Qwen3 Embedding:新一代文本表征与排序模型
背景
虽然现在可以通过大语言模型、多模态大模型做端到端的任务。但依然存在一些大模型无法直接处理的场景。例如比较常见的 RAG 任务,从海量文档数据中找回目标数据。常用的手段就是多路召回,其中就不乏有基于 Embedding 的稠密召回操作,对于召回的内容总得有一个“相似度”评判,就是一个 Reranking 模型。
预备知识-benchmark
评判 Embedding、Reranker 模型的性能效果的 benchmark 主要有:
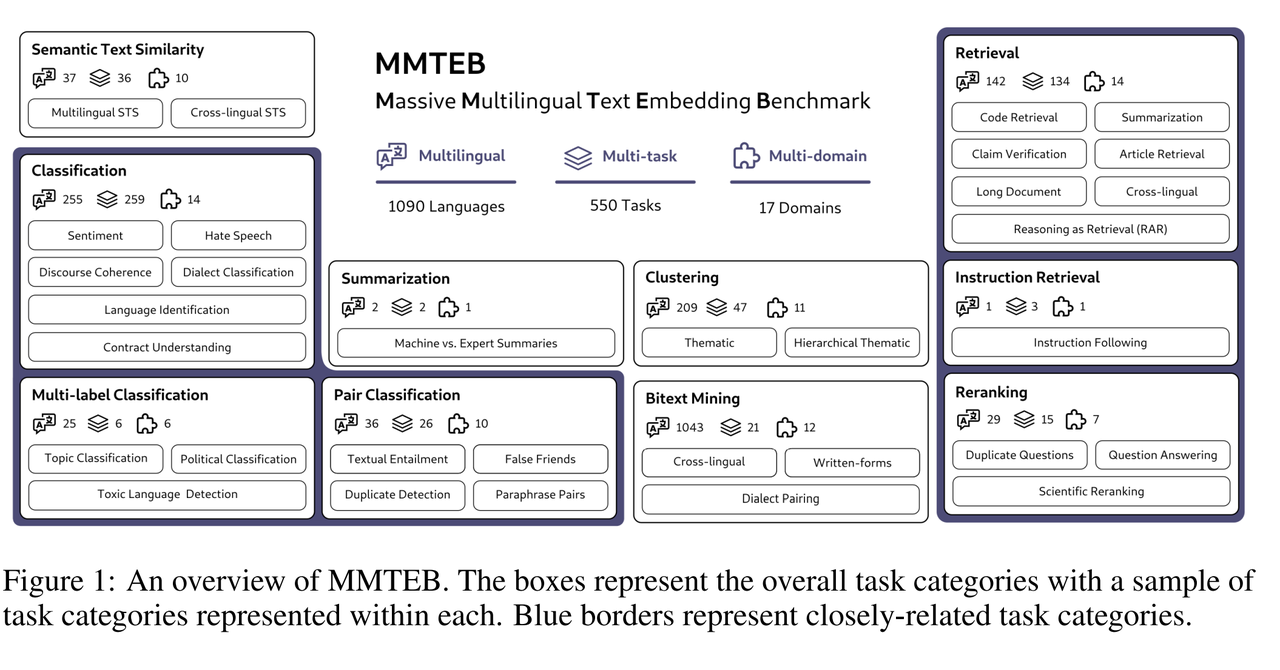
- MMTEB(Massive Multilingual Text Embedding Benchmark). 相关论文介绍:MMTEB: Massive Multilingual Text Embedding Benchmark:
- C-MTEB(Chinese Massive Text Embedding Benchmark). 相关论文: