深度学习(鱼书)day10--与学习相关的技巧(后两节)
深度学习(鱼书)day10–与学习相关的技巧(后两节)
一、正则化
机器学习的问题中,过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的未观测数据,也希望模型可以进行正确的识别。
-
过拟合
发生过拟合的原因,主要有以下两个。
• 模型拥有大量参数、表现力强。
• 训练数据少。
我们故意满足这两个条件,制造过拟合现象。为此,要从MNIST数据集原本的60000个训练数据中只选定300个,并且,为了增加网络的复杂度,使用7层网络(每层有100个神经元,激活函数为ReLU)。
import os import syssys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定 import numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from common.multi_layer_net import MultiLayerNet from common.optimizer import SGD(train_x, train_y), (test_x, test_y) = load_mnist(normalize=True)train_x = train_x[:300] train_y = train_y[:300]network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100], output_size=10) optimizer = SGD(lr=0.01)max_epochs = 201 train_size = train_x.shape[0] batch_size = 100 iter_per_epoch = max(train_size / batch_size, 1) epoch_cnt = 0train_loss_list = [] train_acc_list = [] test_acc_list = []for i in range(1000000000):batch_mask = np.random.choice(train_size, batch_size)x_batch = train_x[batch_mask]t_batch = train_y[batch_mask]grads = network.gradient(x_batch, t_batch)optimizer.update(network.params, grads)if i % iter_per_epoch == 0:train_acc = network.accuracy(train_x, train_y)test_acc = network.accuracy(test_x, test_y)train_acc_list.append(train_acc)test_acc_list.append(test_acc)epoch_cnt += 1print("epoch:" + str(epoch_cnt) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc))if epoch_cnt >= max_epochs:breakmarkers = {'train': 'o', 'test': 's'} x = np.arange(max_epochs) plt.plot(x, train_acc_list, marker='o', label='train', markevery=10) plt.plot(x, test_acc_list, marker='s', label='test', markevery=10) plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()
