后端研发转型爬虫实战:Scrapy 二开爬虫框架的避坑指南
文章目录
- 一、前言
- 二、项目架构说明
- 2.1 Speedy 爬虫框架
- 2.1.1 Scrapy 网络爬虫框架
- 2.1.2 生产者-消费者模式
- 2.1.3 消息消费过程说明
- 2.2 项目结构
- 2.2.1 Redis 配置
- 2.2.2 MySQL 配置
- 2.3 python 和 nodejs 版本要求
- 三、爬虫实现
- 3.1 需求表结构设计
- 3.2 创建project
- 3.3 写爬虫程序
- 3.3.1 数据库表 items 维护
- 3.3.2 任务队列 task_queues 维护
- 3.3.3 编写 spider 爬虫实现
- 3.3.3.1 debug_task 与 Debug 模式
- 3.3.3.2 start_task
- 3.3.3.3 parse
- 3.3.3.4 Debug 模式运行截图
- 3.3.4 生产者调度任务 job 维护
- 3.3.5 任务部署配置
- 3.4 本地测试爬虫程序
- 3.5 失败队列处理
- 四、发布任务到线上服务器
- 五、规范
- 六、技巧
一、前言
近期业务爬虫需求激增,现有爬虫团队资源紧张,需要后端研发同学协同支持。本文基于公司内部基于Scrapy二次开发的爬虫框架(Speedy)实战经验,分享爬虫项目中的核心开发模式、常见问题解决思路和实用技巧。
无论你是临时支援的后端研发,还是对爬虫技术感兴趣的同学,这些实战经验都能帮助你快速理解爬虫开发的关键要点,提高开发效率。
二、项目架构说明
爬虫项目架构使用 Speedy,项目名称自定义。
2.1 Speedy 爬虫框架
项目框架 Speedy 是基于 Scrapy 进行二开的爬虫框架。非开源且不对外开放的,没有官方网站。资料可以通过 Scrapy 间接学习。

2.1.1 Scrapy 网络爬虫框架
Scrapy 中文文档
Scrapy是一个快速、高效率的网络爬虫框架,用于抓取web站点并从页面中提取结构化的数据。 Scrapy被广泛用于数据挖掘、监测和自动化测试
2.1.2 生产者-消费者模式
(1)Speedy 框架采用生产者-消费者模式
生产者发送消息到 redis 中,消费者监听消费。增加失败重试兼容网络波动等场景;
使用 ack 机制避免丢失消息;
重试后仍失败的消息会放到 dlq 队列中,通过监控告警通知到研发负责人,人工处理。
2.1.3 消息消费过程说明
(1)调度平台 rundeck 触发定时任务,调用生产者添加爬虫任务体消息到 redis


(2)消费者监听 redis 中的消息,spider 进行消费
(3)spider 爬虫程序执行发出请求 request,接收响应 parse,存储响应结果

2.2 项目结构
● conf : 包含项目的配置文件,如基础配置、报警机器人配置、数据库会话配置、MySQL配置、Redis配置和任务队列工具配置。
● monitor_client : 监控客户端,包含监控指标、Redis字典和相关值的配置文件。
● scheduler : 调度器模块,包含后端实现、处理逻辑、监控、任务队列管理、令牌桶算法和工具函数。
● sites : 各个站点的具体实现,每个站点包含初始化文件、items定义、jobs脚本、中间件、管道、设置、爬虫、任务队列和工具函数。
● speedy_settings : speedy配置。
● third_party : 第三方库或工具。
● utils : 工具模块。
2.2.1 Redis 配置
● 文件路径:conf/redis.py
CONNECTION = {'host': '127.0.0.1','port': 6379,'db': 2,'password': ''
}
2.2.2 MySQL 配置
● 文件路径:conf/mysql.py
定义多数据源 mysql_crawL_db、mysql_service_data
import platformsystem = platform.system()def create_mysql_config(host=None, port=None, user=None, password=None):return {'type': 'mysql','conf': {'host': host,'port': port,'user': user,'password': password,'max_op_fail_retry': 3,'timeout': 60}}mysql_crawL_db = create_mysql_config(host='192.168.8.101', port=3306, user='root', password='root'
)
mysql_service_data = create_mysql_config(host='192.168.8.102', port=3306, user='root', password='root'
)
2.3 python 和 nodejs 版本要求
(1)建议安装 Anaconda,可以管理多版本 python 环境
- python --version
Python 3.7.1 - node -v
v20.19.3
(2)然后拉取项目到本地,执行命令拉取所有依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
三、爬虫实现
3.1 需求表结构设计
(1)此处以抓取罗盘达人今日直播间信息为例。
今日直播卡片数据请求 base_url 为https://compass.jinritemai.com/compass_api/author/live/live_detail/today_live_room?

