【C++】语法基础篇
一、变量、输入输出、表达式和顺序语句
1.常用头文件
#include<cstdio>----常用函数 printf 和 scanf
#include<iostream>----常用函数cin 和 cout
#include<cmath>----常用函数sqrt(开平方)
#include<bits/stdc++.h>----包含了常见的所有函数
#include<algorithm>---swap()交换,reverse(a,a+k+1)翻转从a到a+k的值
cin和scanf区别:cin过滤空格,scanf 的 %c 不过滤空格
2.命名空间
using namespace std;
3.变量
变量必须先定义才能使用,包括算数类型和空类型(void)
算数类型包括:
字符、整数、浮点数、布尔值
-
字符类型的普通字符(char)8位(1B),要用单引号。
| 类型 | 含义 | 最小尺寸 | 输出格式 |
|---|---|---|---|
| char | 普通字符 | 8位(1B) | %c |
- 整数类型如下:
| 类型 | 含义 | 最小尺寸 | 输出格式 |
|---|---|---|---|
| short | 短整形 | 16位(2B) | %hd |
| int | 整形 | 32位(4B) | %d |
| long long | 长整型 | 64位(8B) | %lld |
long long类型值结尾需要加LL,比如long long M=11356985663LL
- 浮点类型如下:
| 类型 | 含义 | 最小尺寸 | 输出格式 |
|---|---|---|---|
| float | 单精度 | 6位有效数字,32位(4B) | %f |
| double | 双精度 | 10位有效数字,64位(8B) | %lf |
| long double | 扩展精度 | 10位有效数字 |
科学记数法: ==> 1.23e8
- 布尔类型如下:
| 类型 | 含义 | 最小尺寸 |
|---|---|---|
| bool | 布尔类型 | 8位(1B) |
4.运算符
运算符讲解:
| 运算符 | 描述 | 实例 | 备注 |
|---|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 30 | |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -10 | |
| * | 把两个操作数相乘 | A * B 将得到 200 | |
| / | 分子除以分母 | B / A 将得到 2 | 如果两个数都是整数,则是整除 |
| % | 取模运算符,整除后的余数 | B % A 将得到 0 | 如果被除数是负数,则取模后为负数,主要取决于被除数 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 11 | A++,先给值再加加 ++A,先加加再给值 |
| -- | 自减运算符,整数值减少 1 | A-- 将得到 9 | A--,先给值再减减 --A,先减减再给值 |
5.转化
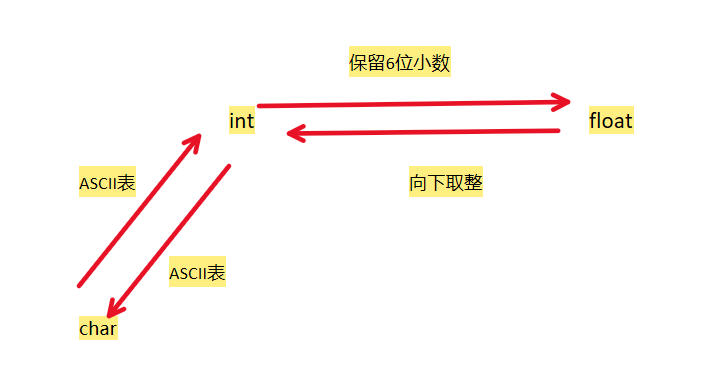
大小写字母ASCII开始
![]()
隐式类型转换:int*float=float,向着精确度高的方向转换
6.浮点数比较
两个浮点数的差小于一个极小的数就默认二者相等
const double eps=1e-6;
if(abs(a-b)<=eps)puts("相等");7.题目
二、判断语句
1.句式
| if | if ...else... | if ...else... if... else... if ...else... |
2.条件表达式
| and 和 && | or 或 || | not 非 ! |
优先级:and >or
短路原则:A and B---------------若A错误,则不需要计算B
A or B---------------若A正确,则不需要计算B
比较:三个值进行比较必须是两两比较,不存在三个数连续比较的a>b>c
判断一个数不等于0,可以省略!=0