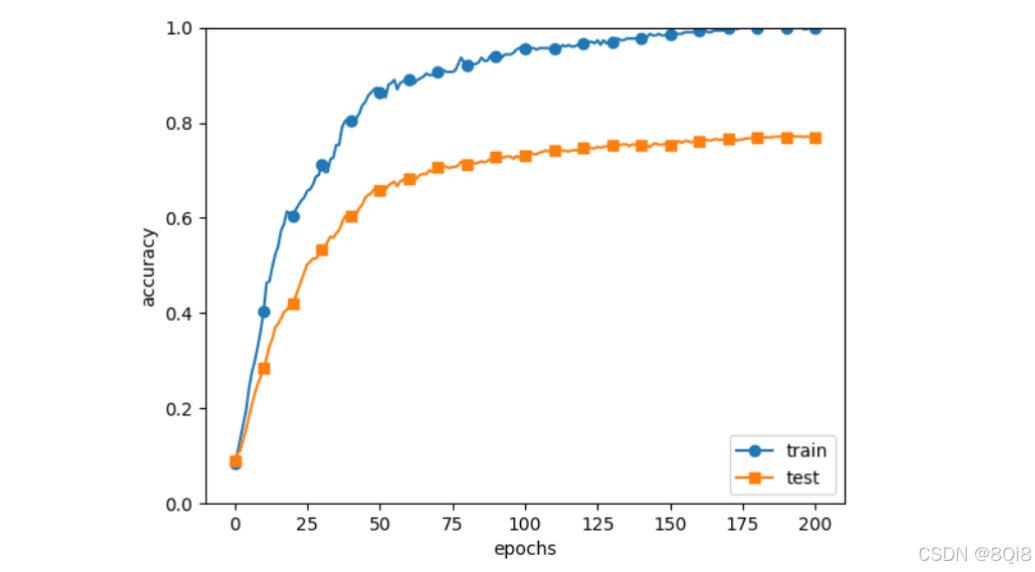
过了 100 个 epoch 左右后,用训练数据测量到的识别精度几乎都为100%。但是,对于测试数据,离100%的识别精度还有较大的差距。如此大的识别精度差距,是只拟合了训练数据的结果。模型对训练时没有使用的一般数据(测试数据)拟合得不是很好。
-
权值衰减
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。
为损失函数加上权重的平方范数(L2范数),就可以抑制权重变大。用符号表示的话,如果将权重记为W,L2范数的权值衰减就是

,然后将这个 加到损失函数上。λ是控制正则化强度的超参数,λ设置得越大,对大的权重施加的惩罚就越重。
开头的1/2是用于将<img src="深度学习(鱼书)day010–与学习相关的技巧
的求导结果变成λW的调整用常量。

对于刚刚进行的实验,应用λ = 0.1的权值衰减,结果如图所示:
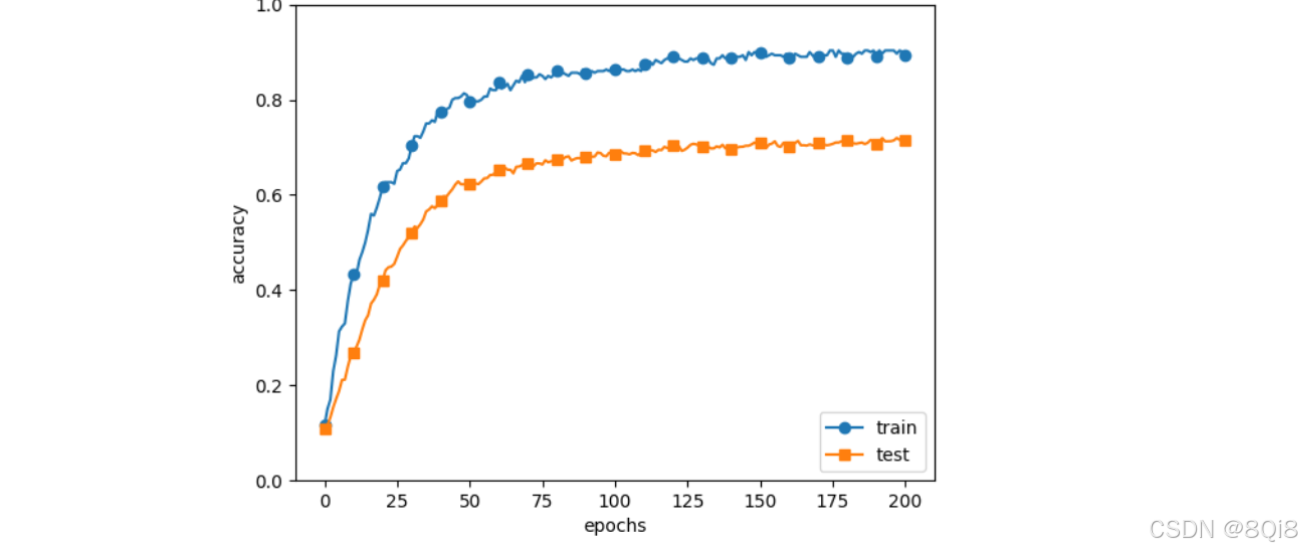
和刚才代码的区别如下:
weight_decay_lambda = 0.1
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100], output_size=10,weight_decay_lambda=weight_decay_lambda)
训练数据的识别精度和测试数据的识别精度之的差距减小了,过拟合受到了抑制。此外,训练数据的识别精度没有达100%(1.0)。
-
Dropout
如果网络的模型变得很复杂,只用权值衰减就难以应对了。在这种情况下,我们经常会使用Dropout方法。
Dropout是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递,如图所示。训练时,每传递一次数据,就会随机选择要删除的神经元。测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出。
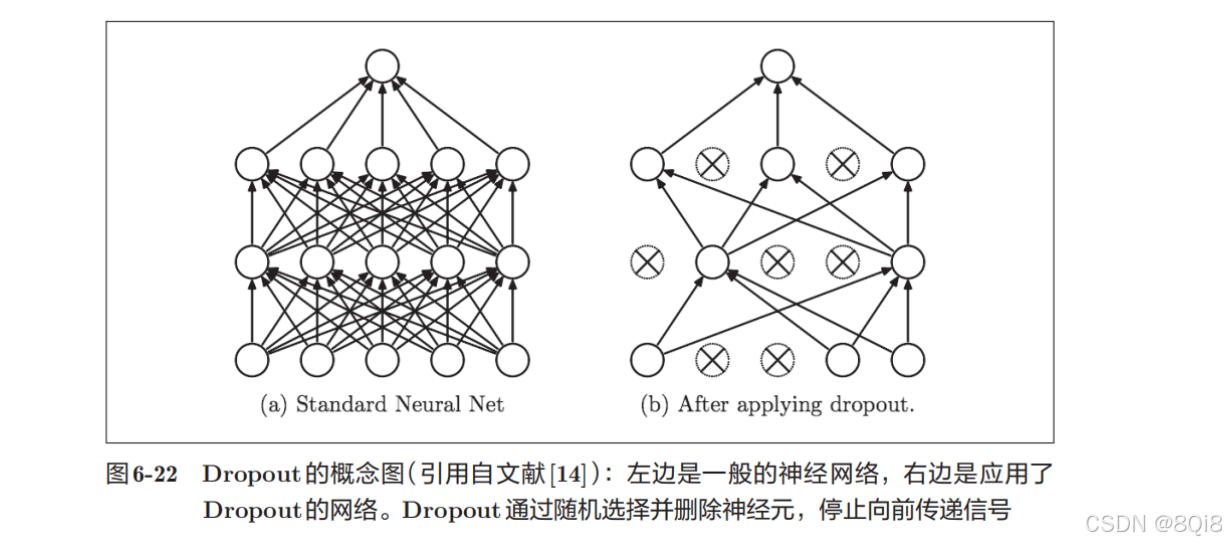
下面我们来实现Dropout。这里的实现重视易理解性。因为训练时如果进行恰当的计算的话,正向传播时单纯地传递数据就可以了(不用乘以删除比例),所以深度学习的框架中进行了这样的实现。
class Dropout:def __init__(self, dropout_ratio=0.5):self.dropout_ratio = dropout_ratioself.mask = Nonedef forward(self, x, train_flg=True):if train_flg:self.mask = np.random.rand(*x.shape) > self.dropout_ratioreturn x * self.maskelse:return x * (1.0 - self.dropout_ratio)def backward(self, dout):return dout * self.mask
每次正向传播时,self.mask中都会以False的形式保存要删除的神经元。self.mask会随机生成和x形状相同的数组,并将值比dropout_ratio大的元素设为True。反向传播时的行为和ReLU相同。也就是说,正向传播时传递了信号的神经元,反向传播时按原样传递信号;正向传播时没有传递信号的神经元,反向传播时信号将停在那里。
我们使用MNIST数据集进行验证,以确认Dropout的效果。
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.trainer import Trainer(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]# 设定是否使用Dropuout,以及比例 ========================
