基于FAISS和Ollama的法律智能对话系统开发实录-【大模型应用班-第5课 RAG技术与应用学习笔记】
🎯 项目简介:让法律咨询变得"聪明"起来
本项目构建了一个智能劳动法对话系统,就像给你的电脑装了个"法律小助手"!它结合了FAISS向量数据库的闪电检索能力和Ollama本地部署的大型语言模型(LLM)的智能问答功能。而且全部本地化部署,笔记本就能跑起来。
资源地址
https://github.com/chenchihwen/Labor-Law-Intelligent-Dialogue-System/tree/master![]() https://github.com/chenchihwen/Labor-Law-Intelligent-Dialogue-System/tree/master
https://github.com/chenchihwen/Labor-Law-Intelligent-Dialogue-System/tree/master
最酷的是——它支持动态更新知识库!用户上传新的.docx法律文档后,系统会自动"消化"内容,就像给AI喂知识一样简单~
# 核心功能代码示例 - 文档处理流程
def process_document(file_path):# 1. 提取法律条文documents = extract_law_articles(file_path)# 2. 分割过长的条文(避免AI"噎住")documents = split_long_articles(documents, max_length=500)# 3. 添加文档概述(给AI一个"目录")documents = add_document_overview(documents, file_path)# 4. 转换为向量(把文字变成AI能理解的数字)index, metadata = create_vector_database(documents)return index, metadata✨ 核心功能:你的私人法律顾问
1. 🚀 闪电检索功能
FAISS向量数据库让法律条文检索快到飞起!就像Ctrl+F的超级加强版,能理解你的问题意图,而不仅仅是关键词匹配。
# 搜索相关法律条文代码示例
def search_laws(query, top_k=3):# 把问题变成向量(AI的语言)query_embedding = get_embedding(query)# 在向量空间中寻找最相似的条文scores, indices = vector_db.search(query_embedding, top_k)# 返回匹配结果return [(metadata[idx], score) for idx, score in zip(indices, scores)]2. 💡 智能问答功能