(2)响应 json 结果如下
{"data": {"card_list": [{"incr_fans_cnt": {"unit": "number","value": 161},"live_duration": "8小时51分钟","live_id": "753xxx35","live_status": true,"live_title": "欢迎来到xxx直播间","operation": {"live_app_id": 2079,"live_id": "753xxx35","show_big_screen": true,"show_detail": true},"pay_order_cnt": {"unit": "number","value": 404},"pay_order_gmv": {"unit": "price","value": 100000},"start_time": "2025/07/31 05:58","watch_ucnt": {"unit": "number","value": 16364}},{"incr_fans_cnt": {"unit": "number","value": 4655},"live_duration": "6天20小时","live_id": "753xxx40","live_status": false,"live_title": "欢迎来到xxx直播间","operation": {"live_app_id": 2079,"live_id": "753xxx40","show_big_screen": true,"show_detail": true},"pay_order_cnt": {"unit": "number","value": 8290},"pay_order_gmv": {"unit": "price","value": 1000000},"start_time": "2025/07/24 05:04","watch_ucnt": {"unit": "number","value": 244988}}],"has_more": false,"show": false},"msg": "","st": 0
}
(3)今日直播表结构设计 dy_live_room_info_test
只记录直播间唯一标识、直播状态基本信息,不记录粉丝数量、成交金额信息。
CREATE TABLE `dy_live_room_info_test` (`id` bigint NOT NULL AUTO_INCREMENT,`nick_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '抖音号名称',`aweme_id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '抖音号',`in_living` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '是否直播,1:直播,0: 未直播',`live_id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '直播间id',`live_title` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '直播间名称',`live_room_start_time` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '直播开始时间',`live_duration` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '持续时长',`bd_create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,`bd_update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `unique_live_start_date` (`live_id`,`live_room_start_time`) USING BTREE COMMENT 'live_id 和 live_room_start_time 的唯一组合',KEY `bd_create_time` (`bd_create_time`) USING BTREE,KEY `bd_update_time` (`bd_update_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
3.2 创建project
一般建议一个服务平台,可以对应创建一个 project。
同一个平台内部的 token、cookie 是互通的,便于封装方法,抽取公共实现;和其他服务平台做好业务隔离。
(1)创建project,名称为 dy_luopan。
python -m speedy startproject --project-name dy_luopan

(2)在 project 下创建具体的 spider,名称为 live_room
python -m speedy genspider --project-name dy_luopan --spider-name live_room

3.3 写爬虫程序
3.3.1 数据库表 items 维护
● 文件路径
sites/dy_luopan/items.py
● 基于 BaseItem 写 DyLiveRoomInfoDataItem
类似于Java中的mode、entity 层。
需要指定数据源 session,数据表名称、字段、类型及校验。
BaseItem 是自动生成的,大部分不用修改。可以按需改下插入模式,比如这里改为 speedy.ItemMode.REPLACE
import speedy