use_dropout = True # 不使用Dropout的情况下为False
dropout_ratio = 0.2
# ====================================================
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,epochs=301, mini_batch_size=100,optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list# 绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from common.optimizer import *class Trainer:"""进行神经网络的训练的类"""def __init__(self, network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='SGD', optimizer_param={'lr':0.01}, evaluate_sample_num_per_epoch=None, verbose=True):self.network = networkself.verbose = verboseself.x_train = x_trainself.t_train = t_trainself.x_test = x_testself.t_test = t_testself.epochs = epochsself.batch_size = mini_batch_sizeself.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch# optimzeroptimizer_class_dict = {'sgd':SGD, 'momentum':Momentum, 'nesterov':Nesterov,'adagrad':AdaGrad, 'rmsprpo':RMSprop, 'adam':Adam}self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)self.train_size = x_train.shape[0]self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)self.max_iter = int(epochs * self.iter_per_epoch)self.current_iter = 0self.current_epoch = 0self.train_loss_list = []self.train_acc_list = []self.test_acc_list = []def train_step(self):batch_mask = np.random.choice(self.train_size, self.batch_size)x_batch = self.x_train[batch_mask]t_batch = self.t_train[batch_mask]grads = self.network.gradient(x_batch, t_batch)self.optimizer.update(self.network.params, grads)loss = self.network.loss(x_batch, t_batch)self.train_loss_list.append(loss)if self.verbose: print("train loss:" + str(loss))if