3.题目
Tip:对百分号进行转义的时候是使用双百分号%%
三、循环语句
1.分类
| while | do...while | for |
直接跳出循环break 跳过本次循环continue
2.重要结论
1.a % b的结果符号取决于 被除数 a 的符号,则判断一个整数是否是奇数,应该为
if(i%2==1||i%2==-1)
2. 菱形可以通过曼哈顿距离来进行判断 abs(i-cx)+abs(j-cy)<=n/2
#include<cstdio>
#include<iostream>
#include<cmath>
using namespace std;int main(){int n;cin>>n;int cx=n/2,cy=n/2;for(int i=0;i<n;i++){for(int j=0;j<n;j++){if(abs(i-cx)+abs(j-cy)<=n/2){cout<<"*";}else{cout<<" ";}}cout<<endl;}return 0;
}3.关于输入
| 以下表示当输入不为零时继续输入 | ||||
| while(true){ if(!x)break; ... | while(cin>>n&&n){ ... | while(cin>>n,n){ ... | while(scanf("%d",&n)!=-1){ ... | while(~scanf("%d",&n)!){ ... |
scanf在读入字符时,不能过滤空格、回车和制表符,需要手动过滤,给一个相同符号
3.题目
四、数组
1.技巧
(1)一般为了防止越界,会根据要求多开10个空间
(2)数组下标从0开始到N-1
(3)初始化方式
int a[3]={1,2,3};
int a[]={1,2,3};
int a[5]={1,2,3};//没有给出的值默认为0
(4)常见的把数组全部初始化为0的方法:int a[10]={0};
(5)函数内部的数组(局部变量)默认开到栈上,大小为1兆,内容随机,需要初始化;如果想开大空间,放成全局变量,开在堆上,并且默认值全部为0,不需要初始化
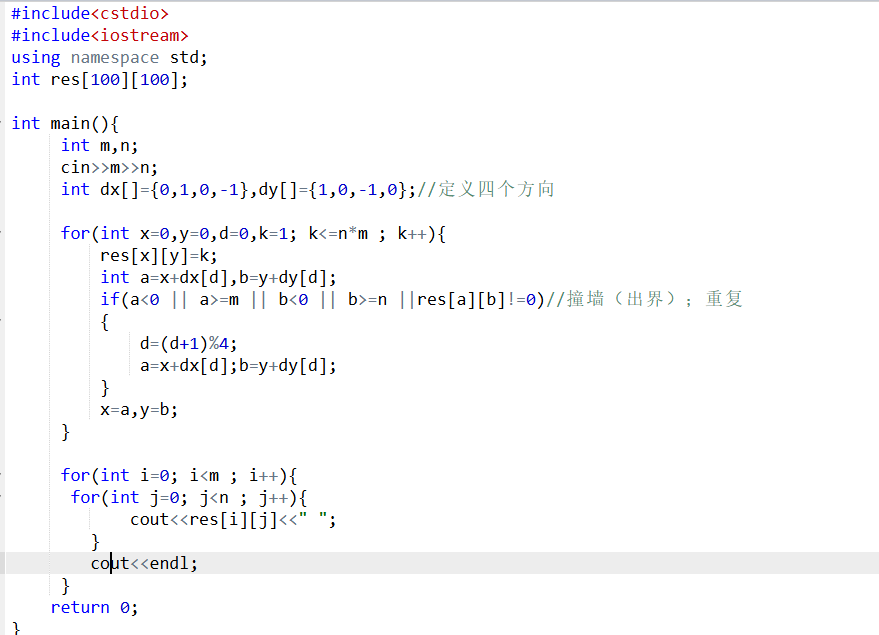
2.高精度N次幂
-
它使用一个数组
a[N]来存储数字的每一位(类似于手工计算乘法的方式) -
初始时数组
a只有一个元素a[0]=1(表示数字1) -
然后进行n次"乘以2"的操作
-
最后反向输出数组中的数字,得到2^n的结果
#include<iostream>
using namespace std;
const int N=30; // 定义数组最大长度为30
int main(){int a[N]={1}; // 初始化数组,a[0]=1,其他元素默认为0int n;cin>>n; // 输入指数nint m=1; // m表示当前数字的位数,初始为1(因为a[0]=1)for(int i=0;i<n;i++){ // 进行n次"乘以2"的操作int t=0; // t用于存储进位for(int j=0;j<m;j++){ // 从低位到高位处理每一位t+=a[j]*2; // 当前位乘以2加上进位a[j]=t%10; // 保留个位数t=t/10; // 计算新的进位}if(t)a[m++]=1; // 如果最后还有进位,增加一位并设置为1}for(int i=m-1;i>=0;i--){ // 从高位到低位输出结果cout<<a[i];}return 0;
}3.二维数组
for(int i=0;i<3;i++){
for(int j=0;j<4;j++){
}
}
4.清空数组&&初始化
在头文件#include<cstring>里面
memset(数组名,初始化值,初始化大小);//大小单位为字节
一般写成memset(a,0,sizeof a);
初始化全为0和-1可以满足赋值
5.复制数组
在头文件#include<cstring>里面
memcpy(新数组,原数组,初始化大小);//大小单位为字节
一般写成memcpy(b,a,sizeof a);
6.题目
Tip:
1.753题也可以通过曼哈顿距离来计算

2.第756题较难
五、字符串
