2-5 Dify案例实践—利用RAG技术构建企业私有知识库
目录
一、RAG技术的定义与作用
二、RAG技术的关键组件
三、RAG技术解决的问题
四、RAG技术的核心价值与应用场景
五、如何实现利用RAG技术构建企业私有知识库
六、Dify知识库实现详解
七、创建知识库
1、创建知识库
2、上传文档
3、文本分段与清洗
4、索引方式
5、Embedding 模型
6、检索设置
八、构建应用并关联知识库
1、创建空白应用
2、关联知识库
3、引用和归属
4、知识召回
RAG(Retrieval-Augmented Generation,检索增强生成)技术是一种将检索模型与生成模型结合的架构,旨在通过引用外部知识库的信息来生成答案或内容,提升生成答案或内容的准确性和专业性,以下是对RAG技术的详细解析:
一、RAG技术的定义与作用
RAG技术通过从外部知识库中实时检索相关信息,动态补充大模型的输入数据。这种技术结合了信息检索(Retrieval)与生成模型(Generation)的优势,构建了“先检索、再生成”的闭环逻辑,从而提升了生成内容的准确性和专业性。其核心机制在于利用检索模块从海量文档中精准找到与问题紧密相关的证据性内容,并将这些信息作为生成模型的上下文输入,进而生成既符合语境又紧扣真实信息的回答。
二、RAG技术的关键组件
-
知识库:存储结构化或非结构化数据,如企业文档、法律条文等,作为检索模块的信息来源。
-
向量数据库:将文本转化为向量表征,实现高效的语义检索。向量数据库支持基于语义相似性的快速精准检索,能够大幅提升RAG系统的效率。
-
生成器:基于检索到的上下文信息生成最终回答。生成器通常是一个强大的生成模型,能够充分利用外部知识库中的信息,生成连贯、准确且信息详实的文本内容。
三、RAG技术解决的问题
-
知识局限性:RAG技术能够弥补大模型训练数据的滞后性,通过实时检索外部知识库,使生成内容能够反映最新的信息和知识。
-
生成可控性:通过引用可追溯的外部知识源,RAG技术提高了结果的透明度和可信度,使用户更容易理解生成结果的来源和依据。
-
