是以.so为后缀;window的静态库是以.lib为后缀,动态库是以.dll为后缀。
动态链接优点:节省内存空间;缺点:慢,编译完成依旧依赖动态库;静态库的优点:不需要库跳转,一旦编译完成不依赖库;缺点:可执行程序体积较大(把库实现的方法拷贝到程序里面),消耗内存资源。
注意:gcc默认编译是采用动态链接的方式完成,如果想要强制进行静态链接可以输入指令:gcc 文件名 -o 文件名 -static。
3)静态库和动态库
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的libc.so.6就是动态库。
gcc在编译时默认使用动态库。完成了链接之后,gcc就可以生成可执行文件,如下所示。gcc hello.o-o hellogcc默认生成的二进制程序,是动态链接的,这点可以通过file 命令验证。
五、自动化项目的构建(生成可执行文件)——make/Makefile
1)背景
会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
makefile带来的好处就是—“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2)make/Makefile的执行原理
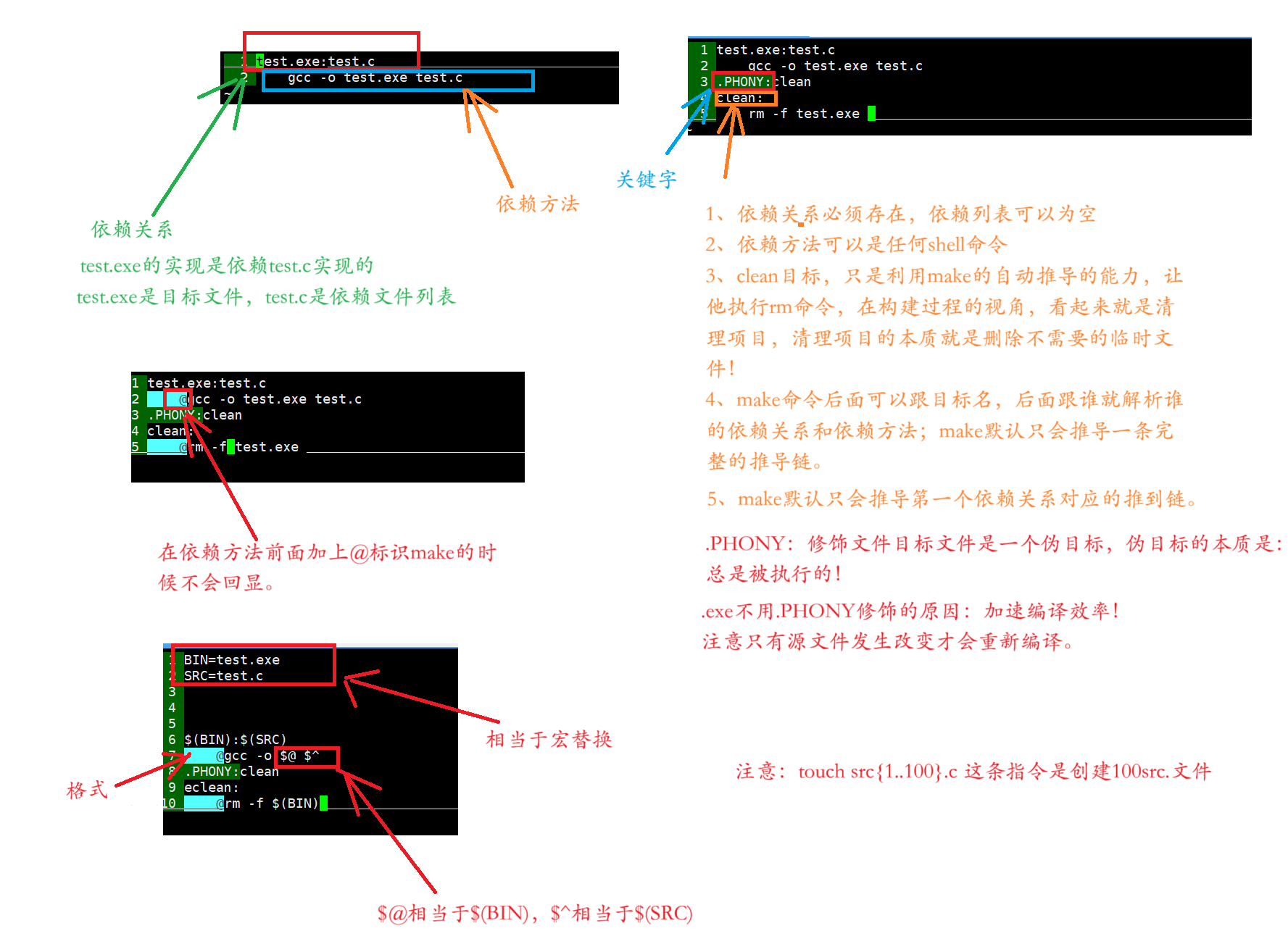
make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到myproc 这个文件,并把这个文件作为最终的目标文件。
如果myproc文件不存在,或是myproc所依赖的后面的myproc.o文件的文件修改时间要比 myproc 这个文件新(可以用touch 测试),那么,他就会执行后面所定义的命令来生成myproc这个文件。
如果myproc 所依赖的myproc.o文件不存在,那么make 会在当前文件中找目标为myproc.o文件的依赖性,如果找到则再根据那一个规则生成myproc.o文件。(这有点像一个堆栈的过程)
当然,你的C文件和H文件是存在的啦,于是 make 会生成 myproc.o 文件,然后再用myproc.o文件声明make的终极任务,也就是执行文件 hello了。
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
注意:gcc无法二次编译老代码的原因:源代码的时间比可执行文件的要旧,如果修改源代码那么的他的时间就会比可执行文件新,这时候就可以进行二次编译。修改一个文件的时间可以使用touch 一个已经存在的源文件,这时候就可以进行二次编译。
结论:判断文件新旧是根据文件的Mod时间来判定;.PHONY为什么总是被执行的?原因:就是让gcc或者对应的命令忽略Mod时间对比新旧。
注意:Modify是文件内容被修改的时间,change 是文件属性被修改的时间;只要修改文件的内容Mod和change的时间也会被修改,原因:修改文件内容会影响文件大小,包括Mod时间也是属性。Access是文件最近被访问的时间,查看文件会跟新时间,相当于修改文件属性,这时Linux就会刷新到磁盘,因为查看文件次数较多所以会增加磁盘的访问次数,外设效率低下,导致os整体效率降低,故而访问文件内容达到特定次数之后,才会更新一次时间。
 知识点补充:
知识点补充:
使用 wildcard 函数,获取当前所有.c文件名OBJ=$(SRC:.C=.0)//将SRC的所有同名.c替换成为.o形成目标文件列表$@:代表目标文件名。$^:代表依赖文件列表%.c展开当前目录下所有的.c。%.o:同时展开同%<:对展开的依赖.c文件,一个一个的交给gcc。@:不回显命令S(RM)·替换,用变量内容替换它注意:
SRC=$(wildcard *.cc) #wildcard是make的一个函数,用来匹配文件名
#*.cc就是wildcard函数的参数
#用法$(wildcard pattern) 参数 pattern 是一个文件名通配符模式
#文件名通配符模式是一种使用特殊字符来匹配一组文件名的语法
#特殊字符*表示匹配任意数量的字符(包括零个)
OBJ=$(SRC:.cc=.o)
这是 Makefile 中的 变量替换(模式替换) 语法,格式如下:
$(变量名:模式=替换)
它的意思是:把“变量名”中所有 符合“模式” 的部分,替换为“替换”。
六、进度条原理和设计
main.c
#include "process.h"
#include <unistd.h>
#include <time.h>