from speedy.config import config
from conf.dbsession import mysql_crawL_db_sessiondb_session = config.get_db_session('tidb')class BaseItem(speedy.Item):# 数据库名称DATABASE = 'dy_luopan'# 分组,用于文档生成是归类分组GROUP = None# 是否可导出用于生成sqlEXPORT_DB = True# 是否可导出用于文档EXPORT_DOC = True# 表名称TABLE = None# 插入模式: ItemModeMODE: speedy.ItemMode = speedy.ItemMode.REPLACE# 压缩字段, 只支持tidbCOMPRESS_FIELDS = []# 主键字段,如果没有在fields里会默认其为自增主键PRIMARY_KEY = []# 主键是否自增PRIMARY_KEY_AUTO_INC = False# 联合主键UNIQUE_KEY = []# 主键KEY = []# 数据库类型DB_TYPE = 'tidb'# curd.Session对象session = db_session# 快照时间snapshot_time = speedy.TimestampField(required=True, comment='快照时间')class DyLiveRoomInfoDataItem(BaseItem):session = mysql_crawL_db_sessionTABLE = 'dy_live_room_info_test'nick_name = speedy.StringField(max_length=255, comment='抖音号名称')aweme_id = speedy.StringField(max_length=50, comment='抖音号')in_living = speedy.StringField(max_length=10, comment='是否直播,1:直播,0: 未直播')live_id = speedy.StringField(max_length=50, comment='直播间id')live_title = speedy.StringField(max_length=255, comment='直播间名称')live_room_start_time = speedy.StringField(max_length=100, comment='直播开始时间')live_duration = speedy.StringField(max_length=255, comment='持续时长')pass
3.3.2 任务队列 task_queues 维护
(1)当前 project 的 redis db 配置
● 文件路径
sites/dy_luopan/task_queues/init.py
● 使用不同的db,做好业务隔离
CONNECTION.update({'db': 7
})
redis_client = Connection(**CONNECTION).client()
(2)具体爬虫任务的队列配置
● 文件路径
sites/dy_luopan/task_queues/live_room.py
● 指定spider监听消费的队列配置
创建 spider 时已通过模板自动创建,按需修改配置。
GROUPS_SETTINGS = {'name': 'live_room',# 基础队列ID# 'base_queue_id': 'live_room',# 优先级列表# 'priority_list': [0, 1, 2],# 每秒并发数# 'rate': 100,# ack超时(单位ms)# 'ack_timeout': 180000,# 最大重试次数# 'max_retry': 5,# 设置过滤器# 'filter': 'live_room_filter'
}# FILTERS_SETTINGS = {# 'id': 'live_room_filter',# 'type': 'set', # 'set' or 'bloom'# 'size': 10000000, # bloom过滤器需要设置最大过滤数# 'expires': '0 12 * * *', # 过滤器重置时间, crontab
# }
3.3.3 编写 spider 爬虫实现
● 文件路径
sites/dy_luopan/spiders/live_room.py
● 编写爬虫程序
分析爬取地址 url,分析请求参数,封装 url 的 param。
分析 response 结果,解析 response.text,维护目标记录入库。
3.3.3.1 debug_task 与 Debug 模式
只写必要的信息,比如账号信息、数据筛选时间范围、业务类型标识等。
避免 body 过大,body 体在实际运行中,会作为消息内容,发送到 redis 中。body 过大不便观测数据排查问题。
def debug_task(self):body = {'douyin_id': 'lxxx17','douyin_name': '抖音号名称'}return {'body': body}
(1)debug模式
debug_task()方法里写debug模式调试下的请求体
当指定 BASE_SETTINGS[‘DEBUG’] = True 时,启用 debug 模式。
● debug_task
debug_task() 的请求体直接发送到 start_task() 下。
● start_task
start_task() 基于请求体的账号查询业务表获取到 cookie、token 信息,封装请求参数访问 api。
● parse
parse() 接收响应的结果。判断业务响应码是否为0,不为0抛出异常。全局拦截后触发告警通知到开发负责人。