隐私与安全:RAG技术通过本地知识库隔离敏感数据,避免敏感信息直接输入大模型,从而降低了数据泄露的风险。
-
成本效率:相比全量微调模型,RAG技术显著降低了领域知识适配的成本,使模型能够更快速地适应新的知识和场景。
四、RAG技术的核心价值与应用场景
-
企业知识管理:RAG技术可用于构建私有化知识库,如法律咨询中即时检索最新法规辅助生成法律意见,提高知识管理的效率和准确性。
-
实时信息整合:通过联网检索,RAG技术能够补充最新数据,如市场动态、新闻资讯等,使生成内容更加时效和有价值。
-
专业领域增强:在医疗、金融等需要高准确性的领域,RAG技术能够确保生成内容符合专业规范,提高决策的准确性和可靠性。
-
高并发优化:通过向量数据库的水平扩展,RAG技术能够支持大规模并发检索,满足高并发场景下的需求。
五、如何实现利用RAG技术构建企业私有知识库
要实现利用RAG技术构建企业私有知识库,可以按照以下步骤进行:
-
准备知识库:收集并整理企业内部的文档、数据等信息,构建结构化或非结构化的知识库。
-
构建向量数据库:将知识库中的文本转化为向量表征,并存储在向量数据库中,以便进行高效的语义检索。
-
集成检索与生成模块:将检索模块和生成模块集成到企业知识管理系统中,实现“先检索、再生成”的功能。
-
优化与调整:根据实际需求对RAG系统进行优化和调整,如改进分块策略、向量匹配算法等,以提高系统的性能和准确性。
综上所述,RAG技术通过结合检索和生成技术的优势,实现了对外部知识库信息的有效利用,为企业知识管理、实时信息整合、专业领域增强等场景提供了有力的支持。
六、Dify知识库实现详解
Dify知识库作为文档集合的核心功能,通过整合多种文档类型和自动化处理流程,实现了高效的检索增强生成(RAG)流水线。
-
知识库基础概念: Dify知识库由数据集构成,每个数据集包含多个文档(如文本、表格等),可直接集成到AI应用中作为检索上下文使用。知识库通过RAG技术让大语言模型在生成回答前,先从可控的知识源中检索相关信息,提升准确性和实用性。
-