1.字符
与整数的联系---ASCII码
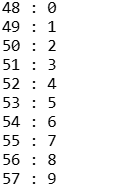
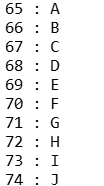
常用ASCII值:A-Z是65-90,a-z是97-122,‘0’-‘9’是48-57

把字符转成整数:比如把ch='0'转换成0,则ch-'0'
2.字符串
字符串就是字符数组加上结束符'\0',可以使用字符串也初始化字符数组。但要注意每个字符串结尾暗藏结束符'\0',因此长度要加1
Tip:
char s[100];
scanf("%s",s);//这里不需要取地址,因为数组名本身就是首元素地址
如果想从第二个位置开始输入元素,那么采用cin>>s+1;
stoi函数:将字符串转换为整数
3.字符数组常见函数
(1)字符串长度:strlen(str);
'\0'的长度不计入长度计算
(2)字符串比较:strcmp(a,b) ---字典序
根据a-b,小于返回-1 ,等于返回0,大于返回1
(3)字符串赋值:strcpy(a,b)
把后面一个复制给前面一个
将数字字符的字符串转化为字面上的整型:atoi函数
4.遍历字符串
string s;
for(int i=0;i<strlen(s);i++){
}为了提高速度可以把长度单独算出来,否则每次 i 判断都要重新计算strlen,可能超时
string s;
for(int i=0,len=strlen(s) ; i<len ; i++){
}
5.遍历字符数组
char s[20];
for(int i=0;s[i];i++){
}
6.string
(1)初始化
string s;//默认为空字符串
string s2=s;//s2是s的副本
string s3="hhhhhhh";//s3是字符串"hhhhhhh"的一个副本
string s4(10,'c');//s4是10个c的字符串
(2)按行输入
若想按行读取则采用
fgets(数组名,读入大小,stdin); //读到字符数组中,且会读进回车
getline(cin,字符串名); //读到字符串中
cin.getline(数组名,读入大小); //读到字符数组中
(3)输出
不能用printf直接输出string,printf("%s",s.c_str());//把字符串转化为字符数组后根据首地址进行输出
若想按行读取则采用
puts(数组名);
printf("%s\n",字符数组);
cout<<str;
(4)判空
s.empty(),如果为空返回true,否则返回false
(5)长度
s.size(),时间复杂度O(1)
(6)比较
== >= <= > < !=
(7)相加(拼接)
string s1="hhhhhhh";
string s2="qqqqqq";
string s3=s1+s2;
支持累加,允许直接加字符字面值及字符串字面值
当把 string 对象和字符字面值及字符串字面值混在一条语句中使用时,必须确保每个加法运算符的两侧的运算对象至少有一个是 string
也就是string s="hello"+" world";是错误的,同理string s="hello"+" world"+s2;也是错误的
(8)子串
substr(起始位置,长度);
如果一直到字符串结尾,可以省略第二个参数
(9)字符流
包含在头文件#include<sstream>
string s,str;
getline(cin,s);
stringstream ssin(s)
ssin>>str;------ 可以理解ssin和cin作用差不多,也不会取空格
(10)字符串最后一个字符
- 查看字符串最后一个字符str.back()
- 删除字符串最后一个字符str.pop_back()
(11)字符串循环移位+子串匹配
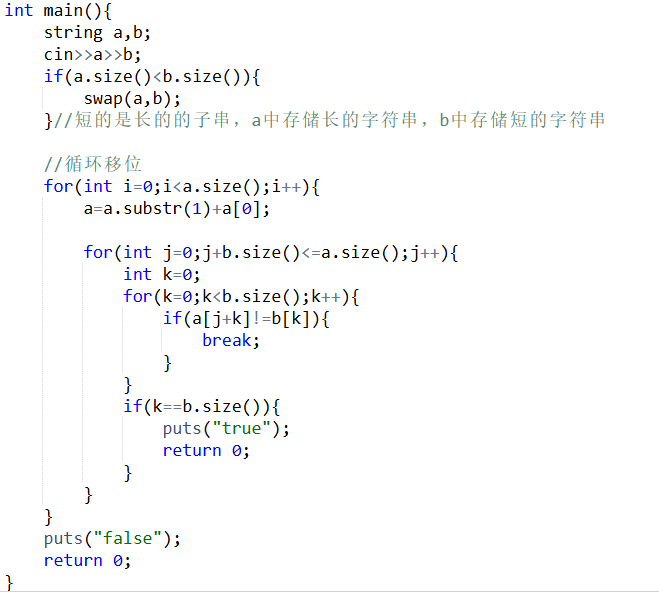
子串匹配也可以使用str.find()函数
7.范围for
string s;

8.第一类双指针算法
模板:

9.题目
Tip:注意后4题!!
六、函数
1.组成
返回值 函数名(函数参数){
return 返回值
