[论文阅读] 人工智能 + 教学 | 从代码到职业:用机器学习预测竞赛程序员的就业潜力
从代码到职业:用机器学习预测竞赛程序员的就业潜力
论文:From Code to Career: Assessing Competitive Programmers for Industry Placement
arXiv:2508.00772
From Code to Career: Assessing Competitive Programmers for Industry Placement
Md Imranur Rahman Akib, Fathima Binthe Muhammed, Umit Saha, Md Fazlul Karim Patwary, Mehrin Anannya, Md Alomgeer Hussein, Md Biplob Hosen
Subjects: Software Engineering (cs.SE); Programming Languages (cs.PL)
研究背景
在如今飞速发展的科技行业,企业对软件工程师的需求与日俱增。但传统的招聘方式常常面临一个难题:如何准确评估一个程序员的实际能力?以往,学历、简历上的描述可能是主要参考,但这些往往难以真实反映程序员的编码水平和问题解决能力。
就像我们想知道一个人游泳好不好,不能只看他的游泳理论考试分数,更要看他在水里的实际表现一样。对于程序员来说,他们在竞争性编程平台上的表现,就如同在“编程泳池”里的实际演练。Codeforces、LeetCode等平台上的竞赛和解题记录,能直观体现他们的算法思维、调试能力和编码效率,这些都是企业非常看重的素质。
然而,一直以来,缺乏一种有效的工具能将这些平台上的表现与实际就业潜力关联起来。企业可能会错过那些在竞赛中表现出色但缺乏亮眼学历的人才,而程序员也不知道自己的竞赛成绩到底对应着什么样的就业水平。这篇论文正是为了解决这个问题而展开研究的。
主要作者及单位信息
- 作者:Md Imranur Rahman Akib、Fathima Binthe Muhammed、Umit Saha、Md Fazlul Karim Patwary、Mehrin Anannya、Md Alomgeer Hussein、Md Biplob Hosen*
- 单位:
-
- 孟加拉国达卡市萨瓦尔 Jahangirnagar 大学信息技术研究所
-
- 美国马里兰州巴尔的摩县马里兰大学
-
- 通讯作者:Md Biplob Hosen
创新点
- 精准关联竞赛表现与就业潜力:首次系统性地将Codeforces用户的竞赛数据与不同级别软件工程师岗位的就业可能性进行关联分析,实现了从编程表现到职业潜力的直接映射。
- 四级分类模型:创新性地将用户的就业能力分为四个等级,从需要进一步提升到可胜任顶级科技公司岗位,分类更细致,能满足不同场景的需求。
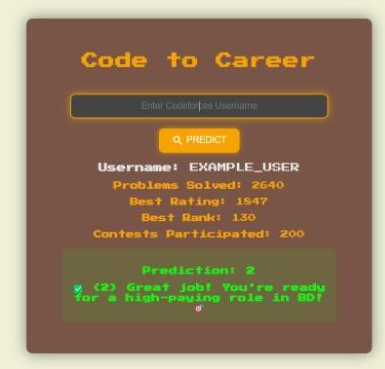
- 实时预测系统:将模型通过Flask实现并部署在Render上,实现了实时预测功能,用户可以快速获取自己的就业潜力评估。
研究方法和思路、实验方法
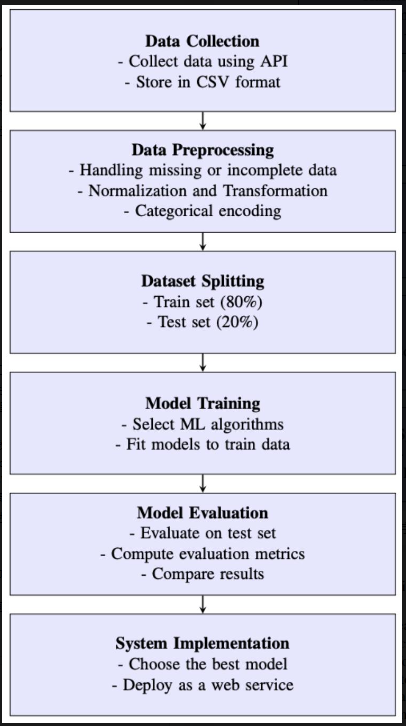
数据收集
- 通过Codeforces API获取用户数据,包括用户评级、提交记录、参与的竞赛信息、问题难度等。
- 将这些数据与公开的用户就业状态标签关联起来,形成用于训练模型的数据集。
- 从数据中提取关键特征,分为四大类:
- 绩效指标:如最佳评级、总竞赛数、总解决问题数等。
- 参与度:如每月竞赛数、每天提交数、活跃天数等。
- 问题解决技能:不同难度和算法类别的问题解决数量。
- 评级趋势:如评级进展和改进率等。
数据预处理
- 处理缺失数据:采用默认值分配、中位数插补、线性插值等方法,对于缺乏有意义活动的记录则直接排除。
- 数据标准化和转换:对不同特征分别采用MinMax归一化、Z-score标准化、对数转换等方法,让数据更适合模型训练;对分类变量进行编码处理。
模型开发与评估
- 选择了三种机器学习模型进行训练和评估:Random Forest分类器、SVM、KNN。
- 采用precision、recall、F1-score、accuracy等多种指标来评估模型性能。
- 经过对比,Random Forest分类器表现最佳,被选为最终模型。
系统实现与部署
- 后端使用Python,前端使用HTML、CSS和JavaScript。
- 利用Scikit-learn训练模型,Flask作为后端API。
- 将系统部署在Render上,实现实时预测功能,同时处理了API调用限制等问题。
主要贡献
-
提供了有效的就业潜力评估工具:该研究构建的模型能根据程序员在Codeforces上的表现,准确预测其就业潜力等级,为企业招聘和程序员自我提升提供了有力参考。
-
验证了竞赛数据的价值:证实了竞争性编程平台上的用户数据与实际就业能力存在强相关性,为利用这类数据进行职业评估提供了依据。
-
搭建了可扩展的系统框架:开发的实时预测系统不仅能应用于当前场景,还为未来扩展到其他技术领域的就业评估奠定了基础。
-
一段话总结:
该研究聚焦于利用Codeforces用户数据预测其软件工程师岗位就业潜力,通过Codeforces API收集数据,处理关键绩效指标,采用Random Forest分类器构建模型,将用户分为四个就业等级。模型经评估效果良好,能有效区分不同技能水平,且通过Flask实现并部署在Render上用于实时预测,为机器学习在职业评估中的应用奠定了基础。
思维导图

详细总结:
一、研究概述
- 研究主题:探究竞争性编程者的活动与其获得不同级别软件工程师职位机会的相关性,预测Codeforces用户的就业潜力。
- 研究意义:为机器学习在职业评估中的应用奠定基础,可扩展到更广泛的技术领域预测就业准备情况。
二、研究背景
- 随着人工智能、数据科学和软件开发等领域的快速发展,对熟练软件工程师的需求大幅增加。
- 企业越来越重视实际编码能力和问题解决能力,而非传统学术 credentials。
- Codeforces等竞争性编程平台成为识别和评估技术人才的关键工具,其中Codeforces因其活跃的全球社区和广泛的算法挑战而脱颖而出。
- 有研究表明,竞赛评级、参与频率和评级进展等绩效指标与更好的就业结果密切相关,将竞争性编程纳入课程的大学毕业生就业率更高。
三、研究方法
- 数据收集
- 通过Codeforces API收集用户数据,包括用户评级、提交结果、问题难度和竞赛元数据等。
- 提取的特征分为四类:绩效指标(如最佳评级、总竞赛数等)、参与度(如每月竞赛数等)、问题解决技能(如不同难度和算法类别的问题解决数量)、评级趋势(如进展和改进率)。
- 数据集包含625个样本, job status分布如下:
| Current Job Status | Count | Percentage |
|---|---|---|
| 0 - Needs further practice | 95 | 15.2% |
| 1 - Entry-level positions | 331 | 53.0% |
| 2 - Mid-level positions | 141 | 22.6% |
| 3 - Ready for top tech companies | 58 | 9.3% |
- 数据预处理
- 处理缺失数据:采用默认值分配、中位数插补、线性插值等方法,排除缺乏有意义活动的记录。
- 数据标准化和转换:对不同特征分别采用MinMax归一化、Z-score标准化、对数转换等方法,对分类变量进行编码。
- 探索性数据分析(EDA)
- 分析了用户的竞赛参与度、问题解决技能和评级趋势等,通过多种可视化方式发现规律,如一致参与会带来更好的评级,特定问题类别更常被解决等。
- 模型开发与评估
- 评估了三种机器学习模型:Random Forest分类器、Support Vector Machine(SVM)、K-Nearest Neighbors(KNN)。
- 采用precision、recall、F1-score、accuracy等指标进行评估。
- 模型性能对比:
| Model | Precision | Recall | F1-score | Accuracy (%) |
|---|---|---|---|---|
| RFRFRF | 0.85 | 0.85 | 0.85 | 88.8 |
| SVM | 0.82 | 0.86 | 0.84 | 84.3 |
| KNN | 0.64 | 0.52 | 0.68 | 64.0 |
- 系统实现与部署
- 后端用Python,前端用HTML、CSS和JavaScript,使用Scikit-learn训练模型,Flask作为后端API,部署在Render上。
- 包含错误处理、API速率限制处理、模型版本控制等功能。
四、研究结果与分析
- Random Forest分类器在所有指标上均优于SVM和KNN,能平衡地预测所有类别。
- 与传统职业预测方法相比,该模型基于可量化数据,更客观,但也存在可能忽视软技能等局限性。
- 案例研究表明,模型能根据用户的评级、解决问题数量和竞赛参与度等评估其职业潜力。
五、结论与展望
- 研究证实了利用Codeforces的竞争性编程数据通过机器学习预测职业结果的潜力,Random Forest分类器表现最佳。
- 存在依赖部分Codeforces API数据、关注范围窄等局限性。
- 未来将整合更多平台数据,加入更多指标,探索更先进模型,提升系统可用性和覆盖范围。
关键问题:
-** 问题1**:该研究采用了哪些机器学习模型进行就业潜力预测,各模型的表现如何?
答案:研究评估了Random Forest分类器、SVM和KNN三种模型。其中,Random Forest分类器表现最佳,准确率达88.8%,precision、recall和F1-score均为0.85;SVM准确率为84.3%,precision 0.82,recall 0.86,F1-score 0.84;KNN表现较差,准确率64.0%,precision 0.64,recall 0.52,F1-score 0.68。
- 问题2:该研究收集的数据特征分为哪几类,具体包含哪些内容?
答案:数据特征分为四类。绩效指标包括最佳评级、总竞赛数、总解决问题数等;参与度通过每月竞赛数、每天提交数、活跃天数衡量;问题解决技能由不同难度和算法类别的问题解决数量表示;评级趋势包括进展和改进率。 - 问题3:该研究开发的系统在实现和部署方面有哪些特点?
答案:系统后端用Python,前端用HTML、CSS和JavaScript,使用Scikit-learn训练模型,Flask作为后端API,部署在Render上;包含错误处理、API速率限制处理(1请求/秒,调用间延迟1秒)、模型版本控制等功能,前端响应式且易于使用,支持实时预测。
总结
这篇论文聚焦于利用Codeforces用户的竞争性编程数据来预测其软件工程师岗位的就业潜力。通过收集数据、提取特征、训练模型等一系列步骤,构建了一个能将用户分为四个就业等级的Random Forest分类器模型,并将其部署为实时预测系统。
研究结果表明,该模型能有效区分不同技能水平的程序员,其中Random Forest分类器准确率达88.8%,表现最佳。这一研究不仅为机器学习在职业评估中的应用提供了实践案例,也为企业招聘和程序员职业发展提供了有价值的工具。
当然,研究也存在一些局限性,比如依赖部分Codeforces API数据、关注范围较窄等。未来可通过整合更多平台数据、加入更多评估指标等方式进一步完善。