RAG流水线可视化: Dify提供用户友好的界面,支持RAG流水线各环节的可视化管理,包括文档上传、分段清洗、嵌入向量存储和元数据设置。整个流程可简化到几分钟内完成,开发者无需代码即可构建应用。例如:
-
上传文档后,系统自动分段并清洗内容。
-
提交至LLM供应商嵌入为向量数据存储。
-
为文档设置元数据便于后续检索。
-
-
支持的数据格式: Dify兼容多种源数据格式,确保灵活适配各类业务需求。具体包括:
-
长文本内容:TXT、Markdown、DOCX、HTML、JSON、PDF(单文件上限通常为15MB)。
-
结构化数据:CSV、Excel,支持表格数据的导入与转换。
此外,Dify支持从外部数据源(如Notion)导入文档,并实现自动同步更新
-
-
模型集成关键要求: 为保障私有知识库效果,必须结合embedding模型和reranker模型优化检索精度。在Dify中,需通过以下步骤启用:
-
在设置中选择模型供应商(如OpenAI或本地模型)。
-
配置embedding模型处理向量转换,并引入reranker模型优化相关度排序。
-
将模型API密钥集成至工作流,确保RAG管道高效运行。
-
注:私有知识库要达到良好的效果,必须与embedding模型和reranker模型相结合,请在xinterface中启⽤相关模型并引⼊Dify
七、创建知识库
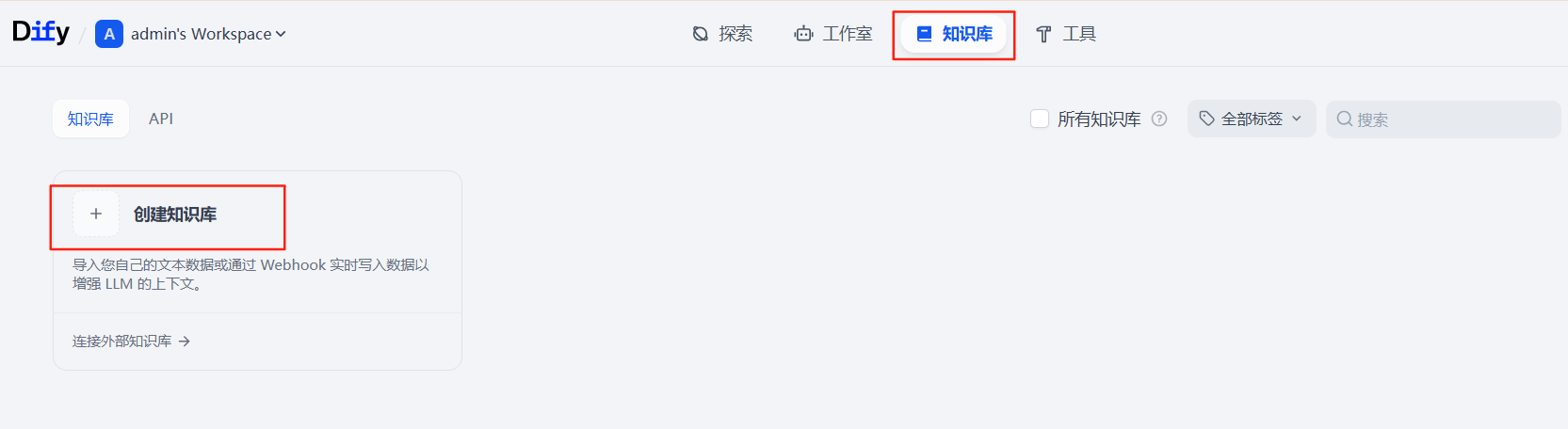
1、创建知识库
点击「知识库」→「新建知识库」
2、上传文档
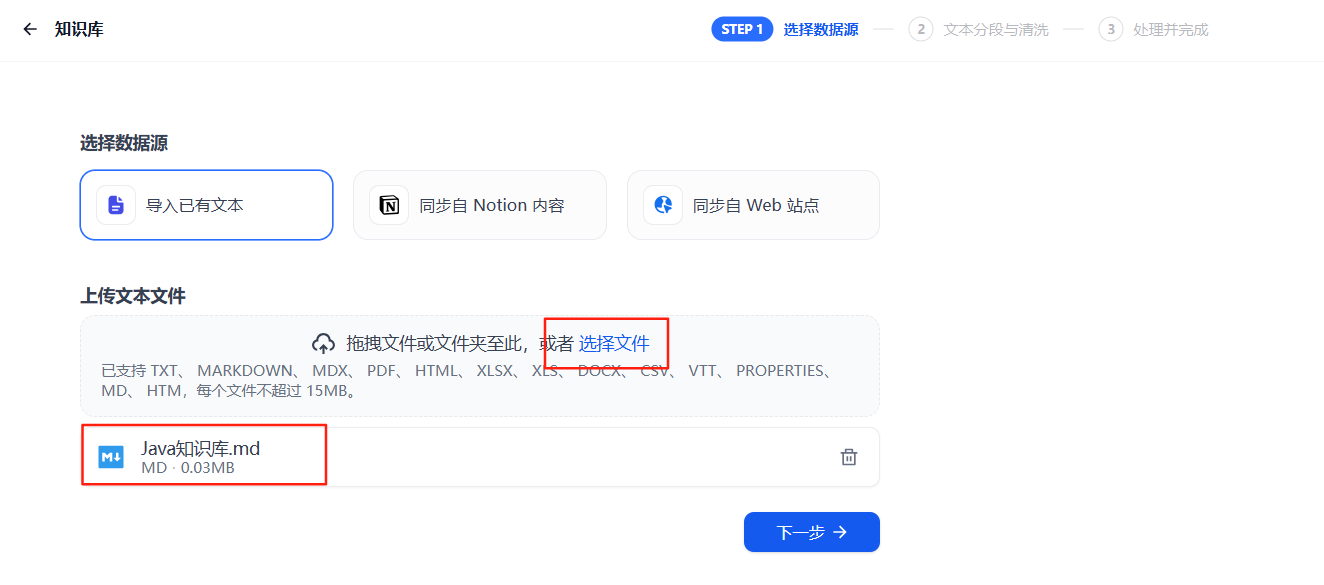
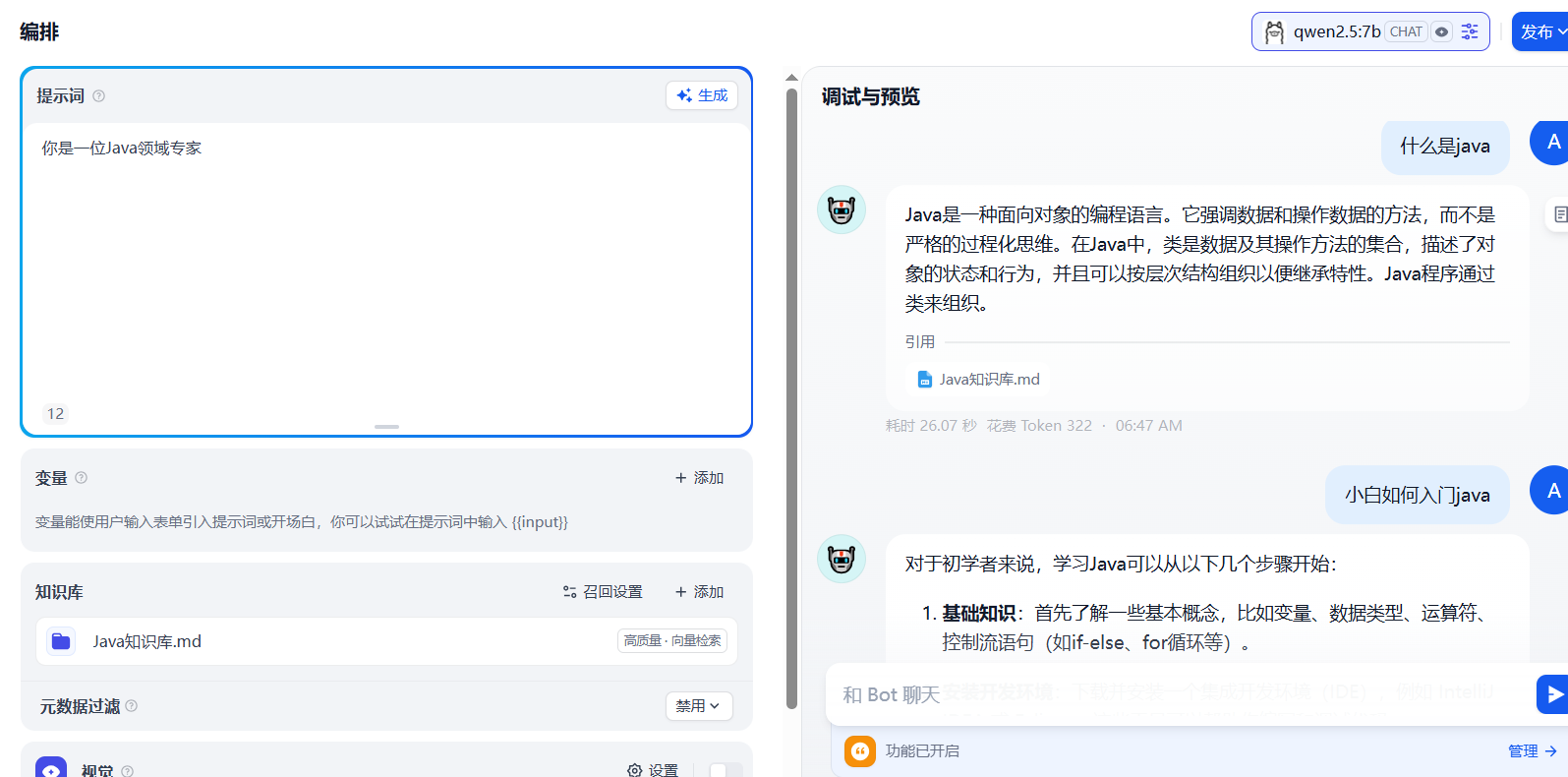
选择本地文件(如《Java知识库.md》)导入,点击“下一步”。支持HTML、文本、PDF等格式,文件上传后进入分段处理环节。
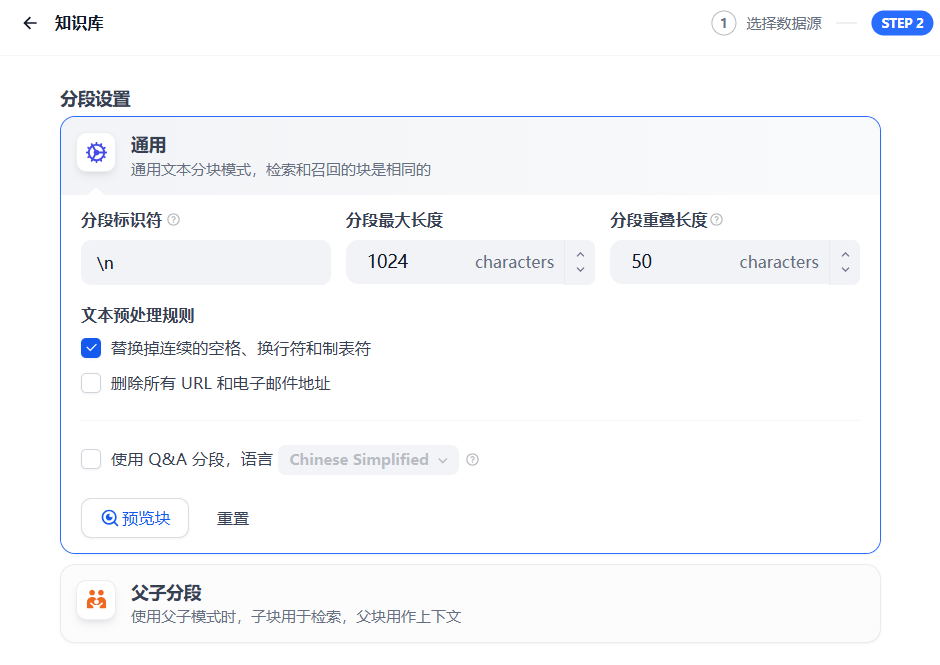
3、文本分段与清洗
-
分段:大语言模型受上下文窗口限制,需将文本切分为合适段落(建议256–512 tokens),通过分段Top-K召回提升语义匹配精度。