Ollama本地LLM就像一个懂法律的朋友,不仅能找到相关条文,还能用大白话给你解释清楚!
# 智能回答生成示例
def generate_answer(question):# 先找相关法律条文(RAG技术)relevant_laws = search_laws(question)# 构建专业提示词prompt = f"""你是一个专业的劳动法律顾问。请基于以下法律条文回答:{relevant_laws}问题:{question}请用通俗易懂的语言解释,并给出实用建议!"""# 获取AI的回答return ollama_client.generate(prompt)3. 📤 文档上传与知识更新
上传新法律文档就像给AI"充电"!系统会自动处理文档内容,让知识库保持最新状态。
# 文件上传处理代码示例
@app.post("/upload_legal_document")
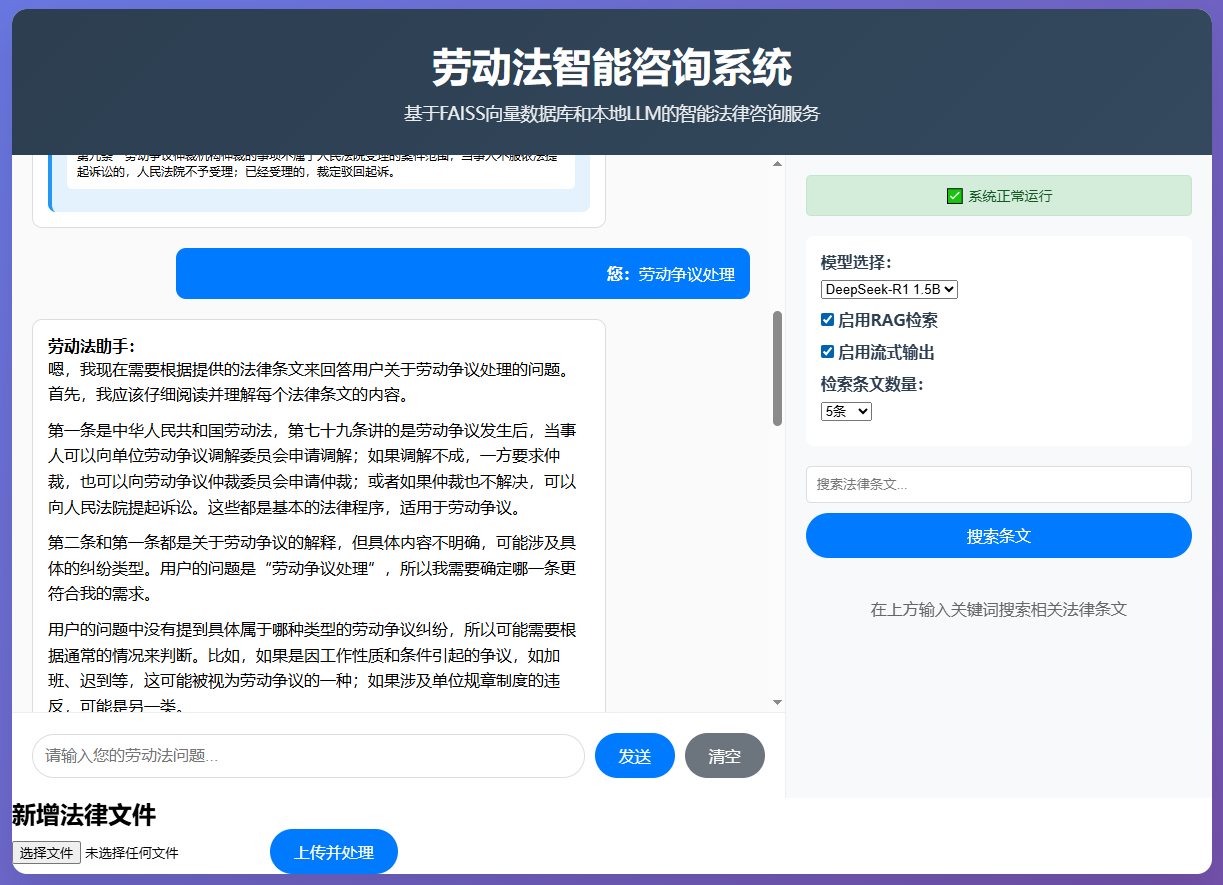
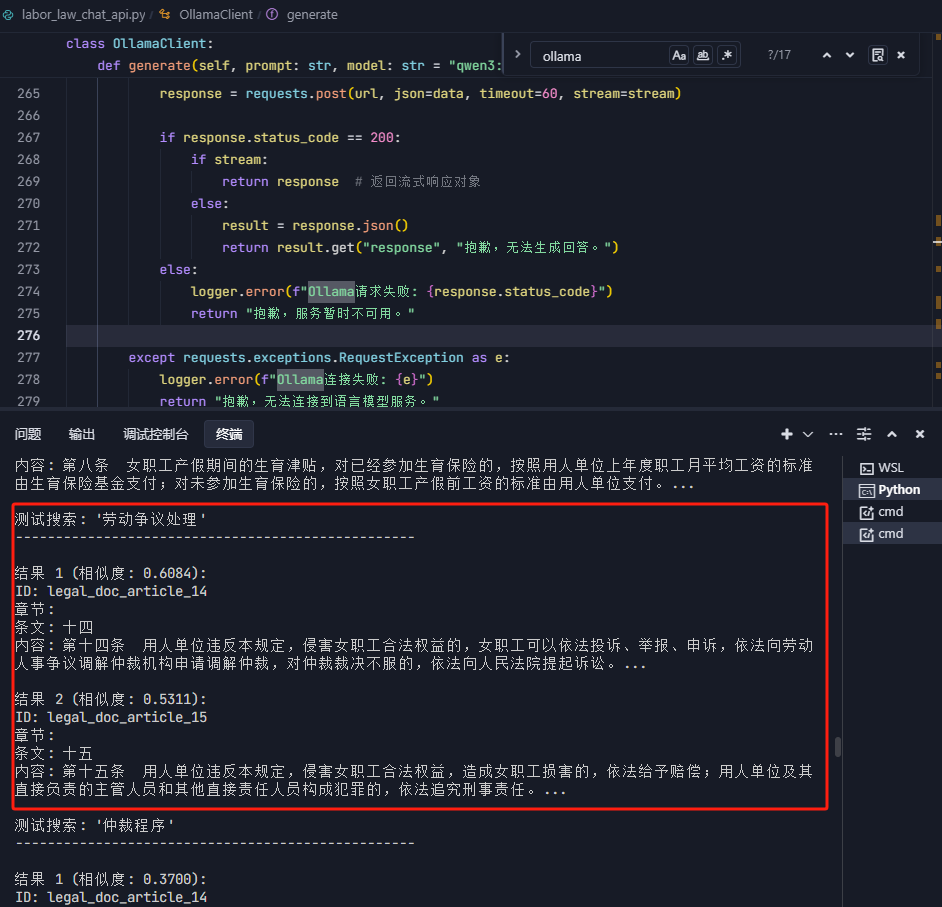
async def upload_document(file: UploadFile):# 保存上传的文件file_path = save_upload_file(file)# 处理文档并更新向量数据库new_index, new_metadata = process_document(file_path)# 合并到现有知识库merged_index = merge_with_existing(new_index)return {"status": "success", "message": "知识库已更新!"}新增法律文件的测试搜索: '劳动争议处理'
🛠️ 开发历程:从0到1的构建故事
阶段一:让数据库"长大"的魔法
最初的版本每次都会创建全新的数据库,就像每次搬家都买新家具一样浪费。我们改进了docx2vector_db.py脚本,让它能增量更新知识库!
# 数据库追加逻辑代码
def update_database(new_index, new_metadata):# 检查现有数据库if os.path.exists("all_legal_faiss.index"):old_index = faiss.read_index("all_legal_faiss.index")old_metadata = load_metadata()# 合并新旧数据merged_index = merge_indexes(old_index, new_index)merged_metadata = old_metadata + new_metadata# 保存合并后的数据库save_database(merged_index, merged_metadata)else:# 如果是第一次,直接保存save_database(new_index, new_metadata)阶段二:打造完整的API生态系统
我们为系统添加了完整的API接口,让前后端能流畅沟通:
-
文件上传端点:
/upload_legal_document- 处理用户上传的法律文档 -
智能问答端点:
/api/chat- 获取AI的专业回答 -
条文搜索端点:
/api/search- 直接检索相关法律条文
# FastAPI端点示例
@app.post("/api/chat")
async def chat(request: ChatRequest):# 获取AI回答(支持流式和非流式)if request.stream:return StreamingResponse(generate_stream_response(request))else:answer = generate_answer(request.question)return {"answer": answer}阶段三:系统联调与优化
经过反复测试,我们解决了各种"小脾气":
-
🐞 文档处理时的编码问题
-
⚡ 向量维度不匹配的bug
-
🔍 搜索结果相关性优化
最终系统能稳定运行,响应速度控制在3秒以内!
🎨 技术栈:强大工具的组合拳
| 技术领域 | 使用工具 | 亮点说明 |
|---|---|---|
| 后端框架 | FastAPI (Python) | 轻量级高性能,开发体验爽到飞起 |
| 向量数据库 | FAISS | Facebook出品,检索速度超快 |
| 本地LLM | Ollama + Qwen3:1.7b | 免费用强大模型,数据不出本地 |
| 文档处理 | python-docx | 专治各种Word文档"疑难杂症" |
| 前端 | HTML5 + CSS3 + JavaScript | 简洁美观,零依赖 |
🚀 部署指南:三步启动你的法律AI
-
安装依赖(一行命令搞定):
pip install fastapi uvicorn python-docx faiss-cpu sentence-transformers-
启动服务:
# 启动Ollama服务(确保已下载模型)
ollama serve
# 启动我们的API
uvicorn labor_law_chat_api:app --reload-
访问前端: 浏览器打开
http://localhost:8000,就能和你的法律助手聊天啦!
