论文阅读笔记:《Dataset Condensation with Distribution Matching》
论文阅读笔记:《Dataset Condensation with Distribution Matching》
- 1.解决了什么问题?(Motivation)
- 2.关键方法与创新点(Key Method & Innovation)
- 3.实验结果与贡献 (Experiments & Contributions)
- 4.个人思考与启发
- 主体代码
- 算法逻辑总结
WACV23 github
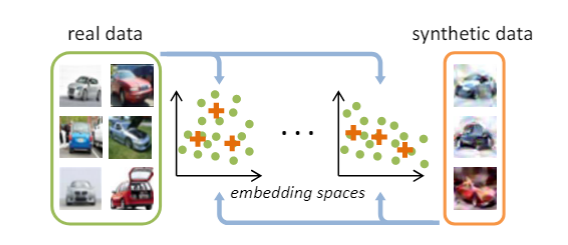
核心思想一句话总结:
用少量可学习的合成图像,通过多组随机网络上的分布匹配(MMD),高效地“蒸馏”出与原始大数据集等价的训练集。
1.解决了什么问题?(Motivation)
训练大型数据集耗时且昂贵,现有“核心集”只能选数据、“蒸馏”常需双层优化都各有局限。本工作旨在:
- 用少量合成图像(每类几十到几百)
- 保持模型在测试集上的性能
- 且避免繁重的bi-level优化
2.关键方法与创新点(Key Method & Innovation)
- 分布匹配视角:首次用最大均值差异(MMD)在特征空间对齐合成与真实数据分布,而非仅作子集选择或梯度匹配。
- 随机网络嵌入:不用预训练模型,随机初始化多个同构网络ψθψ_θψθ作为多种“看法”,增强合成数据集的泛化。
- 单层优化:只对合成图像本身求梯度、SGD更新,网络权重固定,省去双层优化开销。
- 可微分西雅姆增强 (DSA):对真实和合成样本做相同随机变换,提升分布估计稳定性。
3.实验结果与贡献 (Experiments & Contributions)
- 在 CIFAR-10/100、TinyImageNet、ImageNet-1K 上:
- 每类仅 10–50 张合成图即可训练出接近原始数据的模型精度(如 CIFAR-10 10 张时 ≈70%+)。
- 合成速度比 Gradient Matching 提升 ∼45×。
- 下游任务验证:
- 持续学习:更小的记忆库即可保持准确率。
- 神经架构搜索:用代理合成集显著加速搜索且不损失性能。
- 开源代码与可视化结果:每隔若干迭代保存合成图像演化,便于直观对比。
4.个人思考与启发
- 高效vs. 代表性:只匹配特征均值简单有效,但或许忽略高阶统计和类内多样性。
- 生成质量 vs. 训练效果:无需最求”图像好看“,只要”训练有用“;但在某些任务中是否要兼顾真实的视觉特征。
主体代码
''' initialize the synthetic data '''
image_syn = torch.randn(size=(num_classes*args.ipc, channel, im_size[0], im_size[1]), dtype=torch.float, requires_grad=True, device=args.device)
label_syn = torch.tensor([np.ones(args.ipc)*i for i in range(num_classes)], dtype=torch.long, requires_grad=False, deviceargs=.device).view(-1) # [0,0,0, 1,1,1, ..., 9,9,9]if args.init == 'real':print('initialize synthetic data from random real images')for c in range(num_classes):image_syn.data[c*args.ipc:(c+1)*args.ipc] = get_images(c, args.ipc).detach().dataelse:print('initialize synthetic data from random noise')''' training '''# 只更新image_synoptimizer_img = torch.optim.SGD([image_syn, ], lr=args.lr_img, momentum=0.5) # optimizer_img for synthetic dataoptimizer_img.zero_grad()print('%s training begins'%get_time())for it in range(args.Iteration+1):''' Evaluate synthetic data '''if it in eval_it_pool:for model_eval in model_eval_pool:print('-------------------------\nEvaluation\nmodel_train = %s, model_eval = %s, iteration = %d'%(args.model, model_eval, it))print('DSA augmentation strategy: \n', args.dsa_strategy)print('DSA augmentation parameters: \n', args.dsa_param.__dict__)accs = []for it_eval in range(args.num_eval):# 每次用新的随机初始化网络来评估合成集net_eval = get_network(model_eval, channel, num_classes, im_size).to(args.device) # get a random model# 深拷贝合成数据集image_syn_eval, label_syn_eval = copy.deepcopy(image_syn.detach()), copy.deepcopy(label_syn.detach()) # avoid any unaware modification# 测试与评估_, acc_train, acc_test = evaluate_synset(it_eval, net_eval, image_syn_eval, label_syn_eval, testloader, args)accs.append(acc_test)print('Evaluate %d random %s, mean = %.4f std = %.4f\n-------------------------'%(len(accs), model_eval, np.mean(accs), np.std(accs)))if it == args.Iteration: # record the final resultsaccs_all_exps[model_eval] += accs''' visualize and save '''save_name = os.path.join(args.save_path, 'vis_%s_%s_%s_%dipc_exp%d_iter%d.png'%(args.method, args.dataset, args.model, args.ipc, exp, it))image_syn_vis = copy.deepcopy(image_syn.detach().cpu())for ch in range(channel):image_syn_vis[:, ch] = image_syn_vis[:, ch] * std[ch] + mean[ch]image_syn_vis[image_syn_vis<0] = 0.0image_syn_vis[image_syn_vis>1] = 1.0save_image(image_syn_vis, save_name, nrow=args.ipc) # Trying normalize = True/False may get better visual effects.''' Train synthetic data '''# --- 用当前合成数据计算损失并更新(核心:分布匹配) ---# 新的随机网络(视角embedding)net = get_network(args.model, channel, num_classes, im_size).to(args.device) # get a random modelnet.train()# 合成数据训练时冻结网络参数(只优化合成图像)for param in list(net.parameters()):param.requires_grad = False# 多GPU支持,如果使用了DataParallel,embed在module下面embed = net.module.embed if torch.cuda.device_count() > 1 else net.embed # for GPU parallelloss_avg = 0 # 记录各类 loss 平均(后面除法)''' update synthetic data '''# --- 计算合成图像和真实图像在embedding space 上的均值差(即MMD的简化版本)---if 'BN' not in args.model: # for ConvNet 没有batch norm的网络loss = torch.tensor(0.0).to(args.device)for c in range(num_classes):# 每类分别取真实图和合成图img_real = get_images(c, args.batch_real)img_syn = image_syn[c*args.ipc:(c+1)*args.ipc].reshape((args.ipc, channel, im_size[0], im_size[1]))# 可微分增强(DSA):对real/syn做同样的随机变换以稳定分布估计if args.dsa:seed = int(time.time() * 1000) % 100000 # 保证 real 和 syn 用同样的 seedimg_real = DiffAugment(img_real, args.dsa_strategy, seed=seed, param=args.dsa_param)img_syn = DiffAugment(img_syn, args.dsa_strategy, seed=seed, param=args.dsa_param)# 投影到embedding空间output_real = embed(img_real).detach() # 真实特征不方向传播output_syn = embed(img_syn) # 合成特征是要参与梯度的# 均值匹配(特征均值之差平方和)loss += torch.sum((torch.mean(output_real, dim=0) - torch.mean(output_syn, dim=0))**2)else: # for ConvNetBN BatchNorm 的 ConvNeimages_real_all = []images_syn_all = []loss = torch.tensor(0.0).to(args.device)for c in range(num_classes):img_real = get_images(c, args.batch_real)img_syn = image_syn[c*args.ipc:(c+1)*args.ipc].reshape((args.ipc, channel, im_size[0], im_size[1]))if args.dsa:seed = int(time.time() * 1000) % 100000img_real = DiffAugment(img_real, args.dsa_strategy, seed=seed, param=args.dsa_param)img_syn = DiffAugment(img_syn, args.dsa_strategy, seed=seed, param=args.dsa_param)images_real_all.append(img_real)images_syn_all.append(img_syn)# 把每类真实/合成拼成一个大 batch,送进 embedding 一次得到所有类的特征images_real_all = torch.cat(images_real_all, dim=0)images_syn_all = torch.cat(images_syn_all, dim=0)output_real = embed(images_real_all).detach()output_syn = embed(images_syn_all)# reshape 以便按类计算均值,再做平方差累加loss += torch.sum((torch.mean(output_real.reshape(num_classes, args.batch_real, -1), dim=1) - torch.mean(output_syn.reshape(num_classes, args.ipc, -1), dim=1))**2)# 梯度累积与更新 synthetic imagesoptimizer_img.zero_grad()loss.backward()optimizer_img.step()loss_avg += loss.item()loss_avg /= (num_classes) # 梯度累积与更新 synthetic imagesif it%10 == 0:print('%s iter = %05d, loss = %.4f' % (get_time(), it, loss_avg))if it == args.Iteration: # only record the final resultsdata_save.append([copy.deepcopy(image_syn.detach().cpu()), copy.deepcopy(label_syn.detach().cpu())])torch.save({'data': data_save, 'accs_all_exps': accs_all_exps, }, os.path.join(args.save_path, 'res_%s_%s_%s_%dipc.pt'%(args.method, args.dataset, args.model, args.ipc)))算法逻辑总结
- 准备:假设要蒸馏一个3类数据集,每类只想保留5张合成图。
- 多次”看法“:每次随机初始化一个小网络,把真实图和合成图都送进去提取特征。
- 测差异:对每个类别,计算真实图和和冲突在该网络特征空间的平均差距。
- 更新合成图:把所有类别的平均差距累加成一个损失,反向梯度作用到图像像素上,轻微调整它们,让下次”看“更像真实图。
- 重复:多次切换网络、多次迭代,合成图不断逼近真实数据的”分布“。
- 评估:在最终合成图训练几个随机网络,验证它们在测试集上的准确率,确认蒸馏效果