-
清洗:去除冗余字符或空行以减少噪声,Dify内置多类清洗方法优化输出质量。
关键操作:勾选“问答分段”可启用Q2Q(问题匹配问题)模式,直接关联用户提问与预定义问题,显著提升答案相关性
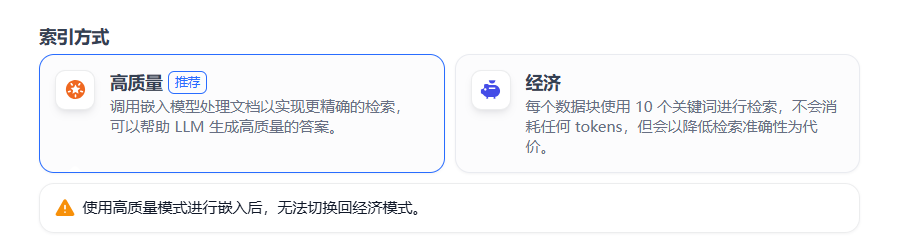
4、索引方式
选择文本索引策略以适配检索需求,例如:
-
关键词索引:适用于精确术语匹配。
-
向量索引:支持语义相似度搜索。 索引策略需与实际场景结合设计
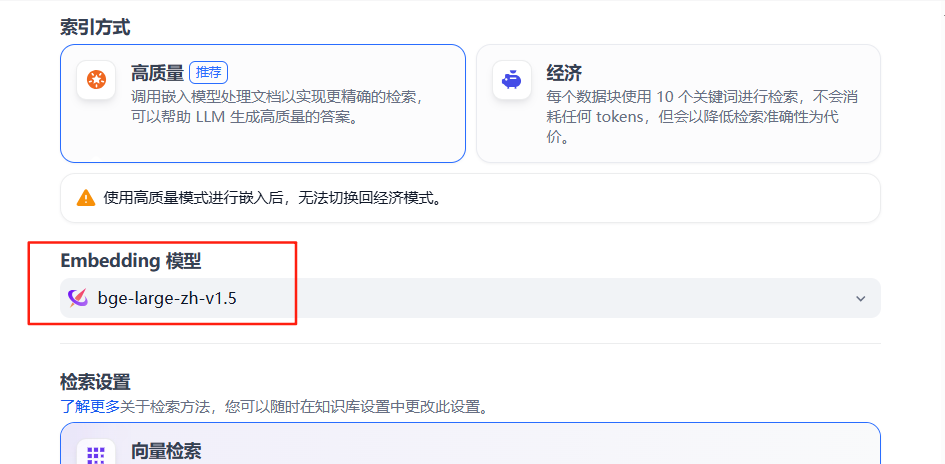
5、Embedding 模型
配置Embedding模型(如bge-large-zh-v1.5),将文本转换为向量表示,直接影响语义召回效果。需根据模型默认Token上限(如500 tokens)调整分段大小。
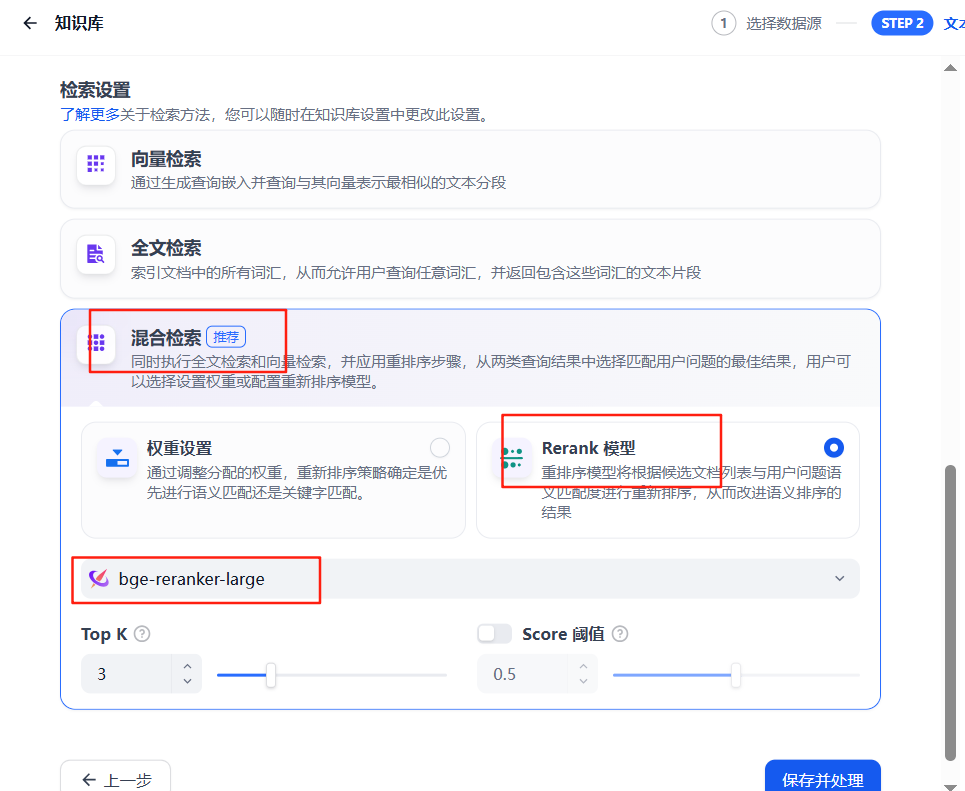
6、检索设置