}
(1)函数声明时不需要函数体,函数定义时需要函数体。
(2)参数列表可以为空,相当于void
2.变量
全局变量,局部变量,静态变量
static修饰的是静态变量,在一个函数内部只会被创建一次,相当于在函数内部开了一个只有该函数本身可以访问的全局变量,创建在堆上
3.引用
普通形参是无法带到实参中的,但是如果使用引用的话,就可以
这个的实际用处就是如果想传递多个返回值,可以放在形参的引用中返回
4.数组参数
可以使用 a[]传递参数,也可以使用指针*a来定义
二维数组传参时,第一维长度可以省略,其他维不能省略
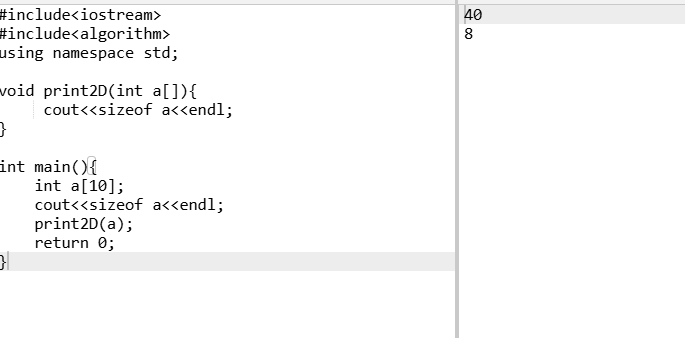
形参中计算a大小实质上是计算数组指针的大小
5.默认参数
int foo(int a,int b=0)
即b不传参,b默认使用0来计算,要求默认值在参数右侧连续
6.题目
Tip:注意后三题
七、类、结构体、指针、引用
1.类和结构体
私有属性private 公有属性 public
结构体默认public,类默认private
2.指针,引用
指针指向变量在内存中的地址,数组名是一种特殊的指针即数组首元素地址
int* p=&a;
引用相当于变量的别名
int& p=a;
3.链表
结点
struct Node{int val;Node* next;Node(int _val):val(_val),next(NULL){} }
初始化
Node* p=new Node(1);
链表的头结点和遍历
Node* head=p; for(Node* i=head;i!=NULL;i=i->next){cout<<i->val<<" "; }
4.题目

Tip:注意 28 87 35 66! 29
八、STL
1.vector
vector:变长数组,支持随机访问,不支持在任意位置O(1)插入,为保证效率,元素删除和增加一般在末尾进行
头文件:#include<vector>
定义:
vector<int> a;
vector<int> b[233];
函数
(1)判空
s.empty(),如果为空返回true,否则返回false
(2)长度
s.size(),时间复杂度O(1)
(3)清空
s.clear()
(4)迭代器
vector<int> a;
vector<int>::iterator it=a.begin();//相当于指针
*a.begin()==a[0]
*a.end==a[a.size()]//越界
相当于左开右闭
(5)遍历
for(int i=0,len=a.size(); i<len ; i++){ }
for(vector<int>::iterator it=a.begin(); i!=a.end() ; i++){ }
for(int ch:a){ }
(6)首尾元素
a.front() == a[0] ==*a.begin()
a.back() == a[a.size()-1]
(7)首尾元素操作
a.push_back(-1); 尾插
a.pop_back(-1); 尾删
2.queue
头文件:#include<queue> 包括循环队列 queue和 优先队列priority queue两个容器
priority_queue<int> a; //大根堆
priority_queue<int,vector<int>,greater<int>> a; //小根堆
priority_queue<pair<int,int>> a;
大根堆重载小于号,小根堆重载大于号
(1)循环队列 queue
| push | pop | front | back |
(2)优先队列priority queue
| push | front() | pop |
3.stack
头文件:#include<stack> 栈
| push | top | pop |
4.deque
头文件:#include<deque> 双端队列
| a.front() | a.back() |
| a.begin() | a.end() |
| a.push_back(-1) | a.pop_back(-1) |
| a.push_front(-1) | a.pop_front(-1) |