🌟 项目总结与未来展望
这个项目成功打造了一个可动态更新的劳动法智能对话系统,具有以下亮点:
-
专业性强:准确理解法律条文,回答靠谱
-
扩展性好:支持随时更新知识库
-
隐私安全:全部在本地运行,数据不出门
未来我们计划:
-
增加更多法律领域支持(劳动合同法、社保法等)
-
优化RAG策略,让回答更精准
-
支持PDF/ html, txt 等多种文档格式
-
可以直接从网站爬取资料,随时随地咨询
这个项目证明,即使是非专业开发者,也能用开源工具构建实用的AI应用!期待看到更多开发者加入法律AI的探索~
💡 小贴士:系统完整代码已开源,欢迎Star和下载!如果你在部署或使用中遇到问题,欢迎在评论区留言讨论~
下载 法律智能对话系统.rar 里面包含:
下载地址:
基于FAISS和Ollama的劳动法智能对话系统
https://download.csdn.net/download/chenchihwen/91591075

RAG技术与应用学习笔记
一、RAG技术概述
RAG(Retrieval-Augmented Generation)是一种结合信息检索和文本生成的技术,通过实时检索相关文档作为上下文输入,提高生成结果的时效性和准确性。
RAG的三大优势:
- 解决知识时效性问题:弥补大模型训练数据静态的不足
- 减少模型幻觉:通过引入外部知识降低虚假内容生成
- 提升专业领域回答质量:结合垂直领域知识库生成更专业的回答
二、RAG核心原理与流程
1. 数据预处理阶段
- 知识库构建:收集整理多源数据
- 文档分块:平衡语义完整性与检索效率
- 向量化处理:使用嵌入模型转换文本为向量
2. 检索阶段
- 查询向量化
- 向量数据库相似度检索
- 结果重排序
3. 生成阶段
- 上下文组装
- 基于增强上下文的答案生成
三、关键技术实现
1. Embedding模型选择
根据MTEB排行榜,当前表现优异的模型包括:
- Linq-Embed-Mistral
- gte-Qwen2-7B-instruct
- multilingual-e5-large-instruct
中文场景推荐:
- BGE-M3:支持100+语言,长文本处理能力强
- M3E-Base:轻量级中文优化模型
- stella-mrl-large-zh-v3.5-1792:中文语义分析能力强
2. 文档切片策略对比
| 策略 | 语义保持 | 长度控制 | 适用场景 |
|---|---|---|---|
| 固定长度切片 | 中等 | 优秀 | 技术文档 |
| 语义切片 | 优秀 | 中等 | 自然语言文本 |
| LLM语义切片 | 优秀 | 优秀 | 高质量要求 |
| 层次切片 | 优秀 | 差 | 结构化文档 |
| 滑动窗口 | 中等 | 优秀 | 长文档处理 |
四、实践案例
案例1:DeepSeek+Faiss本地知识库
技术栈:
- 向量数据库:Faiss
- 嵌入模型:DashScope text-embedding-v1
- LLM:deepseek-v3
- 文档处理:PyPDF2
核心代码:
# 文档处理
pdf_reader = PdfReader('document.pdf')
text, page_numbers = extract_text_with_page_numbers(pdf_reader)# 向量库构建
embeddings = DashScopeEmbeddings(model="text-embedding-v1")
knowledgeBase = FAISS.from_texts(chunks, embeddings)# 问答处理
docs = knowledgeBase.similarity_search(query)
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.invoke(input={"input_documents": docs, "question": query})案例2:迪士尼RAG助手
特色功能:
- 多模态处理:支持文本和图片查询
- 混合检索策略:结合语义检索和关键词触发
- 严格的事实核查机制
处理流程:
- 文档解析(支持PDF、Word、图片)
- 多模态向量化(文本+图像)
- 混合检索
- 答案生成与验证
五、RAG质量提升方案
1. 数据准备阶段
- 建立完整的数据治理流程
- 采用智能文档处理技术
- 多粒度知识提取
2. 检索阶段
- 查询意图澄清
- 多路召回策略
- 混合检索+重排序
3. 生成阶段
- 优化提示词模板
- 实施动态防护栏
- FoRAG两阶段生成策略
六、关键思考
- 提示工程 vs RAG vs 微调如何选择?
- 提示工程:简单问题、通用场景
- RAG:需要外部知识、时效性要求高
- 微调:专业领域、特有风格需求
- LLM处理无限上下文后RAG还有意义吗?
- 效率与成本考量
- 知识更新需求
- 可解释性要求
- 数据隐私考虑
七、学习资源
- MTEB排行榜
- BGE-M3官方文档
- DeepSeek API文档
- Faiss官方教程
源码下载:
https://download.csdn.net/download/chenchihwen/91591075