启用“混合检索”结合关键词与语义匹配,设置参数(如TOP-K值、分数阈值)后点击“保存并处理”。
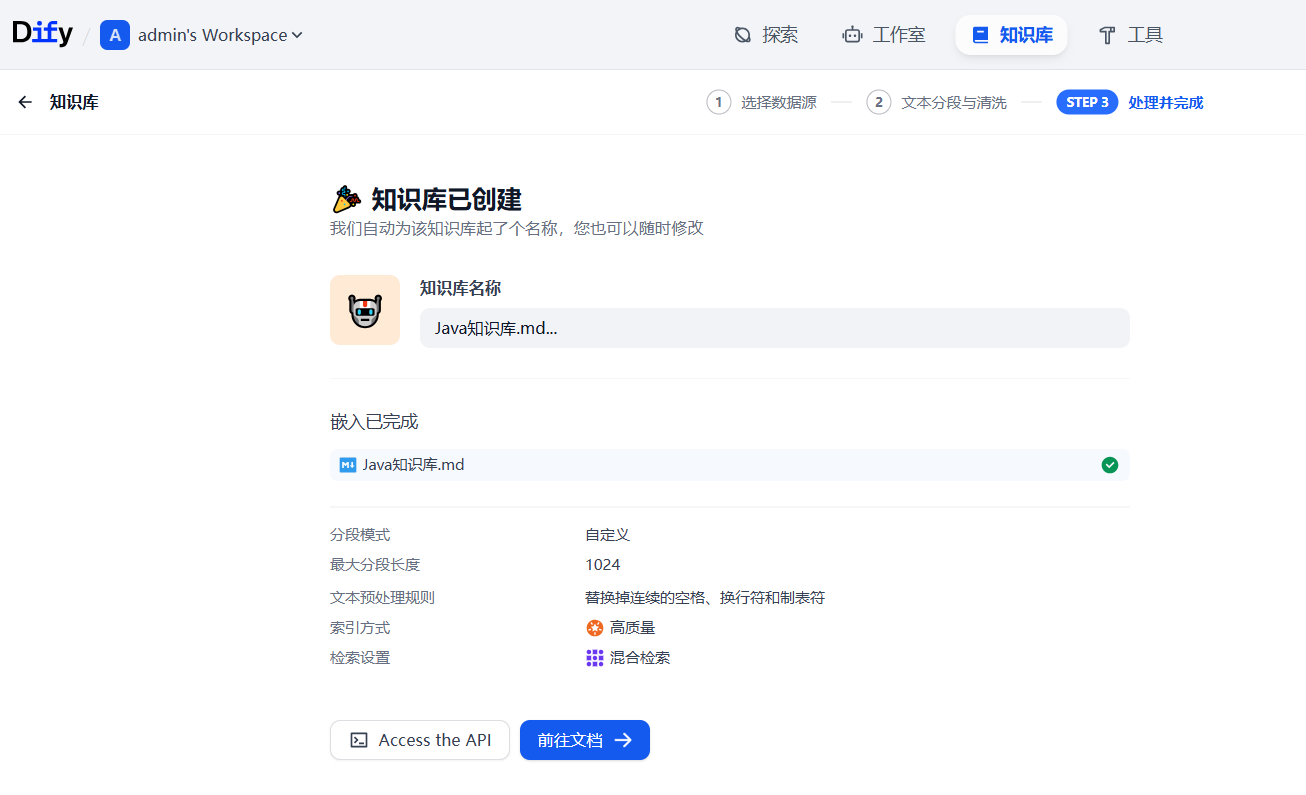
至此,知识库创建已完成,接下来构建应用并关联知识库。
八、构建应用并关联知识库
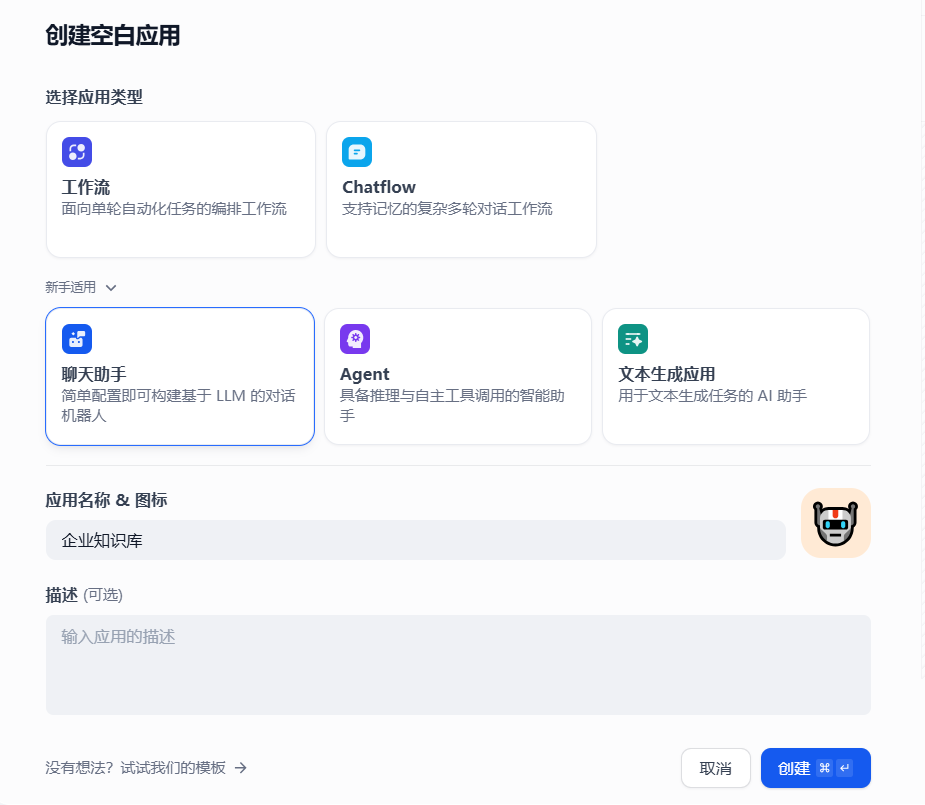
1、创建空白应用
2、关联知识库
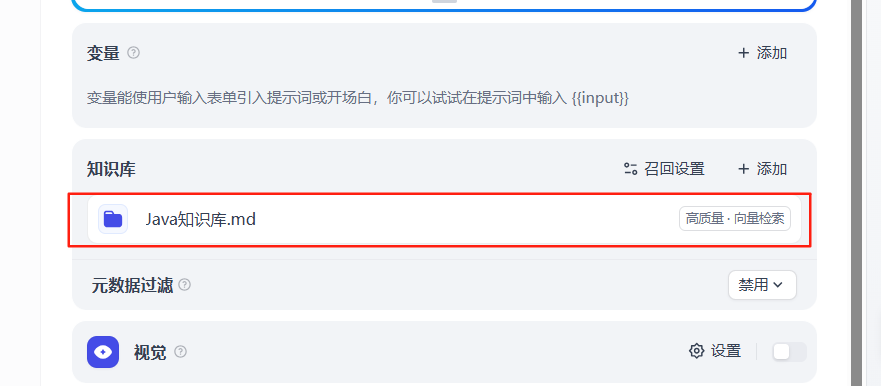
3、引用和归属
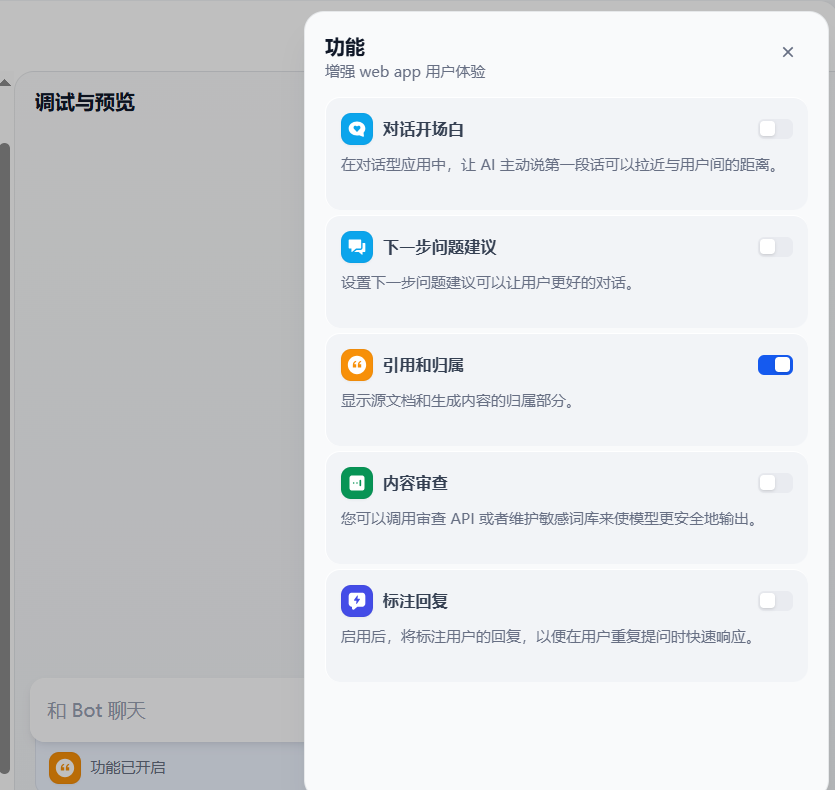
4、知识召回
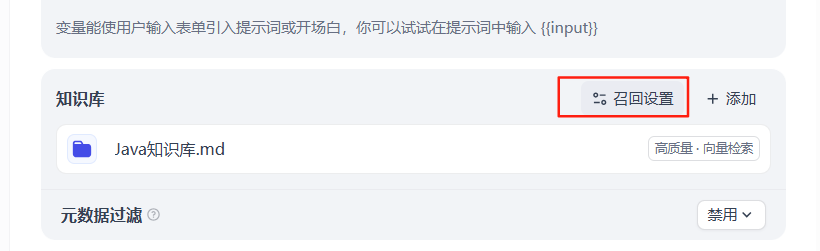
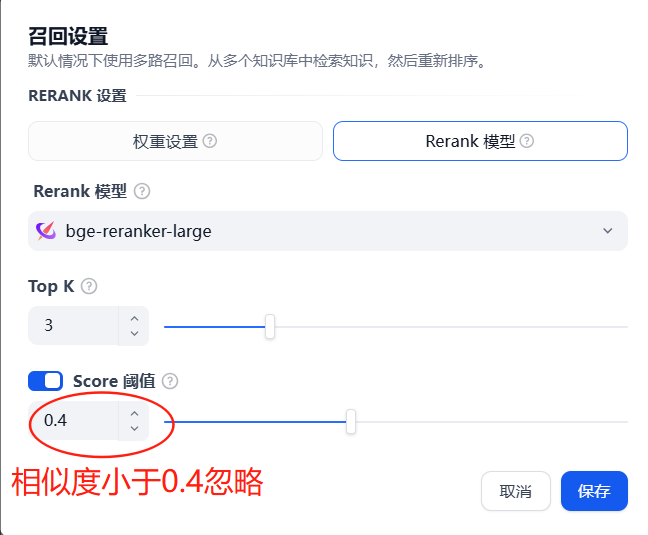
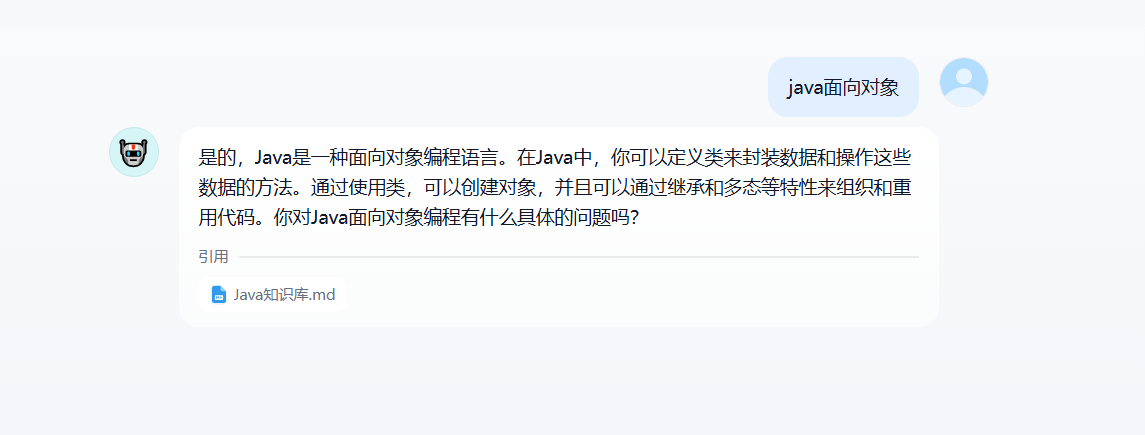
效果演示:
👉 Docker部署Dify详细教程
👉 Docker部署Xinference详细教程
👉 Ollama安装详细教程