#include <stdlib.h>double gtotal = 1024.0;
double speed = 1.0;// 函数指针类型
typedef void (*callback_t)(double, double);// 1.0 4.3
double SpeedFloat(double start, double range) // [1.0 3.0] -> [1.0, 4.0]
{int int_range = (int)range;return start + rand()%int_range + (range - int_range);
}// cb: 回调函数
void DownLoad(int total, callback_t cb)
{srand(time(NULL));double curr = 0.0;while(1){if(curr > total){curr = total; // 模拟下载完成cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条break;}cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条curr += SpeedFloat(speed, 20.3); // 模拟下载行为usleep(30000);}
}int main()
{printf("download: 20.0MB\n");DownLoad(20.0, FlushProcess);printf("download: 2000.0MB\n");DownLoad(2000.0, FlushProcess);printf("download: 100.0MB\n");DownLoad(100.0, FlushProcess);printf("download: 20000.0MB\n");DownLoad(20000.0, FlushProcess);return 0;
}process.c
#include "process.h"
#include <string.h>
#include <unistd.h>#define SIZE 101
#define STYLE '='void FlushProcess(double total, double curr) // 更新进度, 按照下载进度,进行更新进度条
{if(curr > total)curr = total;double rate = curr / total * 100; // 1024.0 , 512.0 -> 0.5 -> 50.0int cnt = (int)rate; // 50.8 , 49.9 -> 50, 49char processbuff[SIZE];memset(processbuff, '\0', sizeof(processbuff));int i = 0;for(; i < cnt; i++)processbuff[i] = STYLE;static const char *lable = "|/-\\";static int index = 0;// 刷新printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);index %= strlen(lable);fflush(stdout);if(curr >= total){printf("\n");}
}// version1: 能够使用吗??
// 说明原理
void Process()
{const char *lable = "|/-\\";int len = strlen(lable);char processbuff[SIZE];memset(processbuff, '\0', sizeof(processbuff));int cnt = 0;while(cnt <= 100){printf("[%-100s] [%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);fflush(stdout);processbuff[cnt++] = STYLE;usleep(30000);}printf("\n");
}process.h
#pragma once#include <stdio.h>// version1
void Process();
void FlushProcess(double total, double curr); // 更新进度, 按照下载进度,进行更新进度条完!!