业务码正常响应符合预期时,读取响应体中的数据,然后封装 item 的字典数据,通过 yield 批量入库。
(2)非debug模式
当指定 BASE_SETTINGS[‘DEBUG’] = False 时,不启用 debug 模式。
生产者生产消息发送到 redis,spider监听队列消息,进行消费。
spider通过任务队列组获取的task都会调用 start_task() 方法开始爬虫处理。
3.3.3.2 start_task
task 会通过 meta 默认传递,在 task 中包含请求体的所有信息
通过索引获取到请求体中账号,然后查询业务表获取账号的 cookie,维护到 headers,发出请求
self.Request()def start_task(self, task):task_body = task['body']douyin_id = task_body['douyin_id']lp_list = mysql_service_data_session.filter(tb_dy_baiying_luopan_table,filters=[('=', 'douyin_id', douyin_id)],fields=['douyin_id', 'douyin_name', 'luopan_dt'])headers = core_headers.copy()headers['referer'] = 'https://compass.jinritemai.com/shop/live-detail'headers['Cookie'] = lp_list[0]['luopan_dt']yield self.Request(url=self.today_live_url, headers=headers)
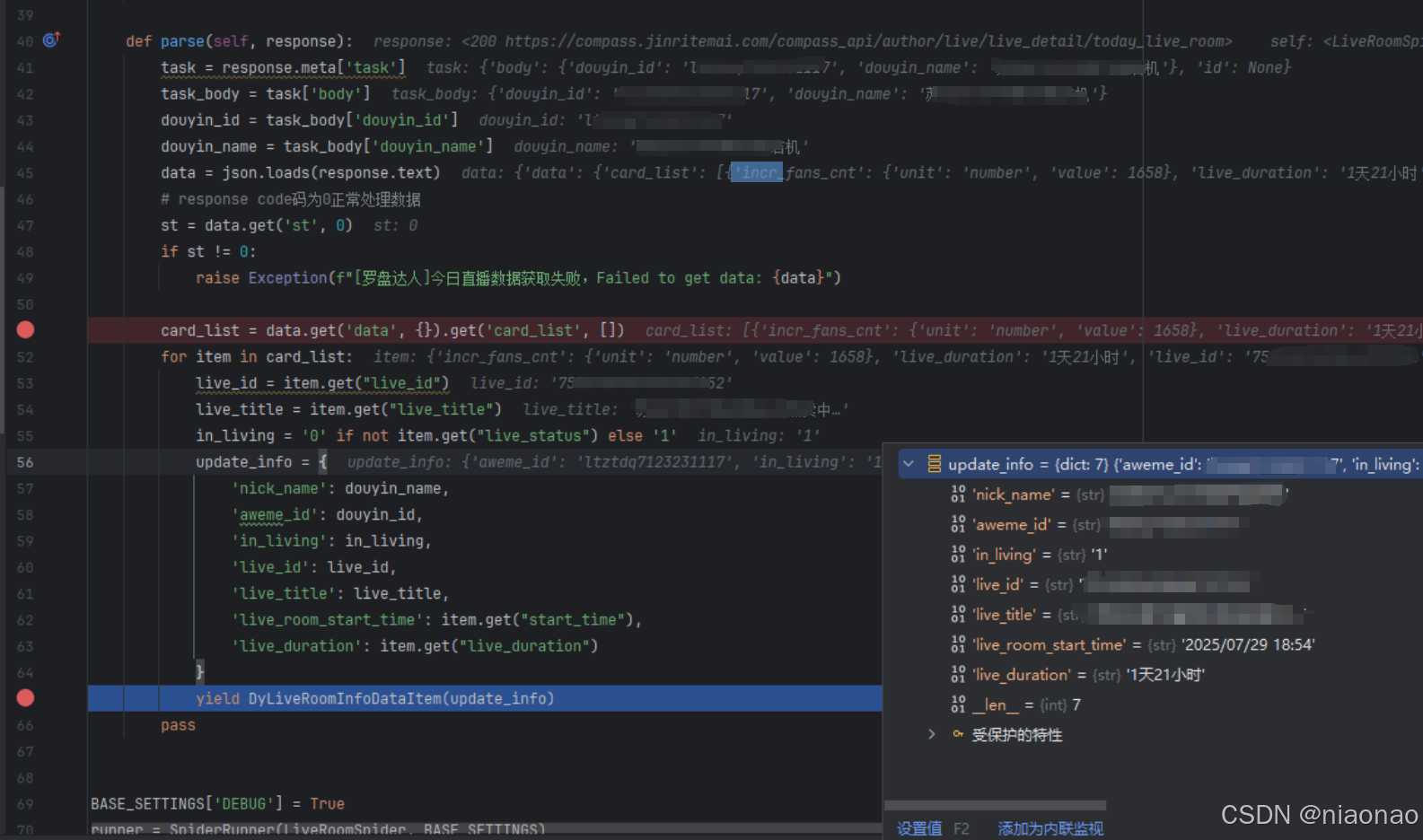
3.3.3.3 parse
parse 接收 Request 的响应
针对普通的 json 响应结果,使用 response.text 取出即可
解析结果中的目标数据,封装为字典 update_info:{}
通过 yield XxxItem(update_info) 批量入库
def parse(self, response):task = response.meta['task']task_body = task['body']douyin_id = task_body['douyin_id']douyin_name = task_body['douyin_name']data = json.loads(response.text)# response code码为0正常处理数据st = data.get('st', 0)if st != 0:raise Exception(f"[罗盘达人]今日直播数据获取失败,Failed to get data: {data}")card_list = data.get('data', {}).get('card_list', [])for item in card_list:live_id = item.get("live_id")live_title = item.get("live_title")in_living = '0' if not item.get("live_status") else '1'update_info = {'nick_name': douyin_name,'aweme_id': douyin_id,'in_living': in_living,'live_id': live_id,'live_title': live_title,'live_room_start_time': item.get("start_time"),'live_duration': item.get("live_duration")}yield DyLiveRoomInfoDataItem(update_info)pass
3.3.3.4 Debug 模式运行截图
Debug 模式运行日志
Debug 模式不会真正的入库,只是打印日志。

3.3.4 生产者调度任务 job 维护
● 文件路径
sites/dy_luopan/jobs/add_task.py
● 编写添加任务的方法
from conf.dbsession import mysql_service_data_session
from sites.dy_luopan.task_queues import task_queue_manager
from sites.dy_luopan.utils.common import tb_dy_baiying_luopan_table
from speedy import Jobclass DyLuopanJob(Job):name = 'dy_luopan'@staticmethoddef add_live_room_task():my_group = task_queue_manager.get('live_room')lp_list = mysql_service_data_session.filter(tb_dy_baiying_luopan_table,fields=['douyin_id', 'douyin_name'])for lp_info in lp_list:body = {'douyin_id': lp_info['douyin_id'],'douyin_name': lp_info['douyin_name']}my_group.publish(0, body)print(f'添加任务数量:{len(lp_list)}')if __name__ == "__main__":DyLuopanJob().run()
3.3.5 任务部署配置
● 文件路径
sites/dy_luopan/deployments.yml