self.current_iter % self.iter_per_epoch == 0:self.current_epoch += 1x_train_sample, t_train_sample = self.x_train, self.t_trainx_test_sample, t_test_sample = self.x_test, self.t_testif not self.evaluate_sample_num_per_epoch is None:t = self.evaluate_sample_num_per_epochx_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]train_acc = self.network.accuracy(x_train_sample, t_train_sample)test_acc = self.network.accuracy(x_test_sample, t_test_sample)self.train_acc_list.append(train_acc)self.test_acc_list.append(test_acc)if self.verbose: print("=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc) + " ===")self.current_iter += 1def train(self):for i in range(self.max_iter):self.train_step()test_acc = self.network.accuracy(self.x_test, self.t_test)if self.verbose:print("=============== Final Test Accuracy ===============")print("test acc:" + str(test_acc))
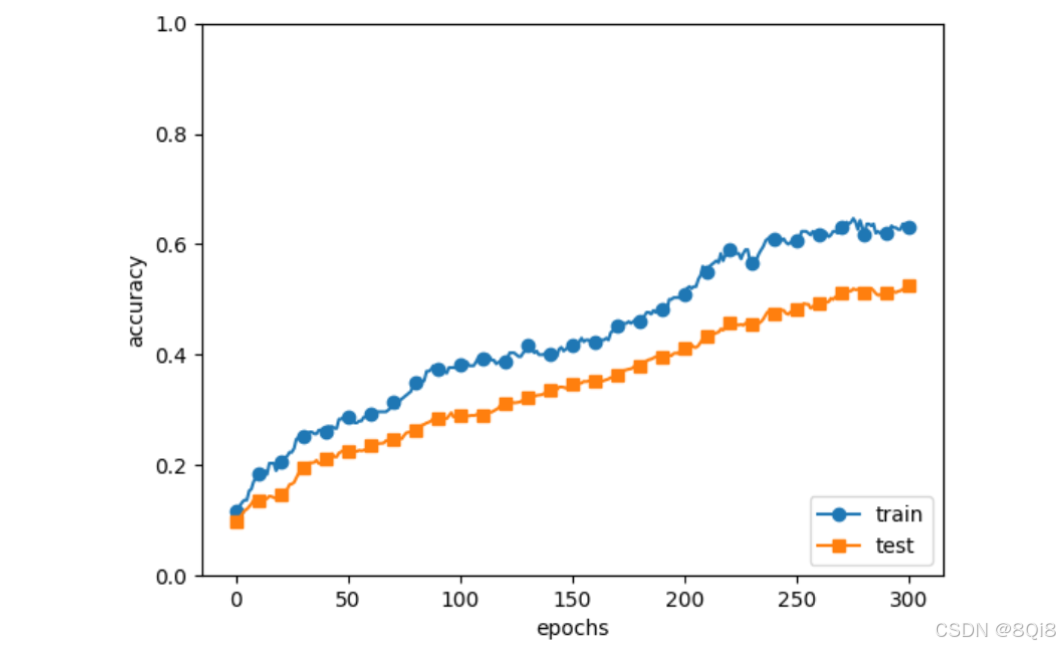
通过使用Dropout,训练数据和测试数据的识别精度的差距变小了。并且,训练数据也没有到达100%的识别精度。像这样,通过使用Dropout,即便是表现力强的网络,也可以抑制过拟合。
通过进行集成学习,Dropout还可以使神经网络的识别精度提高好几个百分点。机器学习中经常使用集成学习。所谓集成学习,就是让多个模型单独进行学习,推理时再取多个模型的输出的平均值。
二、超参数的验证
超参数是指,比如各层的神经元数量、batch大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差。
-
验证数据
我们要对超参数设置各种各样的值以进行验证。这里要注意的是,不能使用测试数据评估超参数的性能。如果使用测试数据调整超参数,超参数的值会对测试数据发生过拟合。
调整超参数时,必须使用超参数专用的确认数据。用于调整超参数的数据,一般称为验证数据(validation data)。
训练数据用于参数(权重和偏置)的学习,验证数据用于超参数的性能评估。为了确认泛化能力,要在最后使用(比较理想的是只用一次)测试数据。
对于MNIST数据集,获得验证数据的最简单的方法就是从训练数据中事先分割20%作为验证数据,代码如下所示