| a.clear() | |
5.set
头文件:#include<set> 红黑树
set:元素不能重复
multiset:元素能重复
| a.begin() | a.end() |
| a.insert(); | a.find(); |
| a.lower_bound();找到大于等于x的最小元素的迭代器 | a.upper_bound();找到大于x的最小元素的迭代器 |
| a.erase(x) | a.count(x) |
6.map
头文件:#include<map> ,为key-value映射
priority_queue<pair<int,int>,vector<int>> a;
| a.begin() | a.end() |
| a.insert(); | a.erase(x) |
| a.lower_bound();找到大于等于x的最小元素的迭代器 | a.upper_bound();找到大于x的最小元素的迭代器 |
| a.find(); | a.count(x) |
| a.size() | a.empty() |
7.unordered_set
头文件:#include<unordered_set> 哈希表
unordered_set:元素不能重复
unordered_multiset:元素能重复
8.unordered_map
头文件:#include<unordered_map> ,为key-value映射,无序的
9.bitset
头文件:#include<bitset>
bitset<1000> a,b;
a.set(3);//置为1
a.reset(3);//置为0
a.count()//1的个数
10.pair
头文件:#include<pair> 元组
a.first 首元素 a.second 末元素
make_pair( , )
11.题目

九、位运算和常用库函数
1.位运算
| 与 | 或 | 非 | 异或 | 左移 | 右移 |
| & | | | ~ | ^ | << | >> |
常用操作
(1)求某数x的第k位:x>>k&1
(2)返回某数x的最后一位1:lowbit(x)=x&-x
2.常用库函数
#include<algorithm>
(1)reverse函数------翻转
reverse(a.begin(),a.end());//a为vector
reverse(a,a+5);//a为数组,翻转从a[0]到a[4]的
(2)unqiue函数-----去重
相同元素要放在一起才可以去重,返回值为去重后的尾迭代器,仍为前闭后开
计算去重后元素个数:
给vector去重:int m=unique(a.begin(),a.end())-a.begin()
给数组去重:int m=unique(a+1,a+1+n)-(a+1)
返回去重后数组:a.erase(unique(a.begin(),a.end()),a.begin())
(3)random_shuffle函数----随机打乱
(4)sort函数----排序
从小到大:sort(a.begin(),a.end())
从大到小:sort(a.begin(),a.end(),greater<int>())
排序结构体:在结构体中重载小于号
bool operator <(const Rec &t) const{
}
(5)lower_bound函数/upper__bound函数
用于二分
lower_bound函数:返回大于等于给定元素的最小元素的指针
int index=lower_bound(a.begin(),a.end(),3)-a.begin();
upper__bound函数:返回大于给定元素的最小元素的下标
(6)next_permutation函数
next_permutation的意思是下一个排列,与其相对的是prev_permutation,即上一个排列。我们需要使用全排列的时候就可以直接使用这两个函数,方便又快捷
next_permutaion(起始地址,末尾地址+1)
next_permutaion(起始地址,末尾地址+1,自定义排序)
可以使用默认的升序排序,也可以使用自定义的排序方法