● 编写任务调度配置文件
维护消费者和生产者及调度频率
group: sites/dy_luopanservices:
- name: live_roomreplicas: 1spider: sites.dy_luopan.spiders.live_roomjobs:
- name: add_live_room_tasktimeout: 5mretry: 0cron: '0 * * * *'script: sites.dy_luopan.jobs.add_task add_live_room_taskjob_emails: ['xxx@qq.com']
3.4 本地测试爬虫程序
job:sites/dy_luopan/jobs/add_task.py
spider:sites/dy_luopan/spiders/live_room.py
(1)运行 spider 程序,非Debug模式,监听消息进行消费
(2)将 job中的 DyLuopanJob().run() 改为具体的方法 DyLuopanJob().add_live_room_task()
(3)运行 add_task.py,消息发送到 redis。spider 进行消费,进入 start_task() 方法

3.5 失败队列处理

dlq 中的失败消息,复制出 body 内容,单独走 Debug 模式断点调试,看失败原因是啥。
然后来完善爬虫程序规避正常的业务场景,或者丢弃无效数据。
四、发布任务到线上服务器
(1)添加自己的 ssh 公钥(id_rsa.pub)到线上服务器 authorized_keys 里面
(2)提交代码到 git 仓库线上分支。
(3)执行同步线上代码
python -m speedy deploy sync-codes
(4)发布任务到服务器并运行
python -m speedy deploy publish -f sites/dy_luopan/deployments.yml
取消任务
python -m speedy deploy unpublish -f sites/dy_luopan/deployments.yml
发布任务后在 rundeck 平台可以看到,这里可以点击按钮主动触发一次任务,及时观察日志,程序运行是否正常。
(5)查看任务运行状态
python -m speedy deploy list-services -f sites/dy_luopan/deployments.yml
确认服务在运行。
(6)登录服务器,在任何路径下可以执行下面的命令,查看爬虫程序的日志
supervisorctl tail -f speedy-sites_dy_luopan-live_room
日志信息如下:
(base) [root@izbp153j8cx9nm5c4a03kzz ~]# supervisorctl tail -f speedy-sites_dy_luopan-live_room
==> Press Ctrl-C to exit <==
] DEBUG: Crawled (200) <POST https://xxx.com/ad/api/data/v1/common/statQuery?reqFrom=xxx&aavid=181xxx62&a_bogus=Dy8hQ5hkdDIivDuf5UKLfY3qV4a3YQol0SVkMDhedd3tpL39HMTz9exow7zvMIubZsQmIebjy4haOpKhrQAy8r6UHuXiWdQ2myuZKl5Q5xSSs1fee6mBnsJx-J44FerM5id3EckMovKGzYuZ09OH-hevPjoja3LkFk6FOoQs> (referer: https://xxx.com/dataV2/roi2-live-analysis)
2025-07-31 18:46:44 [scrapy.extensions.logstats] INFO: Crawled 114519 pages (at 15 pages/min), scraped 0 items (at 0 items/min)
2025-07-31 18:47:44 [scrapy.extensions.logstats] INFO: Crawled 114519 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2025-07-31 18:48:44 [scrapy.extensions.logstats] INFO: Crawled 114519 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2025-07-31 18:49:44 [scrapy.extensions.logstats] INFO: Crawled 114519 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
(7)如有异常,及时关停程序,减小对账号的影响
停止supervisor
python -m speedy deploy stop-services -f sites/dy_luopan/deployments.yml
重新运行supervisor
python -m speedy deploy restart-services -f sites/dy_luopan/deployments.yml
五、规范
● python 非必要注释不需要写;文件名称,抽取的方法,变量等要见名知意。
● spider 的 class 上面空 2 行。
● spider 导入依赖或者其他文件,三方包要写在前面和业务文件空 1 行
● spider 的常量与 task_queue_group 空 1 行,与下面的 def 方法空 1 行
● debug_task 的 body 写法遵循规范
def debug_task(self):body = {'name1': 'value1','name2': 'value2'}return {'body': body}
● start_task 只允许发出一个 Request
● parse 的 yield XxxItem遵循规范update_info = {'nick_name': douyin_name,'aweme_id': douyin_id,'in_living': in_living,'live_id': live_id,'live_title': live_title,'live_room_start_time': item.get("start_time"),'live_duration': item.get("live_duration")}yield DyLiveRoomInfoDataItem(update_info)
● spider 的最后一个方法结束与下面空 2 行
● utils/common 中的 def 方法之间空 2 行
● spider 中的Request属性=符号前后不要空格 yield self.Request(url=url, headers=headers, callback=self.parse_core)
● spider 的start_task中的请求参数param(比如抓取30+数据指标)长的话也不用抽取到 common 中
六、技巧
● 排序查询
此处根据 live_room_start_time 倒序排序
live_list = mysql_crawL_db_session.filter(dy_live_room_info_table,filters=[('>', 'live_room_start_time', start_time),('<', 'live_room_start_time', end_time),('=', 'in_living', '0')],fields=['aweme_id', 'nick_name', 'live_id', 'live_title'],order_by='-live_room_start_time'
)
order_by源码
if self.order_by and not self.count:segs = []for o in self.order_by:if o.startswith('-'):segs.append(six.text_type(o[1:]) + ' DESC')else:segs.append(six.text_type(o))qs += ['ORDER BY {0}'.format(', '.join(segs))]
● 业务流程长的任务可以发送多个 Task
任务会进入队列池,等待消费。
core_body = {**live_base_body,'api_type': 'core_gmv','date_time': datetime.now().strftime('%Y/%m/%d %H:00'),
}
yield self.Task(1, core_body, group='dy_lp_live_core')time_type = '1'
if in_living:time_type = '0'
crowd_body = {**live_base_body,'time_type': time_type
}
yield self.Task(1, crowd_body, group='dy_lp_live_crowd')product_body = {**live_base_body,'in_living': in_living
}
yield self.Task(1, product_body, group='dy_lp_live_product')
● Task 优先级,业务流程长的场景,深度优先的任务,优先级应该设置的比上层高。以便优先处理任务。
yield self.Task(2, product_body, group='dy_lp_live_product')
yield self.Task(1, product_body, group='dy_lp_live_product')
● ItemMode 三种插入模式IGNORE、INSERT、REPLACE
● 普通 json text 结果使用 response.text 接收,下载接口使用 response.body 接收
res_dic = json.loads(response.text)
excel_data = BytesIO(response.body)
● 推荐 yield XxxItem,框架实现批量入库。不推荐自己写 sql
● 自定义 callback parse
start_task 只允许发出一个 Request,多个业务场景可以自定义 callback parse
def start_task(self, task):if not next_spider:yield self.Request(url=self.get_live_room_url, headers=headers)else:yield self.Request(self.get_device_id_url, headers=headers, callback=self.parse_device_id)def parse(self, response):return Nonedef parse_device_id(self, response):return None
● Request 发送 POST 请求
params = {"live_id": live_id}yield self.Request(self.url, method='POST', headers=headers, body=json.dumps(params))
Powered By niaonao