def shuffle_dataset(x, t):"""打乱数据集Parameters----------x : 训练数据t : 监督数据Returns-------x, t : 打乱的训练数据和监督数据"""permutation = np.random.permutation(x.shape[0])x = x[permutation,:] if x.ndim == 2 else x[permutation,:,:,:]t = t[permutation]return x, t(x_train, t_train), (x_test, t_test) = load_mnist() # 打乱训练数据 x_train, t_train = shuffle_dataset(x_train, t_train) # 分割验证数据 validation_rate = 0.20 validation_num = int(x_train.shape[0] * validation_rate)x_val = x_train[:validation_num] t_val = t_train[:validation_num] x_train = x_train[validation_num:] t_train = t_train[validation_num:]分割训练数据前,先打乱了输入数据和教师标签。这是因为数据集的数据可能存在偏向。
-
超参数的最优化
进行超参数的最优化时,逐渐缩小超参数的“好值”的存在范围非常重要。所谓逐渐缩小范围,是指一开始先大致设定一个范围,从这个范围中随机选出一个超参数(采样),用这个采样到的值进行识别精度的评估;然后,多次重复该操作,观察识别精度的结果,根据这个结果缩小超参数的“好值”的范围。
超参数的范围只要“大致地指定”就可以了。所谓“大致地指定”,是指像 0.001(10^−3 )到1000(10^3 ) 这样,以“10的阶乘”的尺度指定范围(也表述为“用对数尺度(log scale)指定”)。
在超参数的最优化中,要注意的是深度学习需要很长时间(比如,几天或几周)。因此,在超参数的搜索中,需要尽早放弃那些不符合逻辑的超参数。于是,在超参数的最优化中,减少学习的epoch,缩短一次评估所需的时间是一个不错的办法。
-
总结:
步骤0
设定超参数的范围。
步骤1
从设定的超参数范围中随机采样。
步骤2
使用步骤1中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将epoch设置得很小)。
步骤3
重复步骤1和步骤2(100次等),根据它们的识别精度的结果,缩小超参数的范围。
在超参数的最优化中,如果需要更精炼的方法,可以使用贝叶斯最优化(Bayesian optimization)。
-
-
超参数最优化的实现
我们使用MNIST数据集进行超参数的最优化。这里我们将学习率和**控制权值衰减强度的系数(下文称为“权值衰减系数”)这两个超参数的搜索问题作为对象。
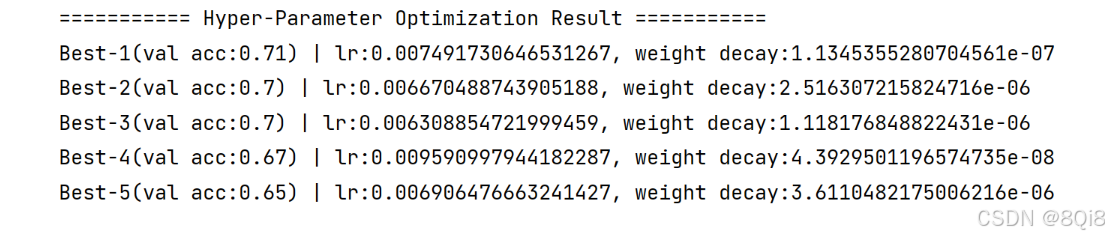
import sys, os sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定 import numpy as np import matplotlib.pyplot as plt from dataset.mnist import load_mnist from common.multi_layer_net import MultiLayerNet from common.util import shuffle_dataset from common.trainer import Trainer(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)# 为了实现高速化,减少训练数据 x_train = x_train[:500] t_train = t_train[:500]# 分割验证数据 validation_rate = 0.20 validation_num = int(x_train.shape[0] * validation_rate) x_train, t_train = shuffle_dataset(x_train, t_train) x_val = x_train[:validation_num] t_val = t_train[:validation_num] x_train = x_train[validation_num:] t_train = t_train[validation_num:]def __train(lr, weight_decay, epocs=50):network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],output_size=10, weight_decay_lambda=weight_decay)trainer = Trainer(network, x_train, t_train, x_val, t_val,epochs=epocs, mini_batch_size=100,optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)trainer.train()return trainer.test_acc_list, trainer.train_acc_list# 超参数的随机搜索====================================== optimization_trial = 100 results_val = {} results_train = {} for _ in range(optimization_trial):# 指定搜索的超参数的范围===============weight_decay = 10 ** np.random.uniform(-8, -4)lr = 10 ** np.random.uniform(-6, -2)# ================================================val_acc_list, train_acc_list = __train(lr, weight_decay)print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)results_val[key] = val_acc_listresults_train[key] = train_acc_list# 绘制图形======================================================== print("=========== Hyper-Parameter Optimization Result ===========") graph_draw_num = 20 col_num = 5 row_num = int(np.ceil(graph_draw_num / col_num)) i = 0for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)plt.subplot(row_num, col_num, i+1)plt.title("Best-" + str(i+1))plt.ylim(0.0, 1.0)if i % 5: plt.yticks([])plt.xticks([])x = np.arange(len(val_acc_list))plt.plot(x, val_acc_list)plt.plot(x, results_train[key], "--")i += 1if i >= graph_draw_num:breakplt.show()按识别精度从高到低的顺序排列了验证数据的学习的变化:
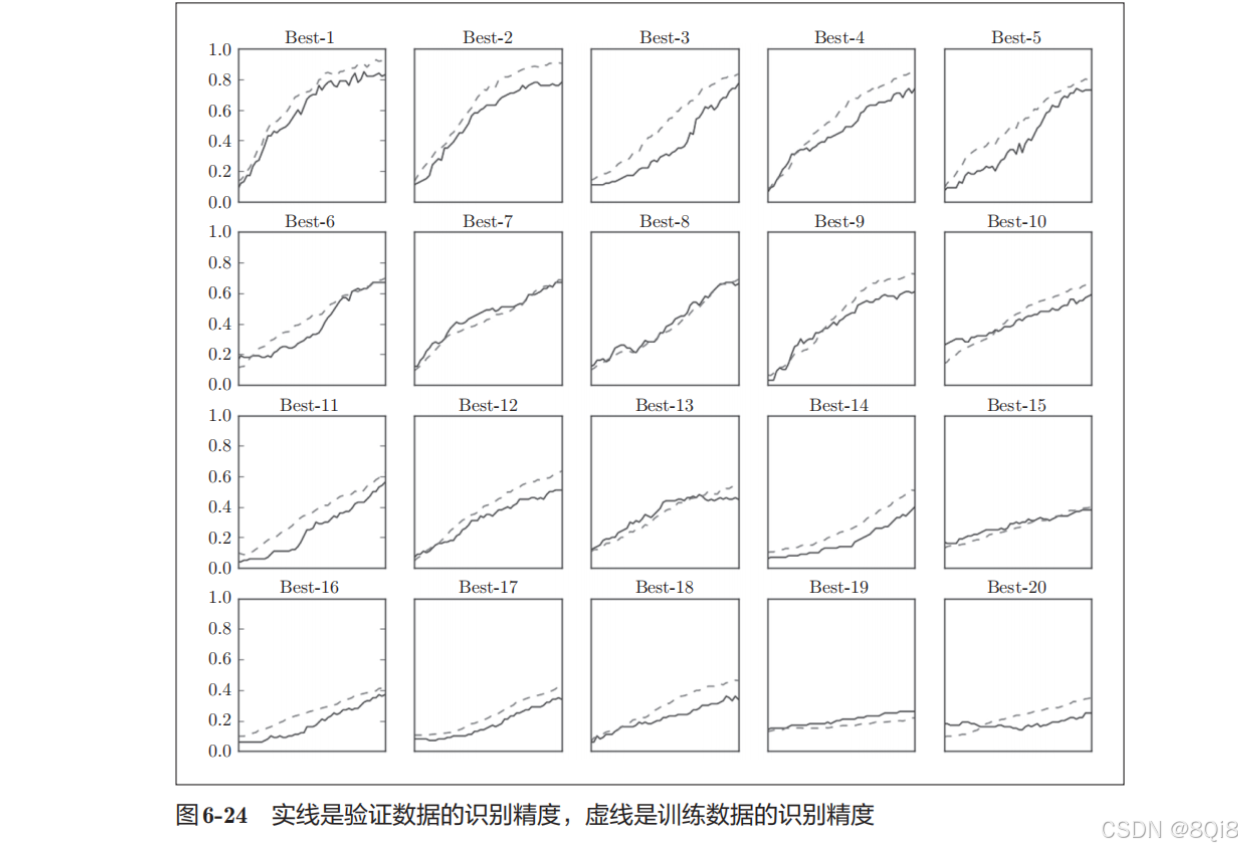
直到“Best-5”左右,学习进行得都很顺利。学习率在0*.001到0.01、权值衰减系数在10−8 到10−*6 之间时,学习可以顺利进行。像这,观察可以使学习顺利进行的超参数的范围,从而缩小值的范围。然后,在这个缩小的范围中重复相同的操作。这样就能缩小到合适的超参数的存在范围,然后在某个阶段,选择一个最